1.概述
上一篇博客,讲述Hadoop V2的序列化机制,这为我们学习Hadoop V2的RPC机制奠定了基础。RPC的内容涵盖的信息有点多,包含Hadoop的序列化机制,RPC,代理,NIO等。若对Hadoop序列化不了解的同学,可以参考《Hadoop2源码分析-序列化篇》。今天这篇博客为大家介绍的内容目录如下:
- RPC概述
- 第三方RPC
- Hadoop V2的RPC简述
那么,下面开始今天的学习之路。
2.RPC概述
首先,我们要弄明白,什么是RPC?RPC能用来做什么?
2.1什么是RPC
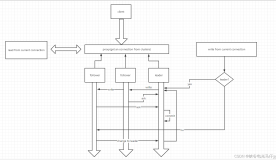
RPC的全程是Remote Procedure Call,中文释为远程过程调用。也就是说,调用的过程代码(业务服务代码)并不在调用者本地运行,而是要实现调用着和被调用着之间的连接通信,有同学可 能已经发现,这个和C/S模式很像。没错,RPC的基础通信模式是基于C/S进程间相互通信的模式来实现的,它对Client端提供远程接口服务,其 RPC原理图如下所示:

2.2RPC的功能
我们都知道,在过去的编程概念中,过程是由开发人员在本地编译完成的,并且只能局限在本地运行的某一段代码,即主程序和过程程序是一种本地调用 关系。因此,这种结构在如今网络飞速发展的情况下已无法适应实际的业务需求。而且,传统过程调用模式无法充分利用网络上其他主机的资源,如CPU,内存 等,也无法提高代码在Bean之间的共享,使得资源浪费较大。
而RPC的出现,正好有效的解决了传统过程中存在的这些不足。通过RPC,我们可以充分利用非共享内存的机器,可以简便的将应用分布在多台机器上,类似集群分布。这样方便的实现过程代码共享,提高系统资源的利用率。减少单个集群的压力,实现负载均衡。
3.第三方RPC
在学习Hadoop V2的RPC机制之前,我们先来熟悉第三方的RPC机制是如何工作的,下面我以Thrift框架为例子。
Thrift是一个软件框架,用来进行可扩展且跨语言的服务开发协议。它拥有强大的代码生成引擎,支持 C++,Java,Python,PHP,Ruby等编程语言。Thrift允许定义一个简单的定义文件(以.thirft结尾),文件中包含数据类型和 服务接口。用以作为输入文件,编译器生成代码用来方便的生成RPC客户端和服务端通信的编程语言。具体Thrift安装过程请参考《Mac OS X 下搭建thrift环境》。
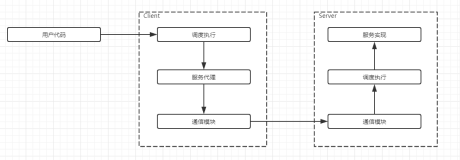
3.1Thrift原理图
下面给出Thrift的原理图,如下所示:
下面为大家解释一下上面的原理图,首先,我们编译完thrift定义文件后(这里我使用的是Java语言),会生成对应的Java类文件,该类 的Iface接口定义了我们所规范的接口函数。在服务端,实现Iface接口,编写对应函数下的业务逻辑,启动服务。客户端同样需要生成的Java类文 件,以供Client端调用相应的接口函数,监听服务端的IP和PORT来获取连接对象。
3.2代码示例
- Server端代码:
package cn.rpc.main;
import org.apache.thrift.TProcessorFactory;
import org.apache.thrift.protocol.TCompactProtocol;
import org.apache.thrift.server.THsHaServer;
import org.apache.thrift.server.TServer;
import org.apache.thrift.transport.TFramedTransport;
import org.apache.thrift.transport.TNonblockingServerSocket;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import cn.rpc.service.StatQueryService;
import cn.rpc.service.impl.StatQueryServiceImpl;
/**
* @Date Mar 23, 2015
*
* @Author dengjie
*/
public class StatsServer {
private static Logger logger = LoggerFactory.getLogger(StatsServer.class);
private final int PORT = 9090;
@SuppressWarnings({ "rawtypes", "unchecked" })
private void start() {
try {
TNonblockingServerSocket socket = new TNonblockingServerSocket(PORT);
final StatQueryService.Processor processor = new StatQueryService.Processor(new StatQueryServiceImpl());
THsHaServer.Args arg = new THsHaServer.Args(socket);
/*
* Binary coded format efficient, intensive data transmission, The
* use of non blocking mode of transmission, according to the size
* of the block, similar to the Java of NIO
*/
arg.protocolFactory(new TCompactProtocol.Factory());
arg.transportFactory(new TFramedTransport.Factory());
arg.processorFactory(new TProcessorFactory(processor));
TServer server = new THsHaServer(arg);
server.serve();
} catch (Exception ex) {
ex.printStackTrace();
}
}
public static void main(String[] args) {
try {
logger.info("start thrift server...");
StatsServer stats = new StatsServer();
stats.start();
} catch (Exception ex) {
ex.printStackTrace();
logger.error(String.format("run thrift server has error,msg is %s", ex.getMessage()));
}
}
}- Client端代码:
package cn.rpc.test;
import java.util.Map;
import org.apache.thrift.protocol.TCompactProtocol;
import org.apache.thrift.protocol.TProtocol;
import org.apache.thrift.transport.TFramedTransport;
import org.apache.thrift.transport.TSocket;
import org.apache.thrift.transport.TTransport;
import cn.rpc.service.StatQueryService;
/**
* @Date Mar 23, 2015
*
* @Author dengjie
*
* @Note Test thrift client
*/
public class StatsClient {
public static final String ADDRESS = "127.0.0.1";
public static final int PORT = 9090;
public static final int TIMEOUT = 30000;
public static void main(String[] args) {
if (args.length < 4) {
System.out.println("args length must >= 4,current length is " + args.length);
System.out.println("<info>****************</info>");
System.out.println("ADDRESS,beginDate,endDate,kpiCode,...");
System.out.println("<info>****************</info>");
return;
}
TTransport transport = new TFramedTransport(new TSocket(args[0], PORT, TIMEOUT));
TProtocol protocol = new TCompactProtocol(transport);
StatQueryService.Client client = new StatQueryService.Client(protocol);
String beginDate = args[1]; // "20150308"
String endDate = args[2]; // "20150312"
String kpiCode = args[3]; // "login_times"
String userName = "";
int areaId = 0;
String type = "";
String fashion = "";
try {
transport.open();
