Author: bakari Date: 2012/8/9
继上篇。。。。。
下面是我写的代码与源码作的一些比较,均已严格测试通过,分别以“string 之”系列述之。
strchr函数:求字符在字符串中所在的位置
strstr函数:求子串在主串中的起始位置(用的字符串的模式匹配算法)
1 char * Mystrchr(const char *str, char c); //c第一次出现的位置 2 //BF algorithm 3 int Mystrstr_BF(char *mainStr, char *subStr); //子串第一次出现的位置 4 //KMP algorithm 5 int Mystrstr_KMP(char *mainStr, char *subStr);
1 /******************************************************* 2 * strchr 3 *******************************************************/ 4 char * Mystrchr(const char *str, char c){ //c第一次出现的位置 5 assert(NULL != str); 6 for(; *str != c; str ++){ 7 if(*str == '\0') 8 return NULL; 9 } 10 return (char * )str; 11 }
下面着重讲解BF算法和KMP算法,要真正懂一个算法并将它吃透,一定要懂这个算法的历史,回到最初去了解这个算法是怎样被发现的。对于相对感性的东西不用追本溯源,咬文嚼字,但是对于理性(换个词叫抽象)的东西一定不能急躁,即使短时间内能够清楚了解之,但过了一阵之后毫无疑问会忘记,本人上学期上DS的时候已经学过这个算法,当时就是为了坑爹的考试,没有好好吃透,导致现在需要又要重新去复习回味。所以,为了做个高效的人士,还是那句老话,欲速则不达,好的算法就应该慢下心来慢慢品味,从它的根抓起。将之吃透!
本文是不会跟你去讲历史的,So,想知道历史的就Google,百度吧,在下也帮不了,本文只做简单的总结,加深印象。
一 、BF算法
这个算法符合人的思维过程,不用转弯,一看便知.为了显示清晰,用途代替文字
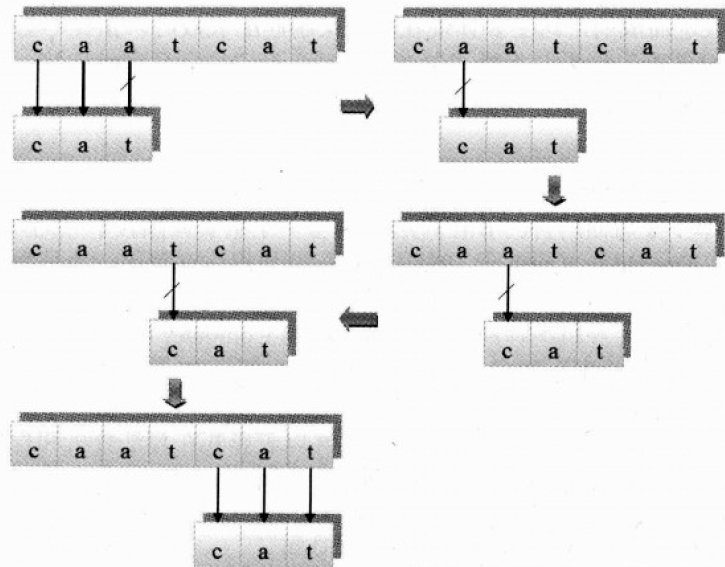
看着图就可以写代码了:
1 int BF(const char * str1, const char * str2){ 2 assert(NULL != str1 && NULL != str2); 3 int i = 0, j = 0; 4 5 while(*(str1 + i) && *(str2 + j)){ 6 if(*(str1 + i) == *(str2 + j)){ 7 ++ i; 8 ++ j; 9 } 10 else{ 11 i = i - j + 1; //i 回溯到上一轮的下一个 12 j = 0; //j 从第一个开始比较 13 } 14 } 15 if(*(str2 + j) == '\0') 16 return i - j; 17 else 18 return -1; 19 }
缺点:低效,复杂度O(M*N)
但在某些场合,如文本编辑啊,效率也较高,但对于计算机的二进制文件就显得苍白无力。
二、KMP算法
所以这个时候KMP算法诞生了,由于是三个人提出了的,所以用了三个人的名字的开头字母作为名称,我只记得Knuth,这个人实在太有名了,计算机科学的鼻祖,计算机所有奖项都拿过。
KMP算法是对BF算法的改进,当匹配失效是指针不回溯,根据失效函数(即Next[n]的值)进行下一轮的匹配。
E.g: 主串 “a b a b c a b c a c b a b” 模式串 “a b c a c”
第一趟匹配: a b a b c a b c a c b a b i = 2 i 不回溯
