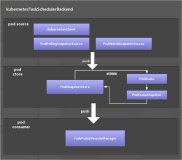
Nova-Scheduler主要完成虚拟机实例的调度分配任务,创建虚拟机时,虚拟机该调度到哪台物理机上,迁移时若没有指定主机,也需要经过scheduler。资源调度是云平台中的一个很关键问题,如何做到资源的有效分配,如何满足不同情况的分配方式,这些都需要nova-scheduler来掌控,并且能够很方便的扩展更多的调度方法,可能我需要虚拟机调度到空闲的机器,可能还需要将某类型的虚拟机调度到固定的机架等等,现在就来看看Nova-Scheduler是如何完成调度任务的。
Scheduler启动后,相应的MQ结构如下:
Exchange(nova,topic) <--- <routing_key:scheduler>---Queue(scheduler) ---> Consumer(scheduler) Exchange(nova,topic) <---<routing_key:scheduler.controller>---Queue(scheduler.controller) ---> Consumer(scheduler.controller) Exchange(scheduler_fanout,fanout) <---<routing_key:scheduler>---Queue(scheduler_fanout_xxx)--->Consumer(scheduler_fanout_xxx)
一、服务启动
Nova-scheduler 服务的启动入口脚本是 cmd 包下的 scheduler.py ,其主要监听来自于消息队列中 topic=scheduler( 可配置 ) 的消息。在服务启动过程中,其将初始化一个 SchedulerManager 实例作为该服务的 Handler ,来处理接受到的消息请求。
同时, Nova-scheduler 服务在启动的过程中,会将自己注册到 DB 中,即将自己的 host 、 binary 、 topic 、 report_count 信息添加到 services 表中,并将自己同样注册到 ServiceGroup 服务中,默认是 DBServiceGroup 服务,并定时向ServiceGroup 服务发送心跳,其本质上就是定时地更新 services 表中的report_count 字段。另, ServiceGroup 服务还有基于 MC 、 ZK 两种实现方式。
二、主要源码说明
1 、 manager.py :
SchedulerManager 类主要来处理服务接收的消息,目前主要的操作就是live_migration 、
run_instance 、 prep_resize 、 select_hosts 、 select_destinations ,后两者将要 deprecated 。这些操作本质上还是要依赖于具体的 SchedulerDriver 去完成。
另外, _SchedulerManagerV3Proxy 类与 SchedulerManager 类主要的区别在于消息版本的不同,
_SchedulerManagerV3Proxy 消息是 3.0 版本,而 SchedulerManager 是 2.9 版本。
2 、 driver.py 、 chance.py 、 filter_scheduler.py 、 caching_scheduler.py :
Scheduler 类是所有 SchedulerDriver 类的基类,其定义了关键的接口协议。目前主要有 ChanceScheduler 、 FilterScheduler 和 CachingScheduler 三种实现方式,具体说明如下:
1 ) ChanceScheduler :随机选择一台物理机,前提是该物理机上的 nova-compute 服务正常且该物理机不在指定的 ignore_hosts 列表中。
2 ) FilterScheduler :筛选出能通过整个过滤器链的物理机,然后根据相应指标计算权重,并进行排序,最后返回一个 best host 。具体过滤器详见下文。
3 ) CachingScheduler : FilterScheduler 的子类,在 FilterScheduler 的基础上将 host 资源信息缓存在了本地内存中,然后通过后台定时任务定时从 DB 中拉取最新的 host 资源信息。在多节点环境下存在问题。
3 、 host_manager.py :HostState :表示物理机的资源信息集合,比如当前可用内存、已用内存、虚拟机数量、任务数量、 io 负载、可用磁盘、已用磁盘等等,以及一些更新方法。
HostManager :该类是最重要的 host 筛选类,其内部主要有三个关键函数:
get_filtered_hosts :返回经过层层过滤器筛选后的 host 列表,其依赖于FilterHandler
get_weighed_hosts :返回经过权重计算排序后的 host 列表,其依赖于WeightHandler
get_all_host_states :获取当前最新的 host 资源列表。
4 、 filters :
这里是全部的各种 filter 的实现方式,主要有:
1 ) __init__.py :
BaseHostFilter :继承自 BaseFilter ,是所有具体 Filter 子类的基类,其中一个较重要的成员变量 run_filter_once_per_request 表示该 Filter 子类是否在在一次 request 中仅执行一次。
HostFilterHandler :最重要的函数 get_filtered_objects , load 指定的filter_classes ,层层过滤
host ,最后返回符合所有过滤条件的 host 列表。
2 )剩余就是很多个不同的具体 Filter 子类的实现,基于各自不同的策略,具体暂不一一介绍。
5 、 weights :
1 ) __init__.py :BaseHostWeigher :继承自 BaseWeigher ,是所有具体 Weigher 子类的基类,其中主要的函数就是 _weigh_object ,由具体子类实现,完成对目标 host 列表权重的计算与排序,具体策略见下文。
