
新兴产业的出现和发展有两种基本模式。一种是需求导向型,实际应用中出现了明显的痛点,必须要解决,不然就有人一直痛。另一种是技术导向型,革命性的技术先出现,慢慢地新技术扩大了用户的想象空间,进而激发出新的需求。大数据从概念提出到今天形成一个完整的产业,基本上属于第二种模式。
Hadoop生态系统下的技术(包括 pig,hive,spark,storm,hbase等)是目前大数据业界中事实上的标准。但在hadoop从互联网产业走出之前,大数据本身还不能称之为一个“产业”,因为它没有形成足够大的规模。所以大数据并不是指数据量有多大,是GB,TB还是PB,这其实没有关系。真正意义上的大数据是指 hadoop体系技术从互联网行业被引入到其它行业,进而得到快速、广泛、多维度、多层次的大量普及应用。大数据之大,在于应用规模的大,而不是数据量的大。现在大数据的应用已经远远超越了互联网行业,包括公安、智慧城市、医疗、交通、教育、通信、游戏、服装、地产、旅游、保险、银行、证券、食品安全、海事、零售、气象等等--世界正快速进入全面数据服务的时代!
大数据产业发展最快的一个是美国,另一个就是中国。有关中国大数据市场容量的预测和估算有很多版本,激进者估计千亿市场的,悲观的认为国内大数据市场刚刚萌芽。判断一个行业发展趋势最好的工具现在就是求职招聘网站。我们将通过大数据相关职位空缺数,来判断国内大概有多少个企业客户在实施大数据项目。我们以51job为例做些调查分析。分析的方法非常简单,统计大数据相关职位的招聘情况。以下数据截止到2015年4月27日,来源于51job,地域覆盖北上广深杭。
分别选取了比较热门的一些招聘职位:数据分析师、hadoop、数据挖掘、大数据开发工程师,企业招聘情况如下:
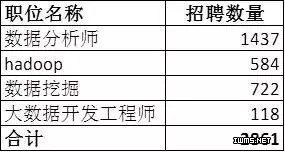
合计为2861个,对结果进行一些修正:
(1)因为职位名称,或者没覆盖到的其他大数据技术职位,乘以系数:1.2
(2)因为51job的限制,仅仅统计了5个城市,乘以系数1.3
(3)可能没在51job上发布的职位: 乘以系数1.1
这样修正后,国内大数据职位空缺数4909。根据这个数字,我们来推算客户数:
(4)考虑同一家公司可能同时有1-3个大数据相关职位发布,乘以系数:0.8
(5)假设在实施大数据项目的客户有五分之一的有招聘需求,乘以系数:5.0
最终结果:19636。
也就是说,截止2015年4月27日,国内有大概19636个大数据项目在进行。假设平均一个项目规模为50万(比较保守的估计),则国内大数据项目的规模合计为98亿人民币。考虑现在才是2015年第二季度,2015全年大数据项目规模肯定超过100亿人民币。数据服务有限公司)
|
2015中国大数据的市场容量有多大?
2015-05-26
946
版权
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《
阿里云开发者社区用户服务协议》和
《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写
侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
简介:
新兴产业的出现和发展有两种基本模式。一种是需求导向型,实际应用中出现了明显的痛点,必须要解决,不然就有人一直痛。另一种是技术导向型,革命性的技术先出现,慢慢地新技术扩大了用户的想象空间,进而激发出新的需求。
相关实践学习
SaaS 模式云数据仓库必修课
本课程由阿里云开发者社区和阿里云大数据团队共同出品,是SaaS模式云原生数据仓库领导者MaxCompute核心课程。本课程由阿里云资深产品和技术专家们从概念到方法,从场景到实践,体系化的将阿里巴巴飞天大数据平台10多年的经过验证的方法与实践深入浅出的讲给开发者们。帮助大数据开发者快速了解并掌握SaaS模式的云原生的数据仓库,助力开发者学习了解先进的技术栈,并能在实际业务中敏捷的进行大数据分析,赋能企业业务。 通过本课程可以了解SaaS模式云原生数据仓库领导者MaxCompute核心功能及典型适用场景,可应用MaxCompute实现数仓搭建,快速进行大数据分析。适合大数据工程师、大数据分析师 大量数据需要处理、存储和管理,需要搭建数据仓库?学它! 没有足够人员和经验来运维大数据平台,不想自建IDC买机器,需要免运维的大数据平台?会SQL就等于会大数据?学它! 想知道大数据用得对不对,想用更少的钱得到持续演进的数仓能力?获得极致弹性的计算资源和更好的性能,以及持续保护数据安全的生产环境?学它! 想要获得灵活的分析能力,快速洞察数据规律特征?想要兼得数据湖的灵活性与数据仓库的成长性?学它! 出品人:阿里云大数据产品及研发团队专家 产品 MaxCompute 官网 https://www.aliyun.com/product/odps

