摘要
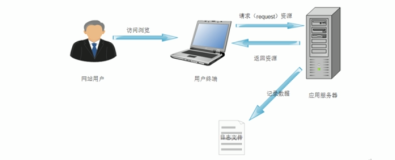
百度站长统计,一个不错的工具。各种信息也能超级详细的被记录下来,可以从下图上略知一二。但是实际上其详细程度远远不止如此。百度统计支持一级域名,以及二级域名的绑定。所以很方便。

但也不是对于所有的服务器都支持,比如我没有给服务器绑定域名,所以自然就没法用了。但是如果我还想获得一些访客的信息,怎么办呢?
拿我自己来说,使用PHP就不赖。当然了,其他的编程语言也是可以的。不过需要具体情况具体分析嘛。我的需求很简单,那就是记录一下访客是使用哪个操作系统,使用的哪个浏览器,在什么时间访问了我的哪些文件。
嗯,需求就是这样了。
header
header就相当于一个身份的标识。我们要查看的话也很简单,最简单的方式就是打开浏览器,按下F12。调出开发者工具。就可以看到了。
查看header

模拟header
写过Python爬虫程序的可能都会很熟悉啦。而且Python代码足够简洁,几行代码就可以完成一个简单的爬虫程序了。但是有很多网站会对爬虫程序进行“特殊照顾”,其中有一个就是针对header的处理。
因此,简单的代码是不能够保证一定可以获取的到服务器上相关的资源的。这个时候就需要让代码“伪装”一下了。做法呢也比较的简单,那就是手动的添加一个头信息。
比如下面的代码
#coding:utf8
import urllib2
import sys
headers = {
'Referer':'http://zhjw.dlut.edu.cn/',
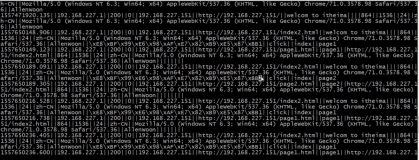
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.94 Safari/537.36'
}
req = urllib2.Request(url=sys.argv[1], headers=headers)
print urllib2.urlopen(req).read()
这就是一个最简单的模拟浏览器的“伪装”爬虫程序了。作用就是:
简单的将URL对应的资源下载下来,并标准显示(比如屏幕)。
大部分人(尤其是非专业的)可能不知道,点击了浏览器上一个超链接,或者填写了一个表单背后发生的故事。其实在这些简单操作的背后蕴含着复杂的智慧。其中就包含header 在http协议中不可取代的地位。
个人觉得称之为人类智慧的结晶也不为过。计算机本身的发展,离不开各行各业的共同进步。
php中的使用
刚才的话题有点跑偏了,现在继续讨论在PHP中对于Header的获取吧。我们最需要的就是通过PHP内置的一些超级变量$_SERVER来获取header中的用户代理信息。
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.94 Safari/537.36'别看这个值很随意,其实它却包含了作为客户端的你的很多信息。在PHP中使用下面的代码就可以获取得到了。
<?php
echo $_SERVER['HTTP_USER_AGENT'];
echo "<br />".$_SERVER ['REMOTE_ADDR'];
?>
运行结果:

IP接口
接口介绍
了解了如何获取客户端的简单的这些信息之后,基本上就可以满足正常的需求了。但是为了更进一步,获得用户的大致的位置,这里还是需要借助于接口(网上有很多免费的接口,可以方便的获取关于IP的详细的信息)。这里我暂且使用下面的这个接口吧。
通过一个get请求就可以获取得到IP对应的信息啦。返回的数据时JSON类型的,大致如下:

