一个老客户提出这样的需求,希望将SQLServer中的某个表的数据快速复制到SQLite数据库里面以便进行定期的备份处理,数据表的记录大概有50多万条记录,表有100个字段左右,除了希望能够快速做好外,效率是第一位的,他自己测试总是在一两个小时的时间以上。客户提出这样的需求,我我觉得肯定是没有很好的利用事务的特性,否则速度应该会快得多,但是具体能快到什么程度,心里也不太确定。于是按照这个要求,把这样大的表数据复制作为一个案例来进行研究,最终大数据的复制处理,不到20分钟就可以完成全部数据的复制更新处理。本文主要介绍这个需求如何结合实际开发的需要进行处理,达到快速高效的复制数据的目的,并提供相关的实现思路和代码供参考学习。
1、复制数据的需求及开发思路
由于客户是需要做定期的数据备份,因此这样的复制是进行的,因此大数据的复制效率肯定是很重要的,应该尽可能的短时间完成。数据表的记录大概有50多万条记录,表有100个字段左右的需要也是比常规的表数据会多一些,因此需要做好很好的测试,我们根据这样的需求背景,使用一个测试案例来对性能进行测试。
这样多字段的表,数据字段的一一对应,手工肯定是很累的,所以我们使用代码生成工具Database2Sharp来进行快速开发,这样底层的处理我们就可以不用太过关注,而且可以为不同的数据处理,生成不同的数据访问层即可。
在底层我们主要是采用了微软的Enterprise Library的数据库访问模块,因此它能够很好抽象各种数据库的事务,以适应各种不同数据库的事务处理。使用微软的Enterprise Library模块,可以很好支持SQLSever、Oracle、Mysql、Access、SQLite等数据库。
开发框架,常见的分层模式,可以分为UI层、BLL层、DAL层、IDAL层、Entity层、公用类库层等等

框架的基类我们封装了大量的通用性处理函数,包括数据访问层、业务逻辑层的基类,所有的基类函数基本上都带有一个DbTransaction trans = null 的定义,就是我们可以采用事务,也可以默认不采用事务,是一个可选性的事务参数。
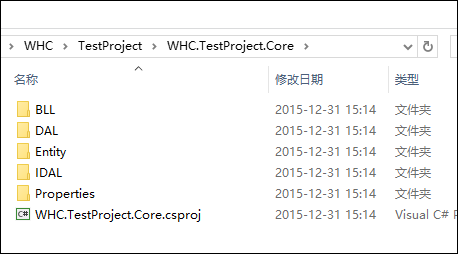
如数据访问接口和基于SQLServer的数据访问类的实现图示如下所示。
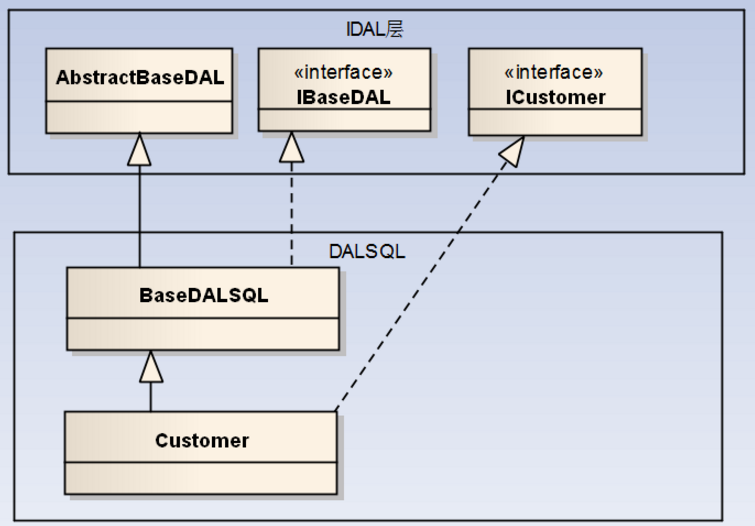
在最高级的抽象基类AbstractBaseDAL的数据访问层里面,都有大量关于数据操作和相关事务的接口可以使用,因此我们在底层继承的子类,如果我们处理数据的增删改查等操作,基本上就不需要做任何扩展性代码了,这样很符合我们快速开发的目的。
在框架的整个数据访问层,我们都定义了很多公用的、带有事务参数的接口,如果我们在常规的数据处理里面,使用事务的话,那么也是很方便的事情。使用事务的批量处理,对于SQLite的操作来说,效率是非常明显的,具体可以在我之前的随笔里《使用事务操作SQLite数据批量插入,提高数据批量写入速度,源码讲解》可以了解到,他们之间的处理效率是很大差距的。
2、使用代码生成工具生成所需的代码
上面讲到,开发这样的数据复制处理程序,这样多字段的表,数据字段的一一对应,手工肯定是很累的,所以我们使用代码生成工具Database2Sharp来进行快速开发。
因此使用代码生成工具来快速生成所需要的代码,展开数据库后,从数据库节点上,右键选择【代码生成】【Enterprise Library代码生成】就可以生成标准的界面层一下的代码了,由于我们整个案例是非标准的数据复制处理,界面部分不需要利用代码生成工具进行Winform界面的生成的。
生成代码的一步步操作,最后确认一下就可以生成相关的底层代码了
最后我们生成这样的BLL、DAL、IDAL、Entity几个层的项目代码,整个项目的代码各种继承关系已经处理好了,也就具有了基类拥有的增删改查等基础操作了。
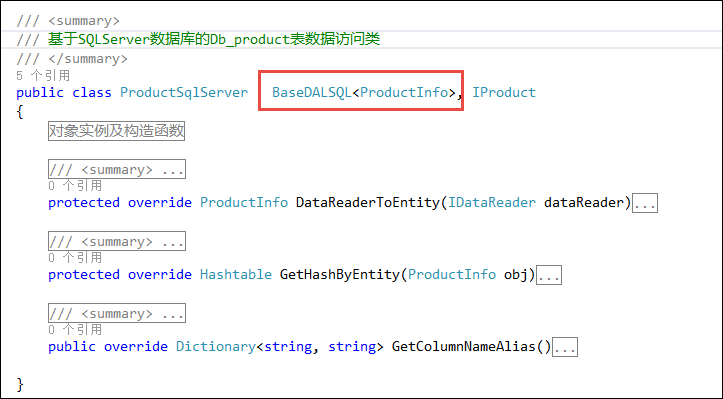
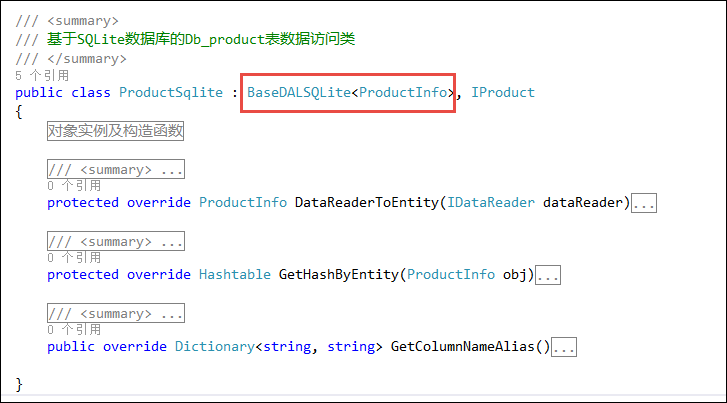
