前言
最近由于工作原因,更新慢了一点,今天终于抽出一点时间给大家继续更新selenium系列,学习的脚本不能停止,希望小伙伴能多多支持。
本篇以百度设置下拉选项框为案例,详细介绍select下拉框相关的操作方法。
一、认识select
1.打开百度-设置-搜索设置界面,如下图所示
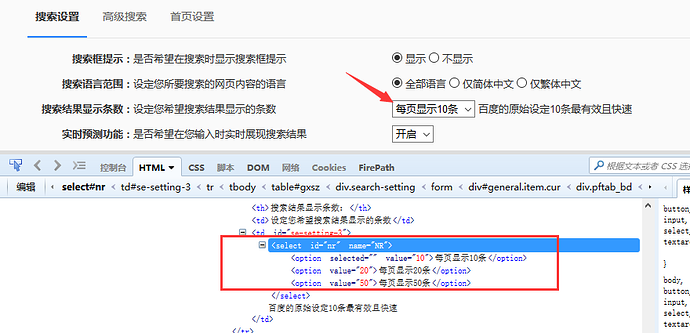
<select id="nr" name="NR">
3.选项有三个
<option selected="" value="10">每页显示10条</option>
<option value="20">每页显示20条</option>
<option value="50">每页显示50条</option>
二、二次定位
1.定位select里的选项有多种方式,这里先介绍一种简单的方法:二次定位
2.基本思路,先定位select框,再定位select里的选项
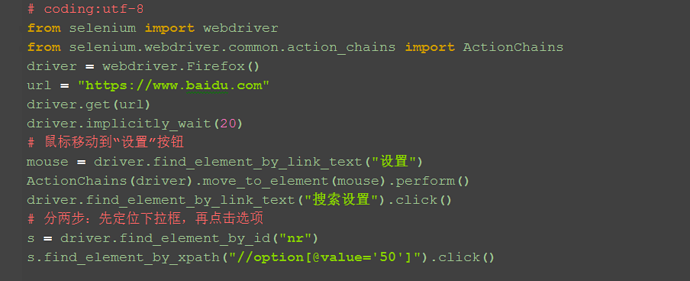
4.还有另外一种写法也是可以的,把最下面两步合并成为一步:
三、直接定位
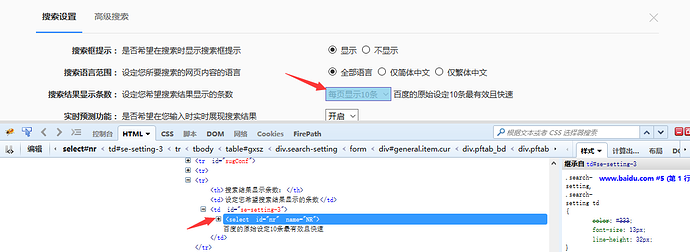
1.有很多小伙伴说firebug只能定位到select框,不能定位到里面的选项,其实是工具掌握的不太熟练。小编接下来教大家如何定位里面的选项。
2.用direbug定位到select后,下方查看元素属性地方,点select标签前面的+号,就可以展开里面的选项内容了。

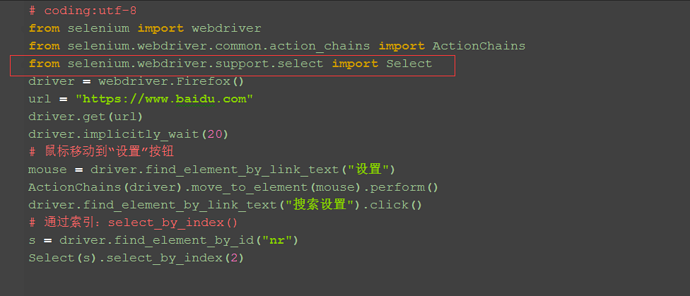
1.除了上面介绍的两种简单的方法定位到select选项,selenium还提供了更高级的玩法,导入Select模块。直接根据属性或索引定位。
2.先要导入select方法:
from selenium.webdriver.support.select import Select
1.Select模块里面除了index的方法,还有一个方法,通过选项的value值来定位。每个选项,都有对应的value值,如
<select id="nr" name="NR">
<option selected="" value="10">每页显示10条</option>
<option value="20">每页显示20条</option>
2.第二个选项对应的value值就是"20":select_by_value("20")
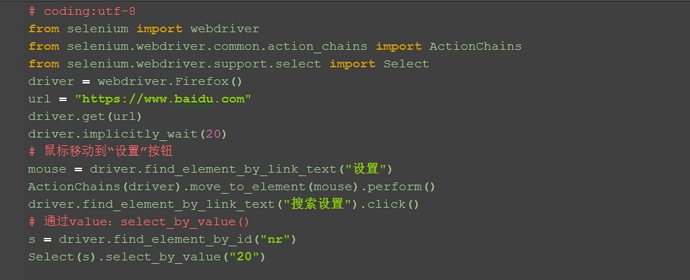
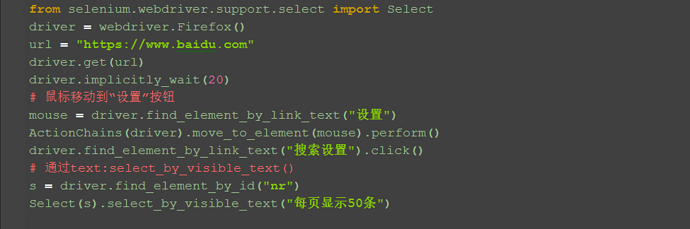
1.Select模块里面还有一个更加高级的功能,可以直接通过选项的文本内容来定位。
2.定位“每页显示50条”:select_by_visible_text("每页显示50条")
七、Select模块其它方法
1.select里面方法除了上面介绍的三种,还有更多的功能如下
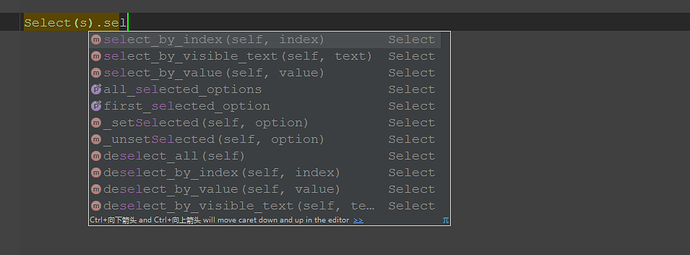