PHP访问接口并解析
在PHP中有好多的方法来访问一个接口。我这里大致的介绍两个吧,一个简单,一个略微复杂一点。
简易方式
不知道您有没有听说过这样的一个函数
string file_get_contents(url)
给个网址,仅仅需要这样一个函数就可以获取到数据了。而且是以字符串的形式进行返回。
略繁方式
下面讲一个在PHP中进行接口测试的最为常用,也比较正统一点的curl。看个小例子就明白了。
/**
* 根据 客户端IP 获取到其具体的位置信息
* @param unknown $ip
* @return string
*/
function get_address_by_ip($ip) {
$url = "http://ip.taobao.com/service/getIpInfo.php?ip=".$ip;
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_HEADER, 0);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
$info = curl_exec($curl);
curl_close($curl);
return $info;
}是不是贼简单。
解析JSON数据
既然已经获取到数据了,下一步就自然的是对获取到的数据进行解析。
还是看个小例子,就明白了。
$json_get = get_address_by_ip("一个公网IP");
$data = json_decode($json_get, true);需要注意的是json_decode函数的第二个参数设置为true,这是为了让php解释器根据获取到的字符串类型的数据解码为JSON对象。这样我们才能在代码中直接使用这个对象来做进一步的操作。
具体的获取JSON内部的数据就简单多了,说到这里,大家应该都懂了。也就不多说了吧。
记录器
万事俱备,下面就开始着手编码吧。
操作系统信息
下面通过PHP中的正则表达式做了简单的处理,虽然不能包含市面上所有的操作系统,但是大部分已经是足够啦。
/**
* 获取客户端类型,手机还是电脑,以及相应的操作系统类型。
*
* @param string $subject
*/
function get_os($agent) {
$os = false;
if (preg_match ( '/win/i', $agent ) && strpos ( $agent, '95' )) {
$os = 'Windows 95';
} else if (preg_match ( '/win 9x/i', $agent ) && strpos ( $agent, '4.90' )) {
$os = 'Windows ME';
} else if (preg_match ( '/win/i', $agent ) && preg_match ( '/98/i', $agent )) {
$os = 'Windows 98';
} else if (preg_match ( '/win/i', $agent ) && preg_match ( '/nt 6.0/i', $agent )) {
$os = 'Windows Vista';
} else if (preg_match ( '/win/i', $agent ) && preg_match ( '/nt 6.1/i', $agent )) {
$os = 'Windows 7';
} else if (preg_match ( '/win/i', $agent ) && preg_match ( '/nt 6.2/i', $agent )) {
$os = 'Windows 8';
} else if (preg_match ( '/win/i', $agent ) && preg_match ( '/nt 10.0/i', $agent )) {
$os = 'Windows 10'; // 添加win10判断
} else if (preg_match ( '/win/i', $agent ) && preg_match ( '/nt 5.1/i', $agent )) {
$os = 'Windows XP';
} else if (preg_match ( '/win/i', $agent ) && preg_match ( '/nt 5/i', $agent )) {
$os = 'Windows 2000';
} else if (preg_match ( '/win/i', $agent ) && preg_match ( '/nt/i', $agent )) {
$os = 'Windows NT';
} else if (preg_match ( '/win/i', $agent ) && preg_match ( '/32/i', $agent )) {
$os = 'Windows 32';
} else if (preg_match ( '/linux/i', $agent )) {
if(preg_match("/Mobile/", $agent)){
if(preg_match("/QQ/i", $agent)){
$os = "Android QQ Browser";
}else{
$os = "Android Browser";
}
}else{
$os = 'PC-Linux';
}
} else if (preg_match ( '/Mac/i', $agent )) {
if(preg_match("/Mobile/", $agent)){
if(preg_match("/QQ/i", $agent)){
$os = "IPhone QQ Browser";
}else{
$os = "IPhone Browser";
}
}else{
$os = 'Mac OS X';
}
} else if (preg_match ( '/unix/i', $agent )) {
$os = 'Unix';
} else if (preg_match ( '/sun/i', $agent ) && preg_match ( '/os/i', $agent )) {
$os = 'SunOS';
} else if (preg_match ( '/ibm/i', $agent ) && preg_match ( '/os/i', $agent )) {
$os = 'IBM OS/2';
} else if (preg_match ( '/Mac/i', $agent ) && preg_match ( '/PC/i', $agent )) {
$os = 'Macintosh';
} else if (preg_match ( '/PowerPC/i', $agent )) {
$os = 'PowerPC';
} else if (preg_match ( '/AIX/i', $agent )) {
$os = 'AIX';
} else if (preg_match ( '/HPUX/i', $agent )) {
$os = 'HPUX';
} else if (preg_match ( '/NetBSD/i', $agent )) {