HostWeightHandler :最重要的函数 get_weighed_objects , load 指定的weigher_classes ,层层依据各自指标对目标 host 列表进行权重计算,最后排序后返回。
2 ) ram.py :RAMWeigher :基于剩余可用内存进行权重计算排序。
3 ) metrics.py :MetricsWeigher :支持自定义一些指标进行权重计算排序。
三、流程与算法说明
1 、这里主要是基于 FilterScheduler 来说明下在 Scheduler 服务中创建虚拟机(包括筛选物理机)的流程(其他流程同理):
1 )当 nova-scheduler 服务从 MQ 中接收到 run_instance 消息时,则由SchedulerManager 类对其进行处理,执行 run_instance 函数。
2 ) SchedulerManager 将具体逻辑交由具体的 SchedulerDriver 执行,这里就是 FilterScheduler 。
3 ) FilterScheduler 接收到请求后,开始进行 host 筛选,选择出 instance_num个目标 host 。
4 )首先判断这次 request 的 retry 次数是否已经达到 max_attempts 次,若达到,则停止 retry ,抛出 NoValidHost 异常;若是第一次,则设置 filter_properties 属性 retry={num_attempts:1,hosts:[]} ;否则继续执行。
5 )然后从 DB 中获取当前最新的 compute node 节点资源信息,并更新本地内存 缓存 中的 host 列表资源数据。这里的好处是当一次批量申请多个虚拟机时,可以避免多次请求DB ,但是一个不容忽视的问题就是如果多个 Scheduler 服务并行部署时,就会因资源信息的延迟不同步而导致虚拟机创建失败(实际后台 host 已不足)。
6 )再次开始循环为每个 instance 筛选目标 host :首先根据指定的ignore_hosts 、 force_hosts 、force_nodes 属性对候选 hosts 列表进行筛选,留下符合这些属性条件的 hosts。
7 )然后根据配置指定的 filter 来循环层层过滤 6 )中的候选 hosts ,具体代码如下:
def get_filtered_objects(self, filter_classes, objs,filter_properties, index=0):
list_objs = list(objs) LOG.debug(_("Starting with %d host(s)"), len(list_objs)) for filter_cls in filter_classes: cls_name = filter_cls.__name__ filter = filter_cls() if filter.run_filter_for_index(index): objs = filter.filter_all(list_objs,filter_properties) if objs is None: LOG.debug(_("Filter %(cls_name)s says to stop filtering"), {'cls_name': cls_name}) return list_objs = list(objs) if not list_objs: LOG.info(_("Filter %s returned 0 hosts"), cls_name) break LOG.debug(_("Filter %(cls_name)s returned %(obj_len)d host(s)"), {'cls_name': cls_name, 'obj_len': len(list_objs)}) return list_objs
8 )在 7 )中筛选的这批 hosts 此时可以认为是满足该 instance 的资源要求,然后开始对这批hosts 根据配置的各个 Weigher 子类进行权重计算并排序,具体如下:
def get_weighed_objects(self, weigher_classes, obj_list,weighing_properties):
"""Return a sorted (descending), normalized list of WeighedObjects.""" if not obj_list: return [] weighed_objs = [self.object_class(obj, 0.0) for obj in obj_list] for weigher_cls in weigher_classes: weigher = weigher_cls() weights = weigher.weigh_objects(weighed_objs, weighing_properties) # Normalize the weights weights = normalize(weights,minval=weigher.minval,maxval=weigher.maxval) for i, weight in enumerate(weights): obj = weighed_objs[i] obj.weight += weigher.weight_multiplier() * weight return sorted(weighed_objs, key=lambda x: x.weight, reverse=True)
9 )从 8 )中根据权重排序后的 hosts 取出 scheduler_host_subset_size (默认是 1 )个 host ,表明未来该 instance 会落在该 host 上,并 预扣掉该 host 的剩余可用资源 (注意这里仅仅是修改的本地缓存中 host 资源信息)。
10 )在为每个 instance 选择好候选目标 host 后,开始循环创建虚拟机:更新instance 表( host,node,scheduled_at ),并向 nova-compute 服务发送 rpc 请求。
