
李涓子,清华大学计算机科学与技术系教授,博士生导师。清华-青岛数据科学研究院科技大数据研究中心主任、中国中文信息学会语言与知识计算专委会主任、中国计算机学会术语委员会执行委员。研究兴趣是语义 Web,新闻挖掘与跨语言知识图谱构建。多篇论文在重要国际会议(WWW、IJCAI、SIGIR、SIGKDD)和学术期刊(TKDE、TKDD)上发表。主持多项国家级、部委级和国际合作项目研究,包括国家自然科学基金重点项目、欧盟第七合作框架、新华社项目等。获得 2013 年人工智能学会科技进步一等奖,2013年电子学会自然科学二等奖。
以下是演讲实录:
今天我的演讲主题是“知识工程:机器智能的加速器”,下面我将结合数据、信息、知识、智能等相关概念及其关系回顾知识工程四十年来的研究和应用发展,包括大数据时代知识工程的挑战以及我们的部分相关工作。
一、知识工程四十年:让机器更智能
我们迎来了大数据时代,大数据具有规模性、多样性、快速性和真实性等特点。大数据正在改变我们的生活、工作和思考方式。
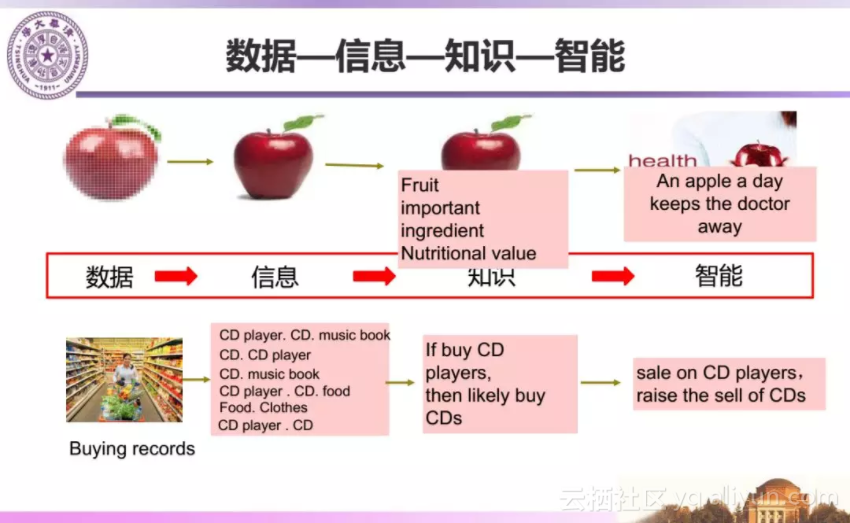
在这样的背景下,大数据对智能服务的需求已经从单纯的搜集获取信息,转变为自动化的知识提供服务,这也给知识工程提出了很多挑战性的问题。我们需要利用知识工程为大数据添加语义/知识,使数据产生智慧(smart data),完成从数据到信息再到知识,最终到智能应用的转变过程,从而实现对大数据的洞察、提供用户关心问题的答案、为决策提供支持、改进用户体验等目标。

今年恰逢知识工程提出40年,我们梳理了知识工程的四十年发展历程,总结知识工程的演进过程、技术进展以及为机器智能所做的贡献。
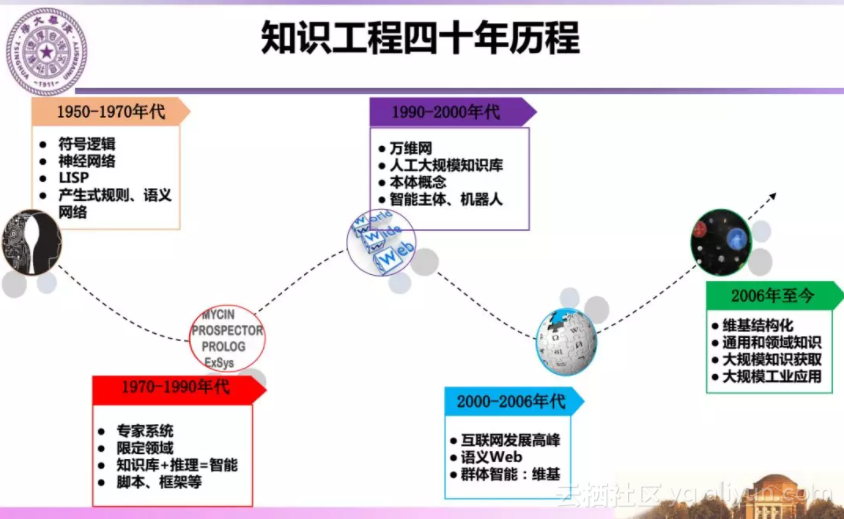
1950-1970年代 图灵测试:
人工智能旨在让机器能够像人一样解决复杂问题,智能的评测是图灵测试。这一阶段主要涌现出两种人工智能方法:符号主义和连结主义。通用问题求解程序(GPS)成为当时代表性的方法:将问题进行形式化的表达,通过搜索,从问题的初始状态,结合定义的规则或表示,得到目标状态。典型应用是博弈论和机器定理证明等。这一时期的知识表达主要有逻辑知识表示、产生式规则、语义网络等。

1970-1990年代 专家系统:
只有通用问题求解不足以支持实现智能,Feigenbaum认为知识是机器实现智能的核心,在70年代中后期年正式提出以专家系统为代表的知识工程概念,通过知识库+推理实现更智能的系统。这表明在求解问题过程中还需要注入领域知识,以此确立知识工程在人工智能领域的核心地位。这一时期知识表示有新的演进,包括框架和脚本等。80年代后期出现很多专家系统的开发平台,可以帮助将专家领域的知识转变成计算机可以处理的知识。

1990-2000年代 Web1.0万维网:
万维网(World Wide Web)的产生为人们提供了一个开放平台,使用HTML定义文本内容,通过超链接把文本连接起来,以此共享信息。随后出现了XML—标签语言,对内容结构通过定义标签进行标记,为后续互联网环境下知识表示奠定了基础。
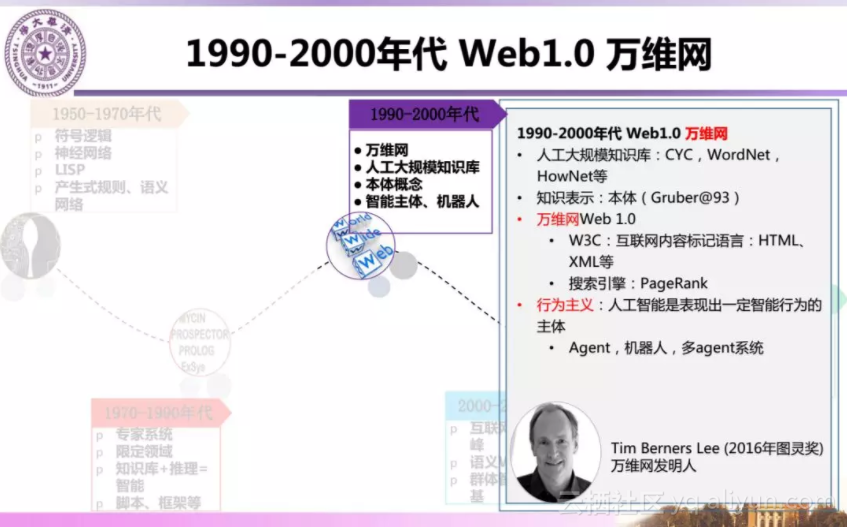
2000-2006年代 Web2.0 群体智能:
这一时期是信息爆炸式增长的过程,万维网的出现使得我们的知识从封闭走向开放,从集中成为分布。原来专家系统是系统内部定义的知识,现在可以实现知识源之间相互连接,可以通过关联来产生更多更丰富的知识,而非完全由确定的人或者单位生产。这个过程就是群体智能,最典型的代表就是维基百科,大众用户去建立知识,体现了互联网大众用户对知识的贡献,也今天的大规模知识图谱的基础。同时,在2001年万维网发明人、2016年图灵奖获得者Tim Berners-Lee提出语义Web的概念,旨在对互联网内容进行结构化语义表示,而RDF和OWL就是对内容结构化表示的标识定义,在这样的语义表示支持下,人和机器才能够更好协同工作。

2006年至今 知识图谱:
这一时期有很多工作在对维基百科进行结构化,例如DBpedia、YAGO和Freebase等。Google的知识图谱(knowledge graph)就是收购了Freebase之后产生的大规模知识图谱。现在我们看知识图谱的发展和应用状况,除了通用的大规模知识图谱,各行各业也在建立行业和领域的知识图谱。我们也看到了恨到大规模知识图谱的应用,包括语义搜索、问答系统与聊天、大数据语义分析以及智能知识服务等,更多知识图谱的创新应用还有待开发。

二、知识工程与大数据机器学习的结合
随着信息技术进步和大数据时代的到来,大数据机器学习也得到快速发展,基于表示学习和深度神经网络的机器学习方法获得了巨大成果,并已经成功应用于语音识别、图像识别和机器翻译等。
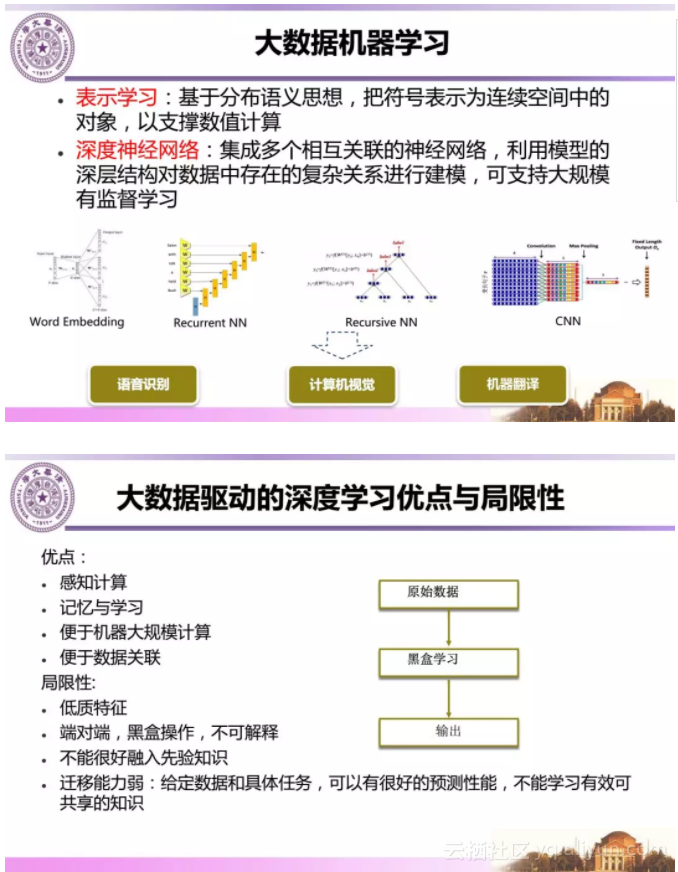
总结大数据驱动的深度学习的优点和局限性可以看出,当前大数据驱动的机器学习是一个黑盒的学习过程。而计算机若要实现智能,就意味着能够帮助人类做完成复杂工作或则做出决策。目前的大数据机器学习能够给予一些决策支持,但用户不会满足于只给推荐结果,用户希望的习得的模型解释给出的模型为何成功何时成功等。这就是可解释的人工智能,这就需要与人的认知进行结合。
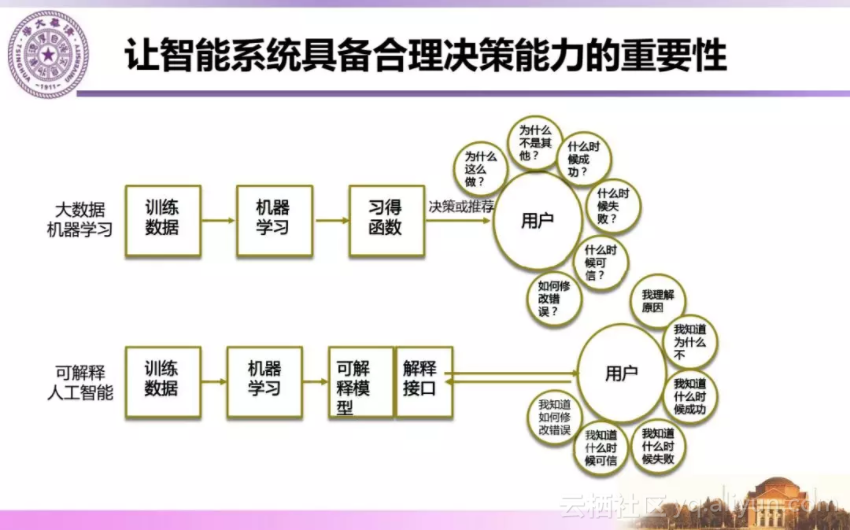
比如机器自动识别出一张图片中的物体是猫,它还需要告诉我们为什么判断为猫,如应为猫有毛、有胡须有爪子等毛的特征,也就是告诉人们机器做决策的依据是什么。

由此,大数据深度学习学到的是事物底层特征空间,人能理解的对应的是事物语义空间,这当中存在语义鸿沟,而知识图谱可以用来弥合这个鸿沟。

现在我们来看以知识驱动为代表的专家系统的典型结构:知识库、推理引擎和人机接口。当时专家系统没有发展起来主要受限于专家知识难以获得以及计算机计算能力的限制。
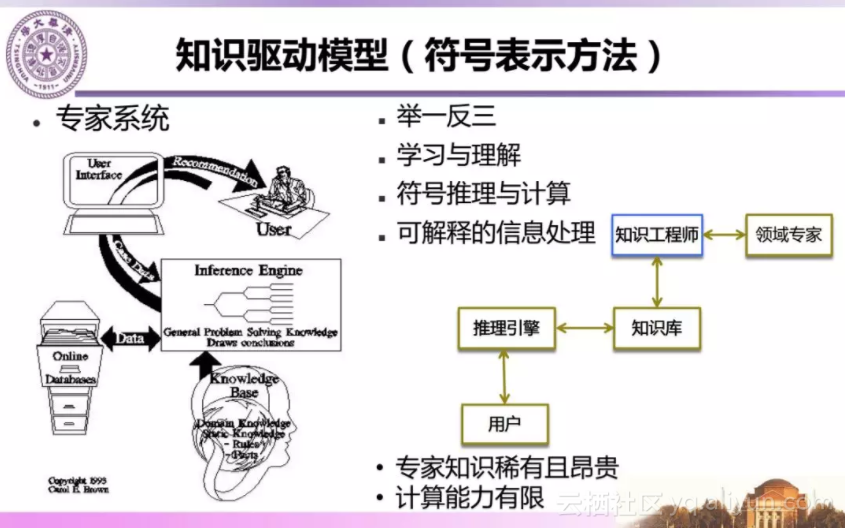
在大数据环境下,我们可以采用自动或者半自动方法利用大数据机器学习方法从大数据中获得知识,由此建立大数据环境下智能系统。
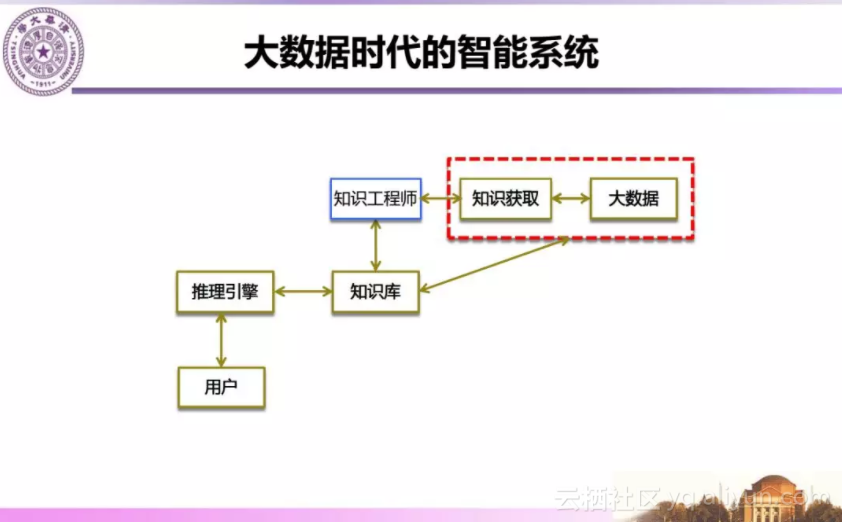
三、大数据环境下知识工程的研究和挑战
在大数据环境下,我们希望能够从互联网开放环境下的大数据获得知识,用这些知识提供智能服务反哺互联网/行业。这是一个迭代的相互增强过程,最终的目的是实现从互联网信息服务到智能知识服务的跃迁。
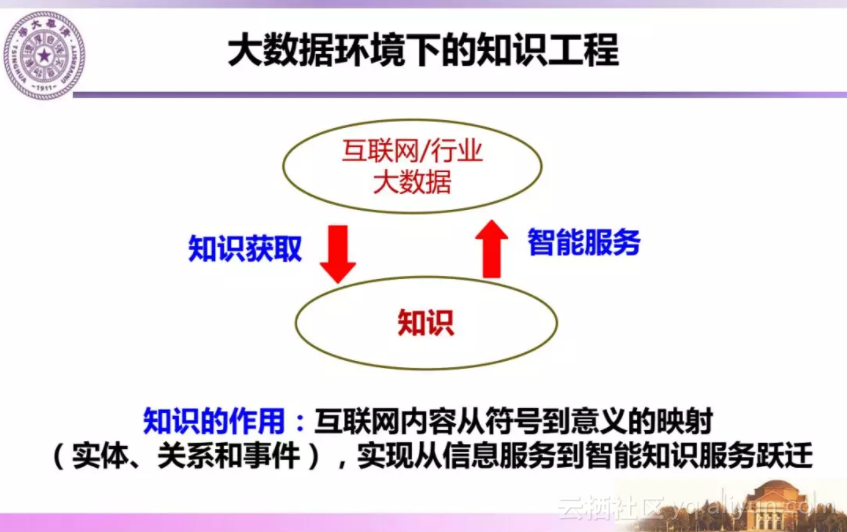
因为提出知识工程而在1994年获得图灵奖的Feigenbaum教授将知识工程定义为:将知识集成到计算机系统完成只有特定领域专家才能完成的复杂任务。在大数据时代,我们对此进一步改进:知识工程是从大数据中自动或半自动获取知识,建立基于知识的系统,以此提供互联网智能知识服务,如语义搜索和问答系统等。

总结当前知识驱动和数据驱动的人工智能方法,以符号表示为代表的知识驱动方法表示的知识明确、可以举一反三、进行解释和推理。而大数据深度学习为代表的数据驱动方法可以进行感知和记忆,进行关联计算,但是难以解释其推理计算过程。因此两种方法的融合为我们研究基于知识的智能技术提供了契机。
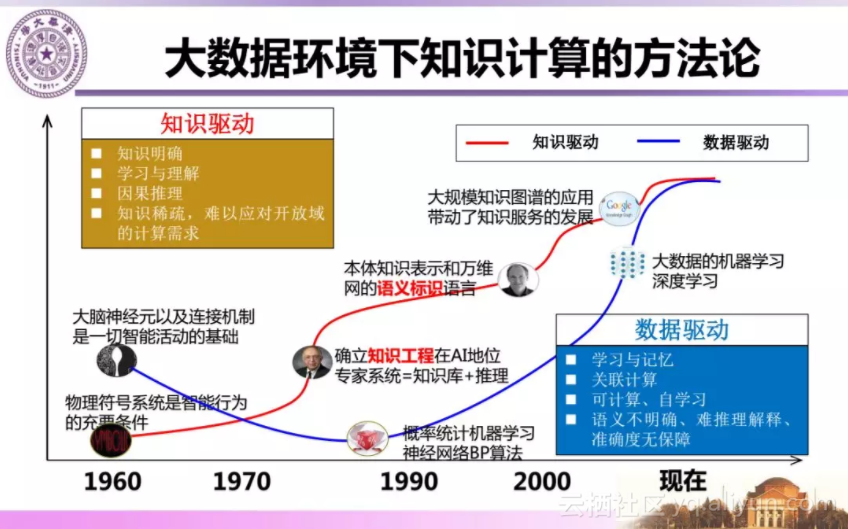
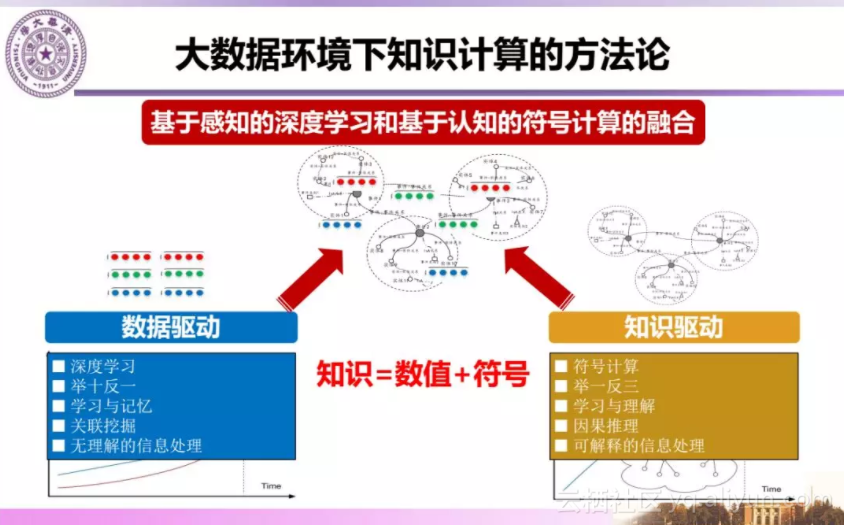
同时,两种方法的融合也带来许多挑战性问题。下面从组成知识工程生命周期的知识建模、知识获取、知识存储和计算、以及知识重用的四个阶段看每个阶段所面临的挑战。
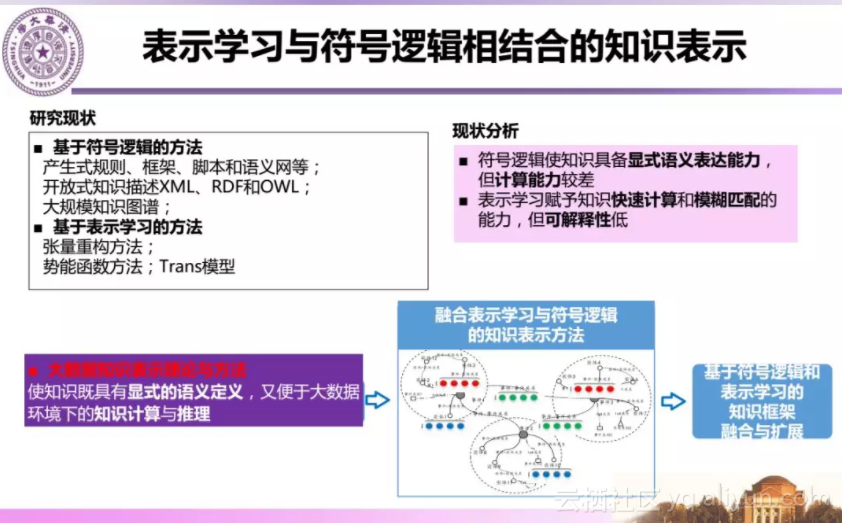
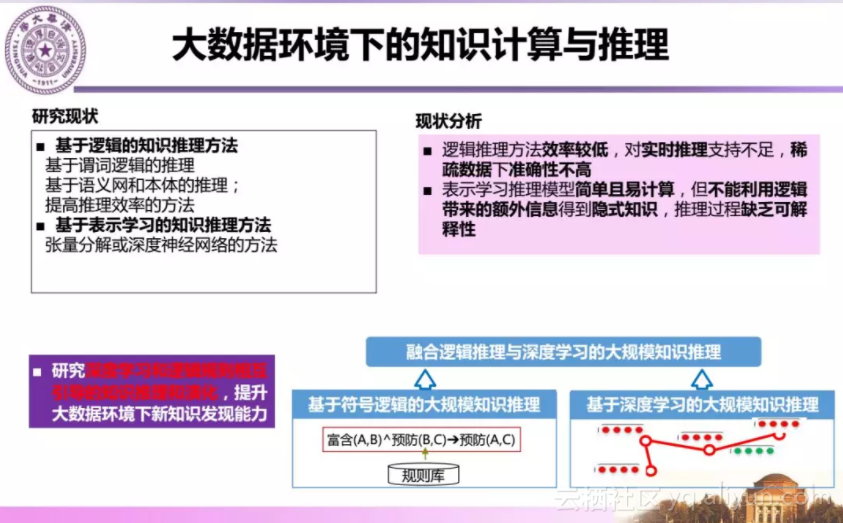
知识表示方面,主要是研究大数据知识表示的理论与方法,使知识既具有显式的语义定义,又便于大数据环境下的知识计算与推理。
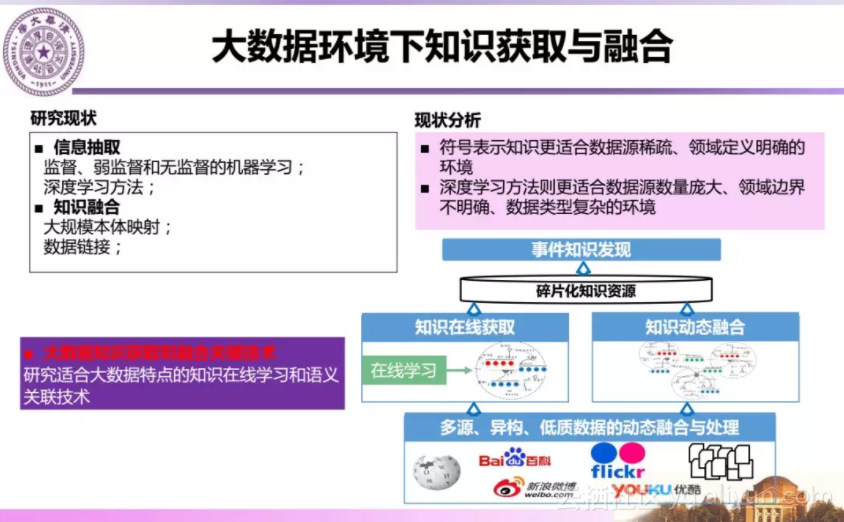
知识获取与融合方面,主要研究知识获取和语义关联技术。目前符号表示的知识是稀疏的,如何在知识稀疏和大数据环境下研究知识引导的知识获取方,获得大规模和高精度的知识是我们面临的挑战。
在知识计算和推理方面,当前基于符号的推理虽然有一些很好的推理工具,但是大规模知识推理效率还很受约束。深度学习或概率的推理方法方便计算但是难以解释。大数据环境下知识计算和推理需要研究深度学习和逻辑规则相结合的知识推理和演化方法,以提升新知识发现的能力。
知识工程的最终目标是实现知识驱动的个性化智能服务。以知识图谱关联和分析用户行为,通过情景感知分析用户需求,以提供不同形式的个性化服务如知识导航、语义搜索和问答等。
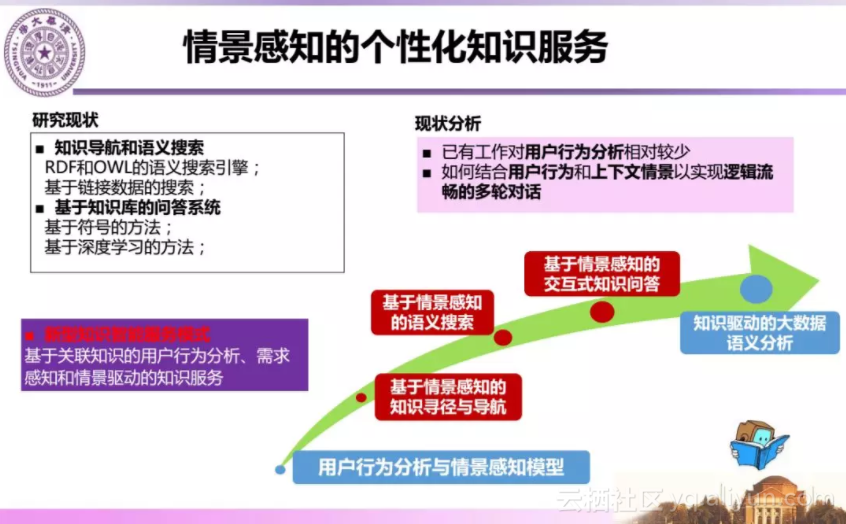
知识工程发展趋势可以归纳为四个方面。

四、我们的相关工作
下面首先介绍我们实验室在ACL2017上发表论文基于实体提及表示学习的实体链接工作。实体链接是知识图谱中的基础研究问题。有两个挑战,一是文本中同一个实体会有多个提及形式,例如独立日可以用Independence Day,也可以July First。二是同一个短语可能会对应不同的实体,独立日有可能指电影,也可能是节日。因此,组成实体提及的词或者短语具有多义性。
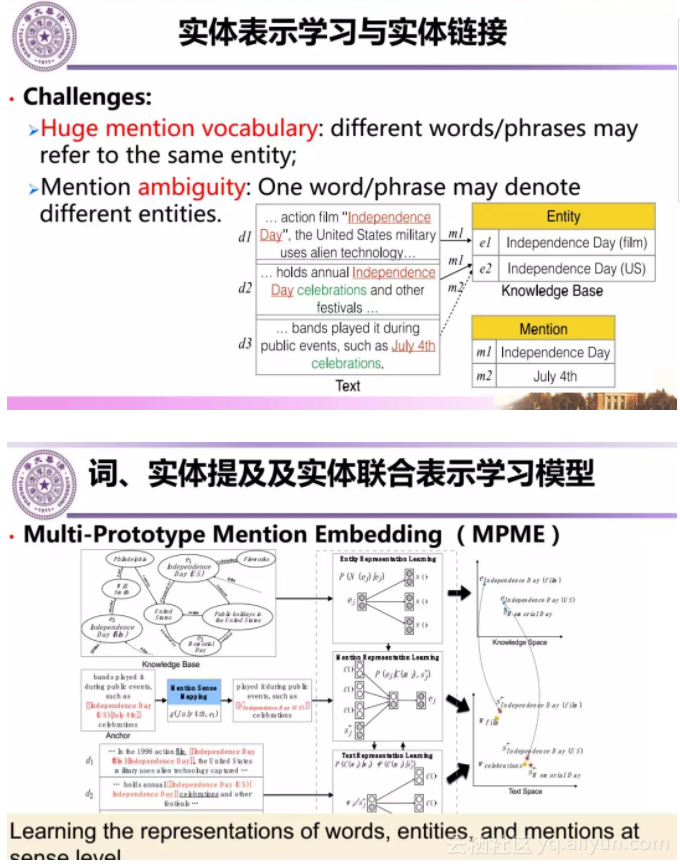
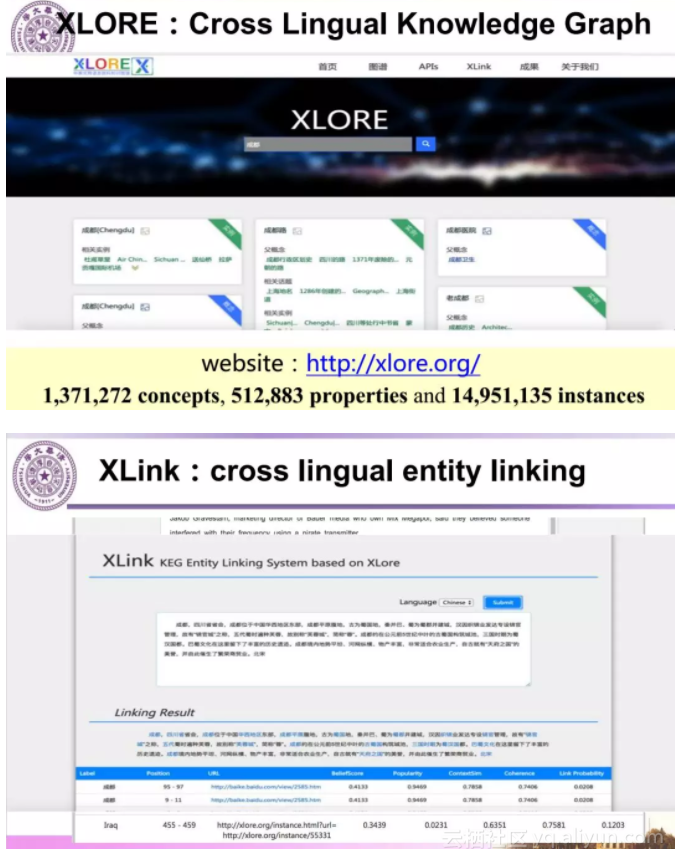
我们提出一种词、实体提及和实体的联合表示学习模型,学习实体提及不同语义的向量表示,实现了基于实体提及的无监督实体链接方法,取得了高精度的实体链接结果。以此为主要技术研制实现的跨语言实体链接工具XLink已经应用于我们开发的跨语言知识图谱系统XLORE中,并提供中英文文本的实体链接服务。
另一项工作,是我们实验室唐杰主持的从2006年就开始上线运行的科技大数据的挖掘和服务平台AMiner。AMiner目标一是建立科技领域知识图谱,二是对研究者进行画像,获取研究者兴趣和研究者信息,最终实现知识推荐等智能服务。
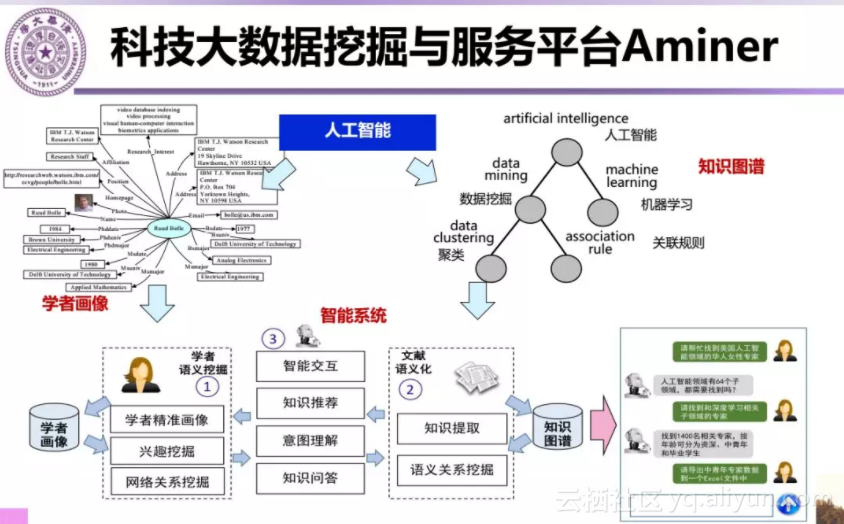
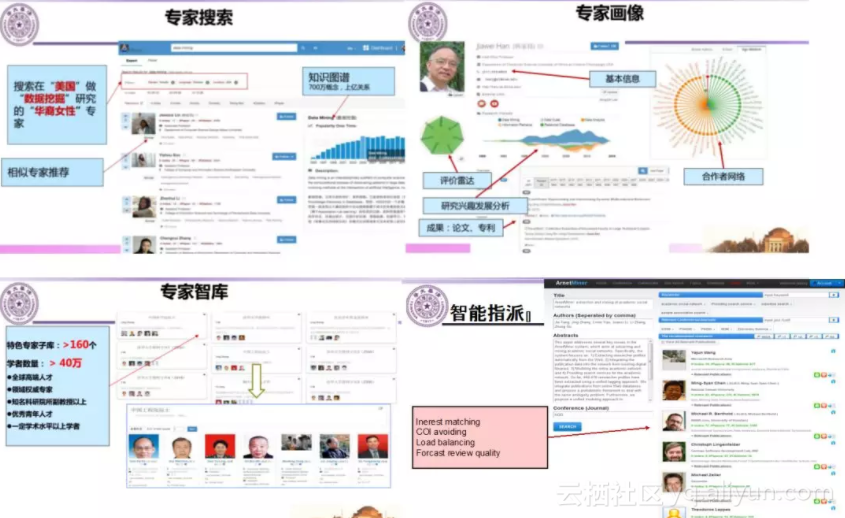
Aminer在专家搜索方面利用专家结构化信息提供精细化的搜索服务。例如输入“美国”、“数据挖掘”和“华裔女性”就能得到满足用户需求的结果。Aminer 还可以通过专家基本信息、研究成果等进行专家画像,做研究者研究兴趣的演化分析;可以根据用户需求动态建立全球人才分布地图;可以做会议影响力分析;提供论文、研究报告评审专家推荐等。AMiner还建立了100余个专家智库。
总结汇报内容。首先,从数据、信息、知识到智能概念及关系看知识工程的在机器智能中重要性;其次,知识图谱将互联网信息表达成更接近人类认知世界的形式,可以将互联网内容从符号转化为计算机可理解和计算的语义信息,可以更好地理解互联网内容;然后,知识工程从大数据中挖掘知识,可以弥合大数据机器学习底层特征与人类认知的鸿沟;最后,构建大数据环境下由数据向知识转化的知识引擎,是实现从互联网信息服务到知识服务新业态的核心技术。

原文发布时间为:2017-12-28
本文作者:李涓子