$os = 'NetBSD';
} else if (preg_match ( '/BSD/i', $agent )) {
$os = 'BSD';
} else if (preg_match ( '/OSF1/i', $agent )) {
$os = 'OSF1';
} else if (preg_match ( '/IRIX/i', $agent )) {
$os = 'IRIX';
} else if (preg_match ( '/FreeBSD/i', $agent )) {
$os = 'FreeBSD';
} else if (preg_match ( '/teleport/i', $agent )) {
$os = 'teleport';
} else if (preg_match ( '/flashget/i', $agent )) {
$os = 'flashget';
} else if (preg_match ( '/webzip/i', $agent )) {
$os = 'webzip';
} else if (preg_match ( '/offline/i', $agent )) {
$os = 'offline';
} else {
$os = '未知操作系统';
}
return $os;
}获取浏览器信息
同理,下面打函数可以简单的解析出访客的浏览器相关的信息。
**
* 获取 客户端的浏览器类型
* @return string
*/
function get_broswer($sys){
if (stripos($sys, "Firefox/") > 0) {
preg_match("/Firefox\/([^;)]+)+/i", $sys, $b);
$exp[0] = "Firefox";
$exp[1] = $b[1]; //获取火狐浏览器的版本号
} elseif (stripos($sys, "Maxthon") > 0) {
preg_match("/Maxthon\/([\d\.]+)/", $sys, $aoyou);
$exp[0] = "傲游";
$exp[1] = $aoyou[1];
} elseif (stripos($sys, "MSIE") > 0) {
preg_match("/MSIE\s+([^;)]+)+/i", $sys, $ie);
$exp[0] = "IE";
$exp[1] = $ie[1]; //获取IE的版本号
} elseif (stripos($sys, "OPR") > 0) {
preg_match("/OPR\/([\d\.]+)/", $sys, $opera);
$exp[0] = "Opera";
$exp[1] = $opera[1];
} elseif(stripos($sys, "Edge") > 0) {
//win10 Edge浏览器 添加了chrome内核标记 在判断Chrome之前匹配
preg_match("/Edge\/([\d\.]+)/", $sys, $Edge);
$exp[0] = "Edge";
$exp[1] = $Edge[1];
} elseif (stripos($sys, "Chrome") > 0) {
preg_match("/Chrome\/([\d\.]+)/", $sys, $google);
$exp[0] = "Chrome";
$exp[1] = $google[1]; //获取google chrome的版本号
} elseif(stripos($sys,'rv:')>0 && stripos($sys,'Gecko')>0){
preg_match("/rv:([\d\.]+)/", $sys, $IE);
$exp[0] = "IE";
$exp[1] = $IE[1];
}else {
$exp[0] = "未知浏览器";
$exp[1] = "";
}
return $exp[0].'('.$exp[1].')';
}
核心
最后就是将获取到的这些信息进行二次处理,该用于查找地理位置的就去查找地理位置,该被记录到文件中的就记录到文件中。
<?php
function clientlog() {
require_once './getclientinfo.php';
$useragent = $_SERVER ['HTTP_USER_AGENT'];
$clientip = $_SERVER ['REMOTE_ADDR'];
$client_info = get_os ( $useragent ) . "---" . get_broswer ( $useragent );
$rawdata_position = get_address_by_ip ( $clientip );
$rawdata_position = json_decode($rawdata_position, true);
$country = $rawdata_position['data']['country'];
$province = $rawdata_position['data']['region'];
$city = $rawdata_position['data']['city'];
$nettype = $rawdata_position['data']['isp'];
$time = date ( 'y-m-d h:m:s' );
$data = "来自{$country} {$province} {$city }{$nettype} 的客户端: {$client_info},IP为:{$clientip},在{$time}时刻访问了{$_SERVER['PHP_SELF']}文件!\n";
echo $data;
// $filename = "./log.log";
// // if (! file_exists ( $filename )) {
// // fopen ( $filename, "w+" );
// // }
// file_put_contents ( $filename, $data, FILE_APPEND );
}
clientlog();这里仅仅是演示一下,实际上需要完善一下。
如果有需要的话,可以在下面评论中留下邮箱,或者私信我来获取源码。
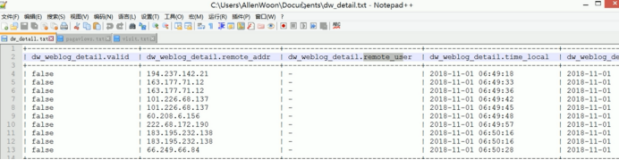
最终效果
最后,来看一下部署到服务器上的实验效果吧。

可能有些IP地址对于这个接口并不适用,所以未能正确的解析出来。不过大部分的还是可以滴。
总结
对比与百度的站长统计,我觉得他们做的无非是更加的详细了。而且作为国内搜索中做的最大的,其用户群体也是一个不小的数字。所以不知不觉的我们很多信息都会被记录走了。所以他们可以做的很详细,甚至精确到了性别,年龄。
凡事也都是立于乎微,也许在不知不觉中,日志信息会帮到你一个大忙。
( ⊙ o ⊙ )啊!不知道为啥今天这篇博客乱糟糟的,自己看着都蓝瘦。不出意外的话,应该是2016年最后一篇博客了。这样草率的收尾真的是有点难为情呢。
算了,就这样吧,不改了。也许,正好有人喜欢这种“乱式佳人”呢,(^__^) 嘻嘻……