我们做两个不同数据库的复制处理操作,关键还是要生成两个不同数据库访问类的代码(也就是生成一个标准的SQLServer后,复制一份代码,修改下继承基类即可实现),如下代码是两个数据访问类的代码,不用增加任何接口即可满足当前项目的需要的了。
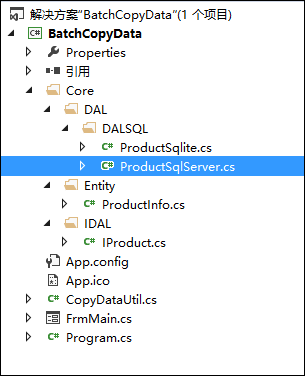
最终我们的项目结构如下所示。
3、进行数据复制处理的Winform界面代码逻辑
为了方便整个复制过程的进度展示(很重要),我们设计了进度条以及文字内容,展示处理过程的进度和耗时等信息,最终界面设计如下所示。

整个界面设计利用后台线程的方式对数据复制进行处理,方便及时在界面显示进度而不阻塞界面线程。
具体的界面代码如下所示。
public partial class FrmMain : Form { private TimeSpan ExecuteTime; private int currentCount = 0; private BackgroundWorker work = new BackgroundWorker();//使用后台线程进行处理,不阻塞界面显示 public FrmMain() { InitializeComponent(); //定义后台线程的处理 work.DoWork += work_DoWork; work.WorkerReportsProgress = true; work.ProgressChanged += work_ProgressChanged; work.RunWorkerCompleted += work_RunWorkerCompleted; } //线程完成后通知结束 void work_RunWorkerCompleted(object sender, RunWorkerCompletedEventArgs e) { this.toolStripProgressBar1.Value = 100; this.toolStripProgressBar1.Visible = false; MessageUtil.ShowTips("操作完成"); ShowMessage(this.toolStripProgressBar1.Value);//完成 } /// <summary> /// 在界面显示文本信息 /// </summary> /// <param name="percent">完成百分比</param> private void ShowMessage(int percent) { if (this.ExecuteTime != null) { this.lblTips.Text = string.Format("[当前完成数量:{0},完成百分比:{1}, 执行耗时:{2}毫秒 | {3}分钟{4}秒]", this.currentCount, percent, this.ExecuteTime.TotalMilliseconds, this.ExecuteTime.Minutes, this.ExecuteTime.Seconds); } } /// <summary> /// 报告进度的时候,显示相关的数量、耗时等内容 /// </summary> void work_ProgressChanged(object sender, ProgressChangedEventArgs e) { this.toolStripProgressBar1.Value = e.ProgressPercentage; this.statusStrip1.Refresh(); ShowMessage(e.ProgressPercentage); } /// <summary> /// 后台线程执行的逻辑代码 /// </summary> void work_DoWork(object sender, DoWorkEventArgs e) { CopyDataUtil util = new CopyDataUtil(); //使用一个Action的Lamda表达式,执行通知界面处理 util.Start((percent, ts, current) => { work.ReportProgress(percent); this.ExecuteTime = ts; this.currentCount = current; }); } private void btnCopy_Click(object sender, EventArgs e) { if(!work.IsBusy) { //如果每次要求使用空白数据库测试,那么先删除旧数据库,再复制备份过去即可 string dbfile = Path.Combine(Environment.CurrentDirectory, "localdb.db"); string bakfile = Path.Combine(Environment.CurrentDirectory, "db.db"); if (this.chkCopyEmptyDb.Checked && File.Exists(dbfile)) { File.Delete(dbfile); File.Copy(bakfile, dbfile, true); } //显示进度条,并异步执行线程 this.toolStripProgressBar1.Visible = true; work.RunWorkerAsync(); } } private void FrmMain_FormClosing(object sender, FormClosingEventArgs e) { //取消注册的相关事件,防止退出的时候出现异常 if(work != null && work.IsBusy) { work.ProgressChanged -= work_ProgressChanged; //取消通知事件 work.RunWorkerCompleted -= work_RunWorkerCompleted;//取消完成事件 work.Dispose(); } } }
在上面的窗体界面代码里面,最为关键的代码就是具体后台进程的处理逻辑,如下代码所示。
/// <summary> /// 后台线程执行的逻辑代码 /// </summary> void work_DoWork(object sender, DoWorkEventArgs e) { CopyDataUtil util = new CopyDataUtil(); //使用一个Action的Lamda表达式,执行通知界面处理 util.Start((percent, ts, current) => { work.ReportProgress(percent); this.ExecuteTime = ts; this.currentCount = current; }); }
上面的处理逻辑为了方便,把数据的复制内容放到了一个辅助类里面,并在辅助类的Start方法里面传入了界面通知的Action处理函数,这样我们在CopyDataUtil 处理的时候就可以随时进行消息的通知了。
数据复制的Start方法定义如下所示。
/// <summary> /// 开始执行赋值 /// </summary> public void Start(Action<int, TimeSpan, int> doFunc) { StartTime = DateTime.Now;//计时开始 InternalCopry(doFunc);//处理数据复制逻辑,并执行外部的函数 EndTime = DateTime.Now;//计时结束 }
整个辅助类CopyDataUtil 类里面定义了两个不同数据库类型的对象,方便数据库的赋值处理操作,并且定义了开始时间,结束时间,这样可以统计总共的耗时信息,如下代码所示。
/// <summary> /// 复制数据的处理类 /// </summary> public class CopyDataUtil { //使用一个计时器,对操作记录进行计时 private DateTime StartTime, EndTime; //SQLServer数据库表对象 private ProductSqlServer sqlserver = null; //SQLite数据表对象 private ProductSqlite sqlite = null; public CopyDataUtil() { //构建对象,并指定SQLServer的数据库配置项 sqlserver = new ProductSqlServer(); sqlserver.DbConfigName = "sqlserver"; //构建对象,并指定SQLite的数据库配置项 sqlite = new ProductSqlite(); sqlite.DbConfigName = "sqlite"; }
整个复制数据的逻辑,主要就是基于事务性的处理,按照分页规则,每次按照一定的数量,批量从SQLServer里面取出数据,然后插入SQLite数据库里面,使用事务可以是的SQLite的数据写入非常高效快速,具体代码如下所示。
/// <summary> /// 大数据复制的处理逻辑 /// </summary> /// <param name="doFunc">外部调用的函数</param> private void InternalCopry(Action<int, TimeSpan, int> doFunc) { //设置主键,并指定分页数量大小,提高检索效率 string primaryKey = "h_id"; int pageSize = 1000; PagerInfo info = new PagerInfo(){PageSize = pageSize, CurrenetPageIndex =1}; //根据数据的总数,取得总页数 int totalPageCount = 1; int totalCount = sqlserver.GetRecordCount(); if (totalCount % pageSize == 0) { totalPageCount = totalCount / pageSize; } else { totalPageCount = totalCount / pageSize + 1; } totalPageCount = (totalPageCount < 1) ? 1 : totalPageCount; //利用事务进行SQLite数据写入,提高执行响应效率 DbTransaction trans = sqlite.CreateTransaction(); if (trans != null) { //根据每页数量,依次从指定的页数取数据 for (int i = 1; i <= totalPageCount; i++) { info.CurrenetPageIndex = i;//设定当前的页面,并进行数据获取 int j = 1; List<ProductInfo> list = sqlserver.FindWithPager("1=1", info, primaryKey, false); foreach (ProductInfo entity in list) { //取得当前数量和进度百分比 int current = (i - 1) * pageSize + j; int percent = GetPercent(totalCount, current); //计算程序耗时,执行外部函数进行界面通知 TimeSpan ts = DateTime.Now - StartTime; doFunc(percent, ts, current);//执行通知处理 //如果不存在主键记录,则写入,否则更新 if (!sqlite.IsExistKey(primaryKey, entity.H_id, trans)) { sqlite.Insert(entity, trans); } else { sqlite.Update(entity, entity.H_id, trans); } j++; } } trans.Commit(); } }
至此,整个项目的代码就基本上介绍完毕了,测试整个复制过程,单表50多万的数据,100个字段左右,在开发机器上20分钟不到就复制完成,确实是很不错的成绩了,如果修改为服务器的环境专门做复制处理,肯定速度还会提高不少。

本文转自博客园伍华聪的博客,原文链接:大数据高效复制的处理案例分析总结,如需转载请自行联系原博主。




