上一节我们通过爬虫工具爬取了近七万条二手房数据,那么这一节就对这些数据进行预处理,也就是所谓的ETL(Extract-Transform-Load)
一.ETL工具的必要性
数据分析的前提是数据清洗。不论如何高大上的算法,遇到错误数据,一个异常抛出来,绝对尸横遍野。而你不能指望核心算法为你处理错误或者短缺的数据。所以,数据清洗(ETL)就变得必不可少了。 如果数据分析是炒菜阶段,那么清洗就是洗菜,绝对是非常重要的一环。
而实际上,ETL工具可以很简单,也可以很复杂。简单到只需要把字符串转换为数字或者提供正则表达式。而复杂的ETL需要建立完整的错误日志机制,智能处理,自动汇总,还要做成工作流,脚本等复杂的形式。我决定做一个折中,提供最需要和差不多够用的功能。如果真有对ETL特别强烈而复杂的需求,那就只能借助专业的ETL工具了。
二.ETL插件
在本系统中,ETL以插件的形式存在,可供系统进行调用。这些ETL工具包括了常见的场景:
- 正则表达式提取
- 数据类型转换,包括时间格式等
- 随机数和范围数生成
- 数据分割,排序和筛选
- 噪声生成
- 字符串转数字编号
- 脚本数据
- 高级的模块 如 分词,文本情感分析等
同时所有的模块都可以支持二次扩展。可为了新的场景增加新的模块。 模块分为两类:
- 无监督工具:不需要之前的数据,直接生成新数据,如噪声产生器
- 有监督工具:需根据之前的数据生成,如正则提取
这些ETL插件可以形成一个处理队列,以队列的形式依次处理数据,形成职责链。这样就能应对绝大多数的ETL需求。
三. 使用介绍
下面,我们就以北京房价样例数据为例,进行ETL清洗。这些数据爬虫来自于网络,具体的爬取过程可参考前一节内容。
1. 数据导入和观察
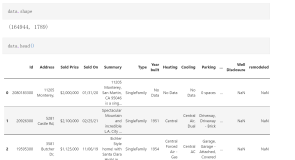
首先在数据管理器上点击“导入”按钮,导入XML数据文件,如下图所示:

之后可以普通列表的形式,查看这些数据:

会发现这些数据非常有规律。我们可制定如下方案:
- 筛选出正常的数据,因为有些数据是残缺的,比如“面积”一栏是空的。
- 其价格是XXXXX元/平米,为了进行统计,需要通过正则进行提取
- “属性3” 楼层数,可通过/ ,进行分割,取第二个项就好,最后一项是板楼或塔楼
- 在“属性3”中,可通过正则匹配提取年份
- 可在“坐标”一项中,通过分割,方便地提取编号,地理位置,所在小区和其他信息。
- 其他…
2.编写数据筛选脚本
首先进行数据筛选,将“数据筛选”插件拖入算法框中:

同时进行配置,为了方便,我们仅提取前1000条数据作为分析目标。

最重要的是,编写筛选的自定义函数脚本。与C#的语法相同:

点击开始处理,即可筛选出满足条件的前1000条数据。
3.进行ETL配置:
与上一步类似,将“数据生成与预处理”模块拖到算法管理器中。
将该模块的数据源,选为“全部”:

点击命令列,可对ETL所需的插件进行配置:

集合编辑器中,列举了系统加载的所有ETL插件,我们首先将价格提取出来:

选择原始列名,填入新列名,如果不勾选“添加到新列”,则原始数据就会被覆盖。同时填写正则表达式 \d+ ,用于提取价格中的房价。同时,将目标类型选择为INT,转换完成后,数据的类型就会变为INT
类似的,可提取建设年份。

由于转换后,建设年份为STRING类型,可再添加一个字符串转时间的工具,方便转换为DateTime,直接将原有的数据覆盖就好。

接下来提取地理坐标: 观察这些坐标,同样可以使用正则匹配,此处从略。
接下来是所在的片区,它位于“坐标”这一属性中。使用正则匹配并不方便,因此采用数列分割的方法,即通过字符对该属性进行分割,提取出固定位置的项。通过观察, 可通过符号,进行分割,正好位于第4项

类似的,可以提取小区名称,与所在行政区的唯一区别在于匹配编号,要填2
最终完成的ETL流程如下图所示:

这些ETL插件会顺次执行。如果一个插件的结果依赖于前一个插件,则一定要排在依赖插件的后边。
之后点击开始处理,ETL流程即可启动,所有的错误日志都会保存到一个专门的数据集中,用于再次分析和处理。这次处理没有错误,系统提示ETL流程成功结束,下面就是经过ETL后得到的新列:

为了保险起见,我们将这次加载的所有设置保存为一个任务,名字为”ETL清洗任务”,如果遇到同样的数据,可以进行相同的任务,而无需进行再次配置。

可以在生成的系统配置文件中,看到此次任务所保存的XML文件:
<Doc Name="ETL数据清洗任务" Description="任务描述" Group="">
<Nodes>
<Children X="-2.01" Y="0" Z="0" Group="0" Key="数据筛选_1" Weight="1">
<Data Collection="全部" Name="数据筛选" NewDataSetName="" ScriptCode="return String.IsNullOrEmpty(item['价格']) ; // 1表示筛选该数据,否则表示不筛选" CanRemove="True" Start="0" End="1000" Layer="0" />
</Children>
<Children X="3" Y="0" Z="0" Group="1" Key="数据生成和预处理_2" Weight="1">
<Data Collection="全部" Name="数据生成和预处理" Size="1001" Layer="0">
<Children Type="正则过滤器" CollumName="价格" NewCollumName="新价格" IsAddNewCollum="True" TargetDataType="INT" ScriptCode="\d+" Index="0" />
<Children Type="正则过滤器" CollumName="属性3" NewCollumName="年份" IsAddNewCollum="True" TargetDataType="STRING" ScriptCode="\d{4}" Index="0" />
<Children Type="字符串转时间" CollumName="年份" NewCollumName="" IsAddNewCollum="False" TargetDataType="DATETIME" Format="yyyy" />
<Children Type="数列分割" CollumName="坐标" NewCollumName="片区" IsAddNewCollum="True" TargetDataType="STRING" SplitChar="," Index="3" SplitPause="SplitPause" />
<Children Type="数列分割" CollumName="坐标" NewCollumName="小区名" IsAddNewCollum="True" TargetDataType="STRING" SplitChar="," Index="2" SplitPause="SplitPause" />
<Children Type="正则过滤器" CollumName="坐标" NewCollumName="lag" IsAddNewCollum="True" TargetDataType="DOUBLE" ScriptCode="\d{2}.\d+" Index="0" />
<Children Type="正则过滤器" CollumName="坐标" NewCollumName="Lng" IsAddNewCollum="True" TargetDataType="DOUBLE" ScriptCode="\d{3}.\d+" Index="0" />
</Data>
</Children>
</Nodes>
<Paths />
</Doc>三.总结
本节主要介绍了如何使用该工具进行ETL清洗,下一节我们将正式进入数据分析的流程。敬请期待。