目录
相关文章
|
6月前
|
SQL
资源调度
大数据
|
大数据
调度
大数据运用在机场容量管理的实践
1070
0
0
|
大数据
大数据运用在机场容量管理的实例
1371
0
0
|
2月前
|
分布式计算
DataWorks
IDE
MaxCompute数据问题之忽略脏数据如何解决
MaxCompute数据包含存储在MaxCompute服务中的表、分区以及其他数据结构;本合集将提供MaxCompute数据的管理和优化指南,以及数据操作中的常见问题和解决策略。
46
0
0
|
2月前
|
SQL
存储
分布式计算
MaxCompute问题之下载数据如何解决
MaxCompute数据包含存储在MaxCompute服务中的表、分区以及其他数据结构;本合集将提供MaxCompute数据的管理和优化指南,以及数据操作中的常见问题和解决策略。
37
0
0
|
2月前
|
分布式计算
关系型数据库
MySQL
MaxCompute问题之数据归属分区如何解决
MaxCompute数据包含存储在MaxCompute服务中的表、分区以及其他数据结构;本合集将提供MaxCompute数据的管理和优化指南,以及数据操作中的常见问题和解决策略。
33
0
0
|
2月前
|
分布式计算
DataWorks
BI
MaxCompute数据问题之运行报错如何解决
MaxCompute数据包含存储在MaxCompute服务中的表、分区以及其他数据结构;本合集将提供MaxCompute数据的管理和优化指南,以及数据操作中的常见问题和解决策略。
38
1
1
|
2月前
|
分布式计算
关系型数据库
数据库连接
MaxCompute数据问题之数据迁移如何解决
MaxCompute数据包含存储在MaxCompute服务中的表、分区以及其他数据结构;本合集将提供MaxCompute数据的管理和优化指南,以及数据操作中的常见问题和解决策略。
31
0
0
|
2月前
|
分布式计算
Cloud Native
MaxCompute
MaxCompute数据问题之没有访问权限如何解决
MaxCompute数据包含存储在MaxCompute服务中的表、分区以及其他数据结构;本合集将提供MaxCompute数据的管理和优化指南,以及数据操作中的常见问题和解决策略。
38
0
0
|
3天前
|
数据采集
搜索推荐
大数据
大数据中的人为数据
【4月更文挑战第11天】人为数据,源于人类活动,如在线行为和社交互动,是大数据的关键部分,用于理解人类行为、预测趋势和策略制定。数据具多样性、实时性和动态性,广泛应用于市场营销和社交媒体分析。然而,数据真实性、用户隐私和处理复杂性构成挑战。解决策略包括数据质量控制、采用先进技术、强化数据安全和培养专业人才,以充分发挥其潜力。
10
3
3
热门文章
最新文章
1
数据之势丨从“看数”到“用数”,百年制造企业用大数据实现“降本增效”
2
利用Hive与Hadoop构建大数据仓库:从零到一
3
【Flume】Flume在大数据分析领域的应用
4
大模型开发:你如何使用大数据进行模型训练?
5
基于Python的数据可视化技术在大数据分析中的应用
6
Java语言在大数据处理中的应用
7
大数据基础:Linux基础详解
8
探索云原生技术在大数据分析中的应用
9
大数据定义详解
10
大数据处理架构Hadoop
1
大数据中的人为数据
10
2
数据之势丨从“看数”到“用数”,百年制造企业用大数据实现“降本增效”
72
3
大数据技术与Python:结合Spark和Hadoop进行分布式计算
20
4
大数据处理架构Hadoop
24
5
大数据项目管理:从需求分析到成果交付的全流程指南
22
6
大数据定义详解
26
7
利用Hive与Hadoop构建大数据仓库:从零到一
38
8
数字太大了,计算加法、减法会报错,结果不正确?怎么办?用JavaScript实现大数据(超过20位的数字)相加减运算。
18
9
【Flume】Flume在大数据分析领域的应用
29
10
Redis HyperLogLog: 高效统计大数据集的神秘利器
22



