[本文出自天外归云的博客园]
前篇
用webdriver+phantomjs实现无浏览器的自动化过程
本篇
想法与实现
我想要将博客园“我的闪存”部分内容爬取备份到本地文件,用到了WebDriver和Phantomjs的无界面浏览器。对于xpath的获取与校验需要用到firefox浏览器,安装firebug和firepath插件。代码如下:
# -*- coding: utf-8 -*- import os,time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC import selenium.webdriver.support.ui as ui def crawl_memeory(username,pwd): #Start login cnblogs. driver = webdriver.PhantomJS() driver.get("http://passport.cnblogs.com/user/signin?ReturnUrl=http%3A%2F%2Fwww.cnblogs.com%2F") wait = ui.WebDriverWait(driver, 10) wait.until(lambda dr: dr.find_element_by_id('signin').is_displayed()) driver.find_element_by_id("input1").send_keys(username) driver.find_element_by_id("input2").send_keys(pwd) driver.find_element_by_id("signin").click() time.sleep(3) #Navigate to my memory. memory_url = "https://ing.cnblogs.com#my" driver.get(memory_url) wait.until(lambda dr: dr.find_element_by_id('feed_list').is_displayed()) element = driver.find_element_by_xpath(".//*[@id='pager_bottom']/a[last()-1]") page_num = int(element.text) #For each page, crawl the memory. store_dir_path = os.path.join(os.path.abspath(os.path.dirname(__file__)),"cnblogs_memory") if os.path.exists(store_dir_path): pass else: os.mkdir(store_dir_path) #Set the html's local storage path. store_html_path = os.path.join(store_dir_path,"cnblogs_memory.txt") f = open(store_html_path,"w") f.close() memory_url = "https://ing.cnblogs.com#my/p" with open(store_html_path,"a") as file: file.write("<!DOCTYPE html><html><head><meta charset=\"utf-8\"><title>博客园我的闪存</title></head><body>") for i in range(page_num): wait.until(lambda dr: dr.find_element_by_id('feed_list').is_displayed()) memory_contents = driver.find_elements_by_xpath(".//*[@id='feed_list']/ul/li") for memory_content in memory_contents: inner_content = memory_content.get_attribute("innerHTML") with open(store_html_path,"a+") as file: file.write(inner_content.encode("utf-8")) pic_name = "cnblogs_memory_"+str(i+1)+".jpg" store_pic_path = os.path.join(store_dir_path,pic_name) driver.save_screenshot(store_pic_path) last_page_button = driver.find_element_by_xpath(".//*[@id='pager_bottom']/a[last()]") if(last_page_button.text.startswith("Next")): last_page_button.click() driver.quit() with open(store_html_path,"a") as file: file.write("</body></html>") if __name__ == '__main__': pwd = "密码" username = "用户名" crawl_memeory(username,pwd)
使用方法
保存以上代码到本地“cnblogs_memory_crawl.py”文件,替换用户名与密码。在命令行中用python运行。
运行效果
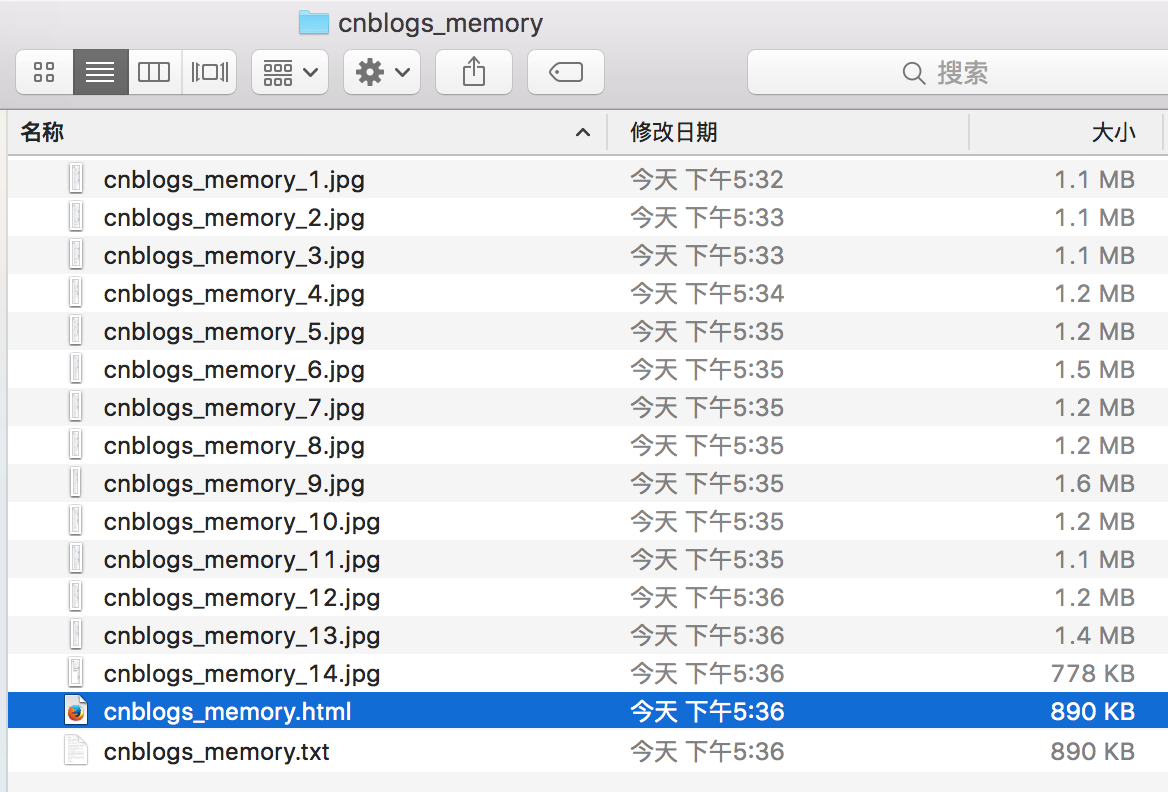
本地会在当前运行脚本路径下生成cnblogs_memory文件夹并在其下生成txt文件以及截图文件,截图文件保存了博客园中所有我的闪存页:
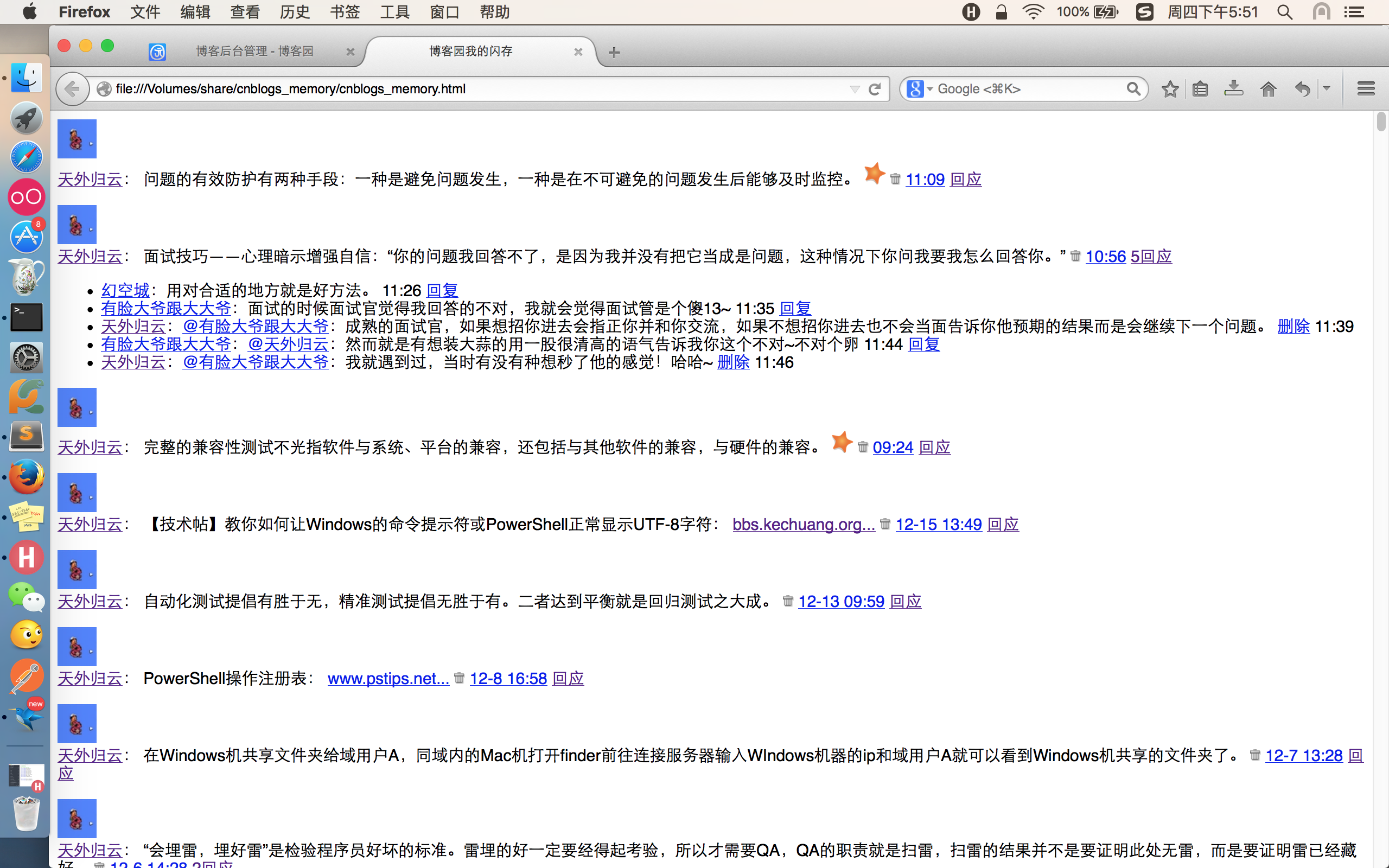
手动将txt文件后缀改为html打开,效果如下:
进一步优化
可以编写脚本对保存到本地的文件内容进行进一步删取,保留你想要的部分。