一、lucene简介
Lucene是apache下的一个靠性能的、功能全面的用纯java开发的一个全文搜索引擎库。它几乎适合任何需要全文搜索应用程序,尤其是跨平台。lucene是开源的免费的工程。lucene使用简单但是提供的功能非常强大。相关特点如下:
- 在硬件上的速度超过150GB/小时
- 更小的内存需求,只需要1MB堆空间
- 快速地增加索引、与批量索引
- 索引的大小大于为被索引文本的20%-30%
lucene下载地址为:http://lucene.apache.org/
文本示例工程使用maven构建,lucene版本为5.2.1。相关依赖文件如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.shh</groupId> <artifactId>lucene</artifactId> <packaging>war</packaging> <version>0.0.1-SNAPSHOT</version> <name>lucene Maven Webapp</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <lucene.version>5.2.1</lucene.version> </properties> <dependencies> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>${lucene.version}</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>${lucene.version}</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>${lucene.version}</version> </dependency> <!-- 分词器 --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-smartcn</artifactId> <version>${lucene.version}</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-highlighter</artifactId> <version>${lucene.version}</version> </dependency> </dependencies> <build> <finalName>lucene</finalName> </build> </project>
二、示例
1、索引的创建
相关代码如下:
1 package com.test.lucene; 2 3 import java.io.IOException; 4 import java.nio.file.Paths; 5 6 import org.apache.lucene.analysis.Analyzer; 7 import org.apache.lucene.analysis.standard.StandardAnalyzer; 8 import org.apache.lucene.document.Document; 9 import org.apache.lucene.document.Field.Store; 10 import org.apache.lucene.document.IntField; 11 import org.apache.lucene.document.StringField; 12 import org.apache.lucene.document.TextField; 13 import org.apache.lucene.index.IndexWriter; 14 import org.apache.lucene.index.IndexWriterConfig; 15 import org.apache.lucene.index.IndexWriterConfig.OpenMode; 16 import org.apache.lucene.store.Directory; 17 import org.apache.lucene.store.FSDirectory; 18 19 /** 20 * 创建索引 21 */ 22 public class IndexCreate { 23 24 public static void main(String[] args) { 25 // 指定分词技术,这里使用的是标准分词 26 Analyzer analyzer = new StandardAnalyzer(); 27 28 // indexWriter的配置信息 29 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer); 30 31 // 索引的打开方式:没有则创建,有则打开 32 indexWriterConfig.setOpenMode(OpenMode.CREATE_OR_APPEND); 33 34 Directory directory = null; 35 IndexWriter indexWriter = null; 36 try { 37 // 索引在硬盘上的存储路径 38 directory = FSDirectory.open(Paths.get("D://index/test")); 39 //indexWriter用来创建索引文件 40 indexWriter = new IndexWriter(directory, indexWriterConfig); 41 } catch (IOException e) { 42 e.printStackTrace(); 43 } 44 45 //创建文档一 46 Document doc1 = new Document(); 47 doc1.add(new StringField("id", "abcde", Store.YES)); 48 doc1.add(new TextField("content", "中国广州", Store.YES)); 49 doc1.add(new IntField("num", 1, Store.YES)); 50 51 //创建文档二 52 Document doc2 = new Document(); 53 doc2.add(new StringField("id", "asdff", Store.YES)); 54 doc2.add(new TextField("content", "中国上海", Store.YES)); 55 doc2.add(new IntField("num", 2, Store.YES)); 56 57 try { 58 //添加需要索引的文档 59 indexWriter.addDocument(doc1); 60 indexWriter.addDocument(doc2); 61 62 // 将indexWrite操作提交,如果不提交,之前的操作将不会保存到硬盘 63 // 但是这一步很消耗系统资源,索引执行该操作需要有一定的策略 64 indexWriter.commit(); 65 } catch (IOException e) { 66 e.printStackTrace(); 67 } finally { 68 // 关闭资源 69 try { 70 indexWriter.close(); 71 directory.close(); 72 } catch (IOException e) { 73 e.printStackTrace(); 74 } 75 } 76 } 77 }
2、搜索
相关代码如下:
1 package com.test.lucene; 2 3 import java.io.IOException; 4 import java.nio.file.Paths; 5 6 import org.apache.lucene.analysis.Analyzer; 7 import org.apache.lucene.analysis.standard.StandardAnalyzer; 8 import org.apache.lucene.document.Document; 9 import org.apache.lucene.index.DirectoryReader; 10 import org.apache.lucene.queryparser.classic.ParseException; 11 import org.apache.lucene.queryparser.classic.QueryParser; 12 import org.apache.lucene.search.IndexSearcher; 13 import org.apache.lucene.search.Query; 14 import org.apache.lucene.search.TopDocs; 15 import org.apache.lucene.store.Directory; 16 import org.apache.lucene.store.FSDirectory; 17 18 /** 19 * 搜索 20 */ 21 public class IndexSearch { 22 23 public static void main(String[] args) { 24 //索引存放的位置 25 Directory directory = null; 26 try { 27 // 索引硬盘存储路径 28 directory = FSDirectory.open(Paths.get("D://index/test")); 29 // 读取索引 30 DirectoryReader directoryReader = DirectoryReader.open(directory); 31 // 创建索引检索对象 32 IndexSearcher searcher = new IndexSearcher(directoryReader); 33 // 分词技术 34 Analyzer analyzer = new StandardAnalyzer(); 35 // 创建Query 36 QueryParser parser = new QueryParser("content", analyzer); 37 Query query = parser.parse("广州");// 查询content为广州的 38 // 检索索引,获取符合条件的前10条记录 39 TopDocs topDocs = searcher.search(query, 10); 40 if (topDocs != null) { 41 System.out.println("符合条件的记录为: " + topDocs.totalHits); 42 for (int i = 0; i < topDocs.scoreDocs.length; i++) { 43 Document doc = searcher.doc(topDocs.scoreDocs[i].doc); 44 System.out.println("id = " + doc.get("id")); 45 System.out.println("content = " + doc.get("content")); 46 System.out.println("num = " + doc.get("num")); 47 } 48 } 49 directory.close(); 50 directoryReader.close(); 51 } catch (IOException e) { 52 e.printStackTrace(); 53 } catch (ParseException e) { 54 e.printStackTrace(); 55 } 56 } 57 }
运行结果如下:

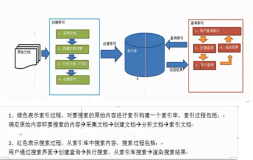
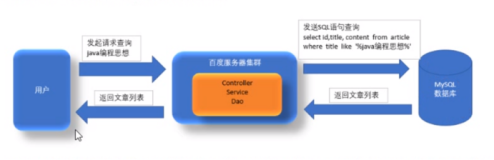
三、lucene的工作原理
lucene全文搜索分为两个步骤:
索引创建:将数据(包括数据库数据、文件等)进行信息提取,并创建索引文件。
搜索索引:根据用户的搜索请求,对创建的索引进行搜索,并将搜索的结果返回给用户。
相关示意图如下: