文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/。
1.前言
在10g之前,传统的导出和导入分别使用EXP工具和IMP工具,从10g开始,不仅保留了原有的EXP和IMP工具,还提供了数据泵导出导入工具EXPDP和IMPDP。所以在11G的倒库和入库方式中,我们也有两种方式可以选择:传统模式和数据泵模式。
传统模式又分为:常规导入导出和直接导入导出。
下面以导出数据为例,分别介绍各自导出原理。
1.1简述各导入导出方式的原理
1.1.1常规导出原理
传统路径模式使用SQL SELECT语句抽取表数据。数据从磁盘读入到buffer cache缓冲区中,行被转移到评估缓冲区。在此之后根据SQL表达式,将记录返回给导出客户端,然后写入到dump文件。
常规导出的例子:exp zhejiang/zhejiang file=/data1/zj_regular.dmp buffer=20480000
1.1.2直接导出
直接导出模式,数据直接从磁盘中读取到导出session的PGA中,行被直接转移到导出session的私有缓冲区,从而跳过SQL命令处理层。 避免了不必要的数据转换。最后记录返回给导出客户端,写到dump文件。
直接导出的例子:exp zhejiang/zhejiang file=/data1/zj_direct.dmp buffer=20480000 recordlength=65535 direct=y。
1.1.3数据泵导出
数据泵方式是EXP方式的加强版,其原理类似,但是它的导出要借鉴服务器端的数据库目录。
1.2传统模式和数据泵模式的对比
1.2.1传统模式的优点
EXP和IMP是客户段工具程序,它们既可以在客户端使用,也可以在服务器段使用。
而EXPDP和IMPDP是服务端的工具程序,它们只能在ORACLE服务端使用,不能在客户端使用。
1.2.2数据泵模式的优点
数据泵导出数据的时间更短,而且导出的数据文件大小更小。
以下表格为我将网友的一个测试进行的统计:
| 类型 |
例子(导出40G左右的数据) |
| 传统模式(直接导出) |
18分钟 |
| 数据泵模式 |
14分钟,且导出的文件比传统模式小1.5G |
1.3 注意
IMP只适用于EXP导出文件,不适用于EXPDP导出文件;IMPDP只适用于EXPDP导出文件,而不适用于EXP导出文件。
1.4 小结
由上面对比可见,在实际操作中,我们在服务器端选择数据泵方式导入数据会更快一些。下面我主要介绍数据泵方式的导入和导出。
2.数据泵导出数据的流程
2.1创建逻辑目录并授权
创建逻辑目录“EXPDP_DIR”并将其映射到物理路径“D:\DBbak”下,在PL/SQL下面执行语句:Create or replace directory expdp_dir as 'D:\DBbak';
执行完后,要在对应的硬盘目录下创建该文件夹。
可以通过SQL查询是否成功创建逻辑目录,Select * from dba_directories,可以看到如下结果:
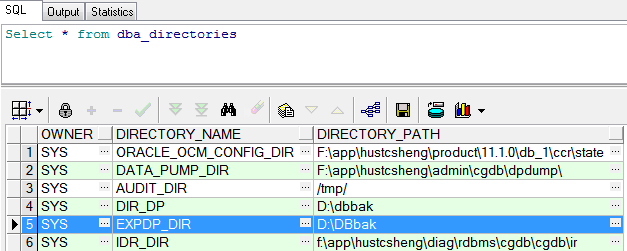
最后,再给创建的目录赋予权限:
Grant read,write on directory EXPDP_DIR to Public;
2.2执行导出操作
建立expdp.bat文件,文件内容为:Expdp sccot/tiger@testDB directory=expdp_dir dumpfile =STDCG _201501.dmp logfile= STDCG _201501.log;执行该bat;
因为是导出所有数据,所以没有设置tables| schemas| tablespaces。
导出成功后,导出的数据会自动放在之前设置的Expdp_Dir文件夹下。
3.数据泵导入数据的流程
3.1 创建数据库实例等基本操作
a.创建数据库stdcg,包含SYS和SYSTEM两个用户
b.用SYS登陆PL/SQL->File->Open->SQL script执行创建表空间sql脚本。需要注意的就是修改脚本中的路径:
DATAFILE 'F:\app\DELL\oradata\stdcg\DLGIS.DBF'(红色部分是本地数据库的路径)
c.执行创建用户脚本:包含dlsys、dlmis、dlinit、dlgis、sde、mms、umstat、ulog用户。
3.2创建逻辑目录并授权
如2.2中所描述的,这里直接给出语句:
Create or replace directory expdp_dir as 'd:\DBbak';
Grant read,write on directory expdp_dir to public;
不过多出了这样一个步骤:在D盘建立文件夹DBbak 后,需要将数据库的导出文件:STDCG _201501.DMP和STDCG _201501.log 一起拷贝到D:\DBbak目录下。
3.3执行导入操作
建立impdp.bat文件,文件中的内容为: impdp dlsys/dlsys@stdcg dumpfile= STDCG _201501.dmp logfile= STDCG _201501_EXP.log。运行该bat文件。
同样,因为是全库导入,所以没有使用tables| schemas| tablespaces来进行导入内容设置。
4.11g数据导入10g的库中
4.1 降版本导出然后导入
首先要做与一般数据泵导出时相同的操作,即创建逻辑目录: Create or replace directory expdp_dir as 'D:\DBbak';
然后再导出数据时,sql命令上要加上一个version控制即可:
expdp sccot/tiger@testDB dumpfile=stdcg10g.dmp directory= expdp_dir version=10.0.2。
导出后,再将导出的dmp文件导入到10g的库中即可。
4.2容易出现的问题
目前在江北项目和烟台项目中均做了如下操作:shp数据首先通过SDE导入到了11g的数据库中,由于现场数据库突然需要降级,然后将11g的数据又重新导入导出到10g中。但是,两个现场都不分别出现了不同的问题。
江北现场的问题是,在catalog里能够直连到10g上Oracle,也能看到各空间数据。但是,在arcmap中添加该数据库中的空间数据,图层渲染时会出现SDE内部错误,导致图层无法显示。
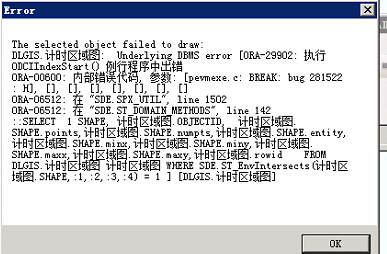
而烟台现场,则直接出现了直连数据库不定时失效问题:
测试可以连接:
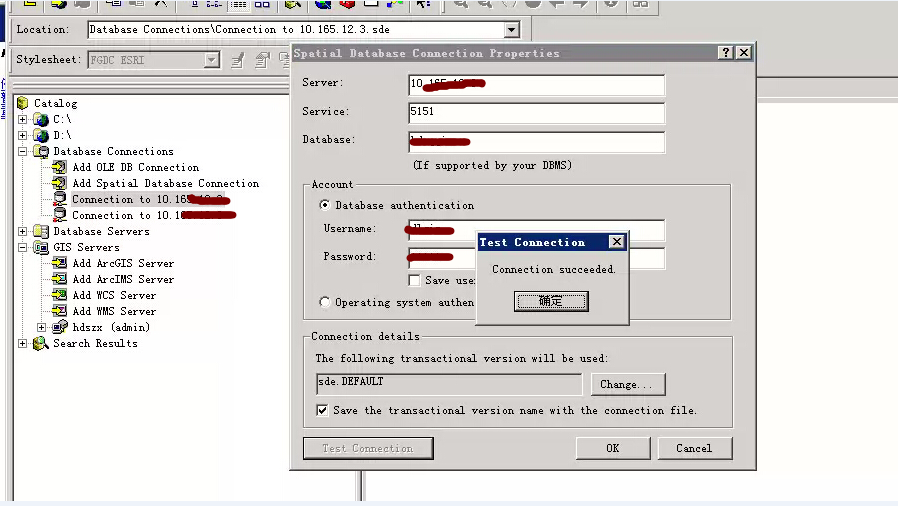
点OK后又不能连接:
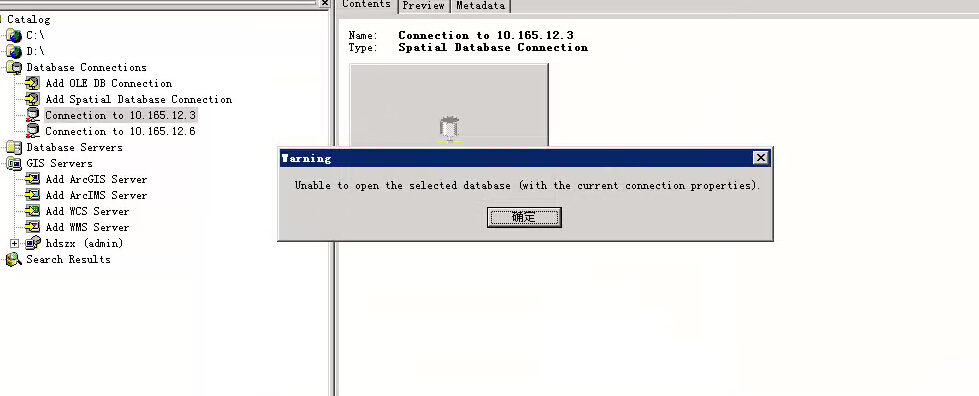
4.3解决方法及分析
4.3.1解决方法
将空间数据所在的DLGIS和SDE用户删除,重新通过SQL生成这两个用户以及先关表结构后。手动通过catalog直连到数据库上,然后手动导入图层,解决上述问题。
4.3.2 问题分析
猜想为11g数据转成10g数据时可能某些空间信息表被改变或者破坏,不再符合arcgis10.0的连接规范等。造成了sde不稳定或者sde内部错误。