Map<String, String> map = client.queryConditionDayKPI(beginDate, endDate, kpiCode, userName, areaId, type,
fashion);
System.out.println(map.toString());
} catch (Exception e) {
e.printStackTrace();
} finally {
transport.close();
}
}
}- StatQueryService类:
这个类的代码量太大,暂不贴出。需要的同学请到以下地址下载。
下载地址:git@gitlab.com:dengjie/Resource.git
- StatQueryServiceImpl类:
下面实现其中一个函数的内容,代码如下所示:
package cn.rpc.service.impl;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.thrift.TException;
import cn.rpc.conf.ConfigureAPI;
import cn.rpc.dao.KpiDao;
import cn.rpc.domain.ReportParam;
import cn.rpc.domain.ReportResult;
import cn.rpc.service.StatQueryService;
import cn.rpc.util.MapperFactory;
/**
* @Date Mar 23, 2015
*
* @Author dengjie
*/
public class StatQueryServiceImpl implements StatQueryService.Iface {
public Map<String, String> queryDayKPI(String beginDate, String endDate, String kpiCode) throws TException {
return null;
}
public Map<String, String> queryConditionDayKPI(String beginDate, String endDate, String kpiCode, String userName,
int areaId, String type, String fashion) throws TException {
Map<String, String> res = new HashMap<String, String>();
ReportParam param = new ReportParam();
param.setBeginDate(beginDate + "");
param.setEndDate(endDate + "");
param.setKpiCode(kpiCode);
param.setUserName(userName == "" ? null : userName);
param.setDistrictId(areaId < 0 ? 0 : areaId);
param.setProductStyle(fashion == "" ? null : fashion);
param.setCustomerProperty(type == "" ? null : type);
List<ReportResult> chart = ((KpiDao) MapperFactory.createMapper(KpiDao.class)).getChartAmount(param);
Map<String, Integer> title = ((KpiDao) MapperFactory.createMapper(KpiDao.class)).getTitleAmount(param);
List<Map<String, Integer>> tableAmount = ((KpiDao) MapperFactory.createMapper(KpiDao.class))
.getTableAmount(param);
String avgTime = kpiCode.split("_")[0];
param.setKpiCode(avgTime + "_avg_time");
List<Map<String, Integer>> tableAvgTime = ((KpiDao) MapperFactory.createMapper(KpiDao.class))
.getTableAmount(param);
res.put(ConfigureAPI.RESMAPKEY.CHART, chart.toString());
res.put(ConfigureAPI.RESMAPKEY.TITLE, title.toString());
res.put(ConfigureAPI.RESMAPKEY.TABLEAMOUNT, tableAmount.toString());
res.put(ConfigureAPI.RESMAPKEY.TABLEAVG, tableAvgTime.toString());
return res;
}
public Map<String, String> queryDetail(String beginDate, String endDate, String userName) throws TException {
// TODO Auto-generated method stub
return null;
}
}4.Hadoop V2的RPC简述
Hadoop V2中的RPC采用的是自己独立开发的协议,其核心内容包含服务端,客户端,交互协议。源码内容都在hadoop-common-project项目的org.apache.hadoop.ipc包下面。
- VersionedProtocol类:
package org.apache.hadoop.ipc; import java.io.IOException; /** * Superclass of all protocols that use Hadoop RPC. * Subclasses of this interface are also supposed to have * a static final long versionID field. */ public interface VersionedProtocol { /** * Return protocol version corresponding to protocol interface. * @param protocol The classname of the protocol interface * @param clientVersion The version of the protocol that the client speaks * @return the version that the server will speak * @throws IOException if any IO error occurs */ public long getProtocolVersion(String protocol, long clientVersion) throws IOException; /** * Return protocol version corresponding to protocol interface. * @param protocol The classname of the protocol interface * @param clientVersion The version of the protocol that the client speaks * @param clientMethodsHash the hashcode of client protocol methods * @return the server protocol signature containing its version and * a list of its supported methods * @see ProtocolSignature#getProtocolSignature(VersionedProtocol, String, * long, int) for a default implementation */ public ProtocolSignature getProtocolSignature(String protocol, long clientVersion, int clientMethodsHash) throws IOException; }该类中的两个方法一个是作为版本,另一个作为签名用。
- RPC下的Server类:
/** An RPC Server. */
public abstract static class Server extends org.apache.hadoop.ipc.Server {
boolean verbose;
static String classNameBase(String className) {
String[] names = className.split("\\.", -1);
if (names == null || names.length == 0) {
return className;
}
return names[names.length-1];
}对外提供服务,处理Client端的请求,并返回处理结果。
至于Client端,监听Server端的IP和PORT,封装请求数据,并接受Response。
5.总结
这篇博客赘述了RPC的相关内容,让大家先熟悉一下RPC的相关机制和流程,并简述了Hadoop V2的RPC机制,关于Hadoop V2的RPC详细内容会在下一篇博客中给大家分享。这里只是让大家先对Hadoop V2的RPC机制有个初步的认识。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!