11 ) nova-compute 服务接收到创建虚拟机请求后:首先将 DB 中 instance状态设置为vm_state=BUILDING , task_state=SCHEDULING 。
12 )然后获取该 node 的 ResourceTracker 实例(其主要是维护跟踪该 node 的资源明细),claim 将要预留资源信息,设置 mac 和 network 信息,最后开始构建虚拟机。期间在不同的 task 阶段,会相应更新 DB 中 vm_state 和 task_state 状态。
13 )若创建虚拟机流程中发生错误,会重新向 MQ 发送创建虚拟机请求,此时nova-scheduler服务会继续处理该消息,则继续回到 1 )步骤。
2 、下图展示了整个调度过程的大体流程:

这里主要说明下各个 host 的权重是如何计算出来的,大体公式如下:

host_weight = Weigher1_multiplier * Weigher1_host_weight+……+ WeigherN_multiplier
* WeigherN_host_weight
举例说明:
假若有 6 台候选 Host : H1 , H2 , H3 , H4 , H5 , H6
3 个 Weigher : W1 , W2 , W3 ,且其 multiplier 分别为 1 , 2 , 1
具体一个 Weigher 如何计算出一个 Host 在该 Weigher 的权重,则依赖各个Weigher 自己的
实现,比如 RAMWeigher 则是以每个 Host 的 free_ram_mb 作为其原生权重。
1 )假若 H1~H6 经过 W1 计算后的原生权重值如下:
| W(multiplier) |
H1 |
H2 |
H3 |
H4 |
H5 |
H6 |
| W1 (1) |
50 |
10 |
20 |
10 |
90 |
110 |
然后需要对这些原始权重值进行 normalize 化,具体方式是:找出这些原始权重值中的
最大值 max_weight 和最小值 min_weight ,然后按照如下公式来计算其比例权重值:
ratio_weight = ( raw_weight - min_weight ) / ( max_weight - min_weight )
那么 H1~H6 原生权重 W1 normalize 化之后 (ratio_weight) :
| W(multiplier) |
H1 |
H2 |
H3 |
H4 |
H5 |
H6 |
| W1 (1) |
0.4 |
0 |
0.1 |
0 |
0.8 |
1 |
2 )假若 H1~H6 经过 W2 计算后的原生权重值如下:
| W(multiplier) |
H1 |
H2 |
H3 |
H4 |
H5 |
H6 |
| W1 (1) |
0.4 |
0 |
0.1 |
0 |
0.8 |
1 |
| W2 (2) |
10 |
4 |
6 |
11 |
1 |
9 |
那么 H1~H6 原生权重 W2 normalize 化之后 (ratio_weight) :
| W(multiplier) |
H1 |
H2 |
H3 |
H4 |
H5 |
H6 |
| W1 (1) |
0.4 |
0 |
0.1 |
0 |
0.8 |
1 |
| W2 (2) |
0.9 |
0.3 |
0.5 |
1 |
0 |
0.8 |
3 )假若 H1~H6 经过 W3 计算后的原生权重值如下:
| W(multiplier) |
H1 |
H2 |
H3 |
H4 |
H5 |
H6 |
| W1 (1) |
0.4 |
0 |
0.1 |
0 |
0.8 |
1 |
| W2 (2) |
0.9 |
0.3 |
0.5 |
1 |
0 |
0.8 |
| W3 (1) |
15 |
25 |
10 |
5 |
10 |
5 |
那么 H1~H6 原生权重 W3 normalize 化之后 (ratio_weight) :
| W(multiplier) |
H1 |
H2 |
H3 |
H4 |
H5 |
H6 |
| W1 (1) |
0.4 |
0 |
0.1 |
0 |
0.8 |
1 |
| W2 (2) |
0.9 |
0.3 |
0.5 |
1 |
0 |
0.8 |
| W3 (1) |
0.5 |
1 |
0.25 |
0 |
0.25 |
0 |
4 )最后得出 H1~H6 的最终权重为:
| W(multiplier) |
H1 |
H2 |
H3 |
H4 |
H5 |
H6 |
| W1 (1) |
0.4 |
0 |
0.1 |
0 |
0.8 |
1 |
| W2 (2) |
0.9 |
0.3 |
0.5 |
1 |
0 |
0.8 |
| W3 (1) |
0.5 |
1 |
0.25 |
0 |
0.25 |
0 |
| ratio_weights |
2.7 |
1.6 |
1.35 |
2 |
1.05 |
2.6 |
5 )最后对 H1~H6 的 ratio_weight 进行降序排序,那么这次 Host 的排序则为H1 , H6 , H4 , H2 , H3 , H5
3 、 nova-scheduler 与 nova-compute 之间是如何知道具体 host 资源的详情的?
1 )每当 nova-compute 服务起来之后,会自动更新 DB 中对应 compute_node的资源信息,若是第一次,则会将自己添加到 compute_node 中;并同时会将这些资源信息缓存在本地内存中,并由一个 ResourceTracker 实例进行跟踪。
2 )每次 nova-compute 服务接收到创建虚拟机的申请时,通过ResourceTracker 进行instance_claim 时,会将这次申请所需要扣除的虚拟机资源大小及时反映到compute node 中,同时更新本地 ResourceTracker 中的缓存信息。
3 ) nova-scheduler 每次在接收到创建虚拟机请求时,都会从 compute node中取出最新的 host 资源信息,被暂时缓存在本地内存中,当成功选择出一台 host 时,会及时扣除本地缓存相应的 host 资源信息。
本文转自feisky博客园博客,原文链接:http://www.cnblogs.com/feisky/p/3875361.html,如需转载请自行联系原作者