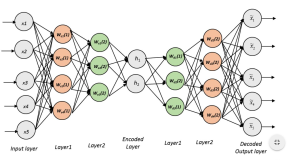
变分自编码器(Variational Autoencoder, VAE)通俗教程
转载自: http://www.dengfanxin.cn/?p=334&sukey=72885186ae5c357d85d72afd35935fd5253f8a4e53d4ad672d5321379584a6b6e02e9713966e5f908dd7020bfa0c555f
1. 神秘变量与数据集
现在有一个数据集DX(dataset, 也可以叫datapoints),每个数据也称为数据点。
X是一个实际的样本集合,我们假定这个样本受某种神秘力量操控,但是我们也无从知道这些神秘力量是什么?那么我们假定这股神秘力量有n个,起名字叫power1,power2,…,powern吧,他们的大小分别是z1,z2,…,zn,称之为神秘变量表示成一个向量就是
z也起个名字叫神秘组合。
一言以蔽之:神秘变量代表了神秘力量的神秘组合关系。
用正经的话说就是:隐变量(latent variable)代表了隐因子(latent factor)的组合关系。
这里我们澄清一下隶属空间,假设数据集DX是m个点,这m个点也应该隶属于一个空间,比如一维的情况,假如每个点是一个实数,那么他的隶属空间就是实数集,所以我们这里定义一个DX每个点都属于的空间称为XS,我们在后面提到的时候,你就不再感到陌生了。
神秘变量z可以肯定他们也有一个归属空间称为ZS。
下面我们就要形式化地构造X与Z的神秘关系了,这个关系就是我们前面说的神秘力量,直观上我们已经非常清楚,假设我们的数据集就是完全由这n个神秘变量全权操控的,那么对于X中每一个点都应该有一个n个神秘变量的神秘组合zj来神秘决定。
接下来我们要将这个关系再简化一下,我们假设这n个神秘变量不是能够操控X的全部,还有一些其他的神秘力量,我们暂时不考虑,那么就可以用概率来弥补这个缺失,为什么呢?举个例子,假设我们制造了一个机器可以向一个固定的目标发射子弹,我们精确的计算好了打击的力量和角度,但由于某些难以控制的因素,比如空气的流动,地球的转动导致命中的目标无法达到精准的目的,而这些因素可能十分巨大和繁多,但是他们并不是形成DX的主因素,根据大数定理,这些所有因素产生的影响可以用高斯分布的概率密度函数来表示。它长这样:
p(x|μ,σ2)=12π√σe−12(x−μσ)2
当μ=0时,就变成了这样:
p(x|σ2)=12π√σe−x22σ2
这是一维高斯分布的公式,那么多维的呢?比较复杂,推导过程见知乎,长这样: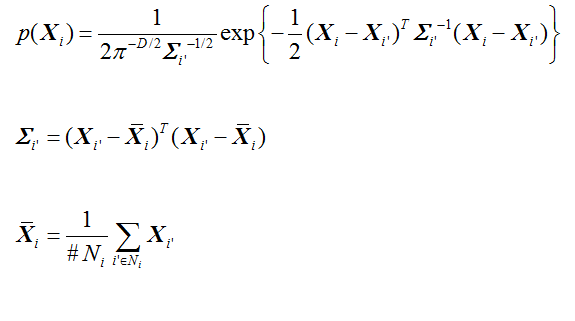
不管怎样,你只要记住我们现在没有能力关注全部的神秘变量,我们只关心若干个可能重要的因素,这些因素的分布状况可以有各种假设,我们回头再讨论他们的概率分布问题,我们现在假定我们对他们的具体分布情况也是一无所知,我们只是知道他们处于ZS空间内。
前面说到了一个神秘组合,如果一个数据集X对应的神秘组合完全一样,那么这个数据集就是一个单一的分类数据集,如果是多个,那么就是多分类数据集,但如果是一个连续的组合数据,那么就是一个有点分不清界限的复杂数据集,就好比,我们这个数据集是一条线段的集合,线段的长度是唯一的神秘变量,那么只要长度在一个范围内连续变化,那么这个集合里的线段你就会发现分散的很均匀,你几乎没有办法区分开他们,也没法给他们分成几类,但如果这个长度值只能选择1,3,5,那么当你观察这个数据集的时候,你会发现他们会聚在三堆儿里。如果这个线段的生成完全依靠的是计算机,那么每一堆儿都是完全重合的,但如果是人画的,就可能因为误差,没法完全重合,这没法重合的部分就是我们说的其他复杂因素,我们通常用一个高斯分布来把它代表了。好,我们已经基本清晰了,我们该给这个神秘组合一个形式化的描述了。