select_by_value() :通过value值定位
select_by_visible_text() :通过文本值定位
deselect_all() :取消所有选项
deselect_by_index() :取消对应index选项
deselect_by_value() :取消对应value选项
deselect_by_visible_text() :取消对应文本选项
first_selected_option() :返回第一个选项
all_selected_options() :返回所有的选项
八、整理代码如下:
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.select import Select
driver = webdriver.Firefox()
url = "https://www.baidu.com"
driver.get(url)
driver.implicitly_wait(20)
# 鼠标移动到“设置”按钮
mouse = driver.find_element_by_link_text("设置")
ActionChains(driver).move_to_element(mouse).perform()
driver.find_element_by_link_text("搜索设置").click()
# 通过text:select_by_visible_text()
s = driver.find_element_by_id("nr")
Select(s).select_by_visible_text("每页显示50条")
# # 分两步:先定位下拉框,再点击选项
# s = driver.find_element_by_id("nr")
# s.find_element_by_xpath("//option[@value='50']").click()
# # 另外一种写法
# driver.find_element_by_id("nr").find_element_by_xpath("//option[@value='50']").click()
# # 直接通过xpath定位
# driver.find_element_by_xpath(".//*[@id='nr']/option[2]").click()
# # 通过索引:select_by_index()
# s = driver.find_element_by_id("nr")
# Select(s).select_by_index(2)
# # 通过value:select_by_value()
# s = driver.find_element_by_id("nr")
# Select(s).select_by_value("20")
在学习过程中有遇到疑问的,可以加selenium(python+java) QQ群交流:646645429
《selenium+python高级教程》已出书:selenium webdriver基于Python源码案例
(购买此书送对应PDF版本)