a b c j = 2
第二趟匹配: a b a b c a b c a c b a b i= 6
a b c a c j = 4
第三趟匹配:a b a b c a b c a c b a b i= 10
a b c a c j = 5
依上所得:用数学的语言表述:
假设主串:S1S2.....Sn 模式串:P1P2......Pm
当主串中第 i 个字符与模式串第 k 个字符不匹配,前提是前面的字符皆已匹配,则有下面的关系:
P1P2......P(k-1) = S(i - k + 1)S(i - k + 2)......S(i - 1); ...................................(1)
而对于模式串,有如下关系:
P(j - k + 1)P(j - k + 2)......P(j - 1) = S(i - k + 1)S(i - k + 2)......S(i - 1);..........(2)
根据(1)(2),得:
P1P2......P(k-1) = P(j - k + 1)P(j - k + 2)......P(j - 1);
即最终只需要在模式串中进行比较,这个比较就是计算Next[j]的值,用此作为模式串的指针回溯点。下面会介绍到。
根据以上的推导就可以宏观地写出KMP的算法的实现:
1 int KMP(const char * str1, const char * str2){ 2 assert(NULL != str1 && NULL != str2); 3 int i = 0, j = 0; 4 int next[SIZE]; 5 get_next(str2,next); //得到next[j]的值 6 7 while(*(str1 + i) && *(str2 + j)){ 8 if(*(str1 + i) == *(str2 + j)){ 9 ++ i; 10 ++ j; 11 } 12 else{ 13 j = next[j]; //i 不用回溯,j 取得next[j],进行下一轮比较 14 } 15 } 16 17 if(*(str2 + j) == '\0') 18 return i - j; 19 else 20 return 0; 21 }
所以,这个算法最终化为小问题,即求Next[j] 的值。
对于Next[j]的数学推导:
令Next[j] = k,则Next[j] 表明当模式中第 j 个字符与主串 中相应字符失效时,在模式中需重新和主串中该字符进行比较的字符的位置,由此可引出Next[j]函数的定义:
Next[j] = -1 , 当 j = 1时;
= Max{k | 1 < k < j && P1P2......P(k - 1) = P(j - k + 1)......P(j - 1) }
= 0 其他情况;
E.g: j : 0 1 2 3 4 5 6 7
模式串: a b a a b c a c
Next[j]: -1 0 0 1 1 2 0 1 0
很好计算,关键是不单要知其为,更要知其所以为。所以理解本质很重要。
下面,看一个例子就懂了:
假设:主串: “a c a b a a b a a b c a c a a b c” 模式串:“a b a a b c a c”
第一趟:a c a b a a b a a b c a c a a b c i = 1;
a b j = 1; Next[j] = 0;
第二趟:a c a b a a b a a b c a c a a b c i = 1;
a j = 0; Next[j] = -1 //模式串中的第一个元素不想等,i 后移;
第三趟:a c a b a a b a a b c a c a a b c i = 7
a b a a b c j = 5; Next[j] = 2;
第四趟:a c a b a a b a a b c a c a a b c i = 13;
a b a a b c a c j = 8; END!
了解到这里,就很容易写出一份很好的代码了:
1 void get_next1(const char * str, int Next[]){ 2 assert(NULL != str); 3 int j = Next[0] = -1; 4 int i = 0; 5 while(*(str + i)){ 6 if(-1 == j || *(str + i) == *(str + j)){ //当 j = -1时,有模式串的第一个元素开始比较 7 ++ i; 8 ++ j; 9 } 10 else 11 j = Next[j]; //上一轮比较的next[j]和下一轮将要比较的呈递增的关系,可以进行简单的数学推导 12 } 13 }
Note:还未完,下面的很重要
前面定义的Next[]函数在某些情况下有缺陷。E.g:模式串“aaaab”在和主串“aaabaaaab”匹配时,当i = 3, j = 3 时,不等,但由Next[j]的指示还需进行 i = 3, j = 2 ; i = 3, j = 1; i = 3, j = 0这三次的比较,实际上,因为模式串中第1,2,3个字符和第四个字符都相等,因此不需要再和主串第4个字符相比较,而可以直接将模式串一气像右滑动4个字符。这就是说,若按上述定义得到的Next[j] = k,而模式串中Pj = Pk ,则当主串中字符Si 和 Pj 比较不等时,不需要再和Pk进行比较,而直接和P(Next[k]) 进行比较,有点绕啊,那就 看一个实例吧:
E.g: j : 0 1 2 3 4
模式串: a a a a b
Next[j]: -1 0 1 2 3 0
Next2[j]: -1 0 0 0 3 0
换句话说就是:此时的Next[j] 应该和Next[k] 相同。由此可计算Next函数修正值的算法如下,此时匹配算法不变。
1 void get_next(const char * str, int next[]){ 2 assert(NULL != str); 3 int j = next[0] = -1; 4 int i = 0; 5 6 while(*(str + i)){ 7 if(-1 == j || *(str + i) == *(str + j)){ 8 ++ i; 9 ++ j; 10 if(*(str + i) != *(str + j)){ //先判断,不等才执行next[i] = j 11 next[i] = j; 12 } 13 else{ 14 next[i] = next[j]; //把前一个next[j]赋给后面的 15 } 16 } 17 else 18 j = next[j]; 19 } 20 }
综合以上,汇总一下代码,全部代码已经严格测试通过。
1 /******************************************************* 2 * strstr 3 * there are two algorithm : BF and KMP 4 * compare with the difference of two 5 *******************************************************/ 6 7 const int SIZE = 10; 8 int KMP(const char * str1, const char * str2); 9 int BF(const char * str1, const char * str2) ; 10 void get_next(const char * str,int next[]); 11 void get_next1(const char * str,int next[]); 12 13 int BF(const char * str1, const char * str2){ 14 assert(NULL != str1 && NULL != str2); 15 int i = 0, j = 0; 16 17 while(*(str1 + i) && *(str2 + j)){ 18 if(*(str1 + i) == *(str2 + j)){ 19 ++ i; 20 ++ j; 21 } 22 else{ 23 i = i - j + 1; //i 回溯到上一轮的下一个 24 j = 0; //j 从第一个开始比较 25 } 26 } 27 if(*(str2 + j) == '\0') 28 return i - j; 29 else 30 return -1; 31 } 32 33 int KMP(const char * str1, const char * str2){ 34 assert(NULL != str1 && NULL != str2); 35 int i = 0, j = 0; 36 int next[SIZE]; 37 get_next(str2,next); //得到next[j]的值 38 39 while(*(str1 + i) && *(str2 + j)){ 40 if(*(str1 + i) == *(str2 + j)){ 41 ++ i; 42 ++ j; 43 } 44 else{ 45 j = next[j]; //i 不用回溯,j 取得next[j],进行下一轮比较 46 } 47 } 48 49 if(*(str2 + j) == '\0') 50 return i - j; 51 else 52 return 0; 53 } 54 55 void get_next(const char * str, int next[]){ 56 assert(NULL != str); 57 int j = next[0] = -1; 58 int i = 0; 59 60 while(*(str + i)){ 61 if(-1 == j || *(str + i) == *(str + j)){ 62 ++ i; 63 ++ j; 64 if(*(str + i) != *(str + j)){ //先判断,不等才执行next[i] = j 65 next[i] = j; 66 } 67 else{ 68 next[i] = next[j]; //把前一个next[j]赋给后面的 69 } 70 } 71 else 72 j = next[j]; 73 } 74 } 75 76 void get_next1(const char * str, int Next[]){ 77 assert(NULL != str); 78 int j = Next[0] = -1; 79 int i = 0; 80 while(*(str + i)){ 81 if(-1 == j || *(str + i) == *(str + j)){ //当 j = -1时,有模式串的第一个元素开始比较 82 ++ i; 83 ++ j; 84 } 85 else 86 j = Next[j]; //上一轮比较的next[j]和下一轮将要比较的呈递增的关系,可以进行简单的数学推导 87 } 88 }
欢迎指正交流!