假设有两个变量,z∈ZS 和 x∈XS,存在一个确定性函数族f(z;θ),族中的每个函数由θ∈Θ唯一确定,f:ZS×Θ→XS,当θ固定,z是一个随机变量(概率密度函数为Pz(z))时,那么f(z;θ)就是定义在XS上的随机变量x,对应的概率密度函数可以写成g(x)。
那么我们的目标就是优化θ从而寻找到一个f,能够是随机变量x的采样和X非常的像。这里需要注意一下,x是一个变量,DX是已经现成的数据集,x不属于DX,我特意将名字起的有区分度。
这样,f就是那个神秘力量通道,他把这些神秘力量的力度,通过f变成了x变量,而这个x变量就是与数据集DX具有直接关系的随机变量。
设一个数据集为DX,那么这个数据集存在的概率为Pt(DX),则根据贝叶斯公式有:
其中,Pxz(DX|z;θ)是我们新定义的概率密度函数,我们前面知道f是将z映射成x,而x又与DX有某种直接的关系,这个直接关系可以表示成Px(DX|x),那么Pt(DX)=∫Px(DX|x)g(x)dx
这样我们就直接定义个Pxz(DX|z;θ) 来替换Px(DX|x)g(x),从而表示z与DX的关系了。
好了,其实公式(1)就是我们的神秘力量与观察到的数据集之间的神秘关系,这个关系的意思我们直白的说就是:当隐秘变量按照某种规律存在时,就非常容易产生现在我们看到的这个数据集。那么,我们要做的工作就是当我们假定有n个神秘力量时,我们能够找到一个神奇的函数f,将神秘力量的变化转化成神奇的x的变化,这个x能够轻而易举地生成数据集DX。
从上面的描述里面我们看到,f是生成转换函数,公式(1)不表示这种转换关系,而是这种关系的最大似然估计(maximum likelihood),它的意思是找到最有可能生成DX这个数据集的主导函数f。
接下来我们回到讨论Pxz(DX|z;θ)这个概率密度函数上来,我们前面说过,如果z是全部的神秘力量,那么它产生的变量x就一定固定的,即当z取值固定时,x取值固定,但是现实中还有很多其他的因素,因而x的取值还与他们有关,他们的影响力,最终反映成了高斯函数,所以我们大胆假定Pxz是一个高斯分布的概率密度函数,即Pxz(DX|z;θ)=N(DX|f(x;θ),σ2∗I)
注意z的分布我们依然是未知的。
假定我们知道z现在取某一个或几个特定值,那么我们就可以通过Gradient Descent来找到一个θ尽量满足z能够以极高的概率生成我们希望的数据集DX。再一推广,就变成了,z取值某一范围,但去几个特定值或某一取值范围是就面临z各种取值的概率问题,我们回头再讨论这个棘手的问题,你现在只要知道冥冥之中,我们似乎可以通过学习参数θ寻找最优解就行了。
OK,我们还要说一个关键问题,就是我们确信f是存在的,我们认为变量与神秘变量之间的关系一定可以用一个函数来表示。
2. 变分自编码器(VAE)
本节,我们探讨如何最大化公式(1)。首先,我们要讨论怎样确定神秘变量z,即z应该有几个维度,每个维度的作用域是什么?更为较真的,我们可能甚至要追究每一维度都代表什么?他们之间是不是独立的?每个维度的概率分布是什么样的?
如果我们沿着这个思路进行下去,就会陷入泥潭,我们可以巧妙地避开这些问题,关键就在于让他们继续保持“神秘”!
我们不关心每一个维度代表什么含义,我们只假定存在这么一群相互独立的变量,维度我们也回到之前的讨论,我们虽然不知道有多少,我们可以假定有n个主要因素,n可以定的大一点,比如假设有4个主因素,而我们假定有10个,那么最后训练出来,可能有6个长期是0。最后的问题需要详细讨论一下,比较复杂,就是z的概率分布和取值问题。
既然z是什么都不知道,我们是不是可以寻找一组新的神秘变量w,让这个w服从标准正态分布N(0,I)。I是单位矩阵,然后这个w可以通过n个复杂函数,转换成z呢?有了神经网络这些也是可行的,假设这些复杂函数分别是h1,h2,…,hn,那么有z1=h1(w1),…,zn=hn(wn)。而z的具体分布是什么,取值范围是多少我们也不用关心了,反正由一个神经网络去算。回想一下P(DX|z;θ)=N(DX|f(z;θ),σ2×I),我们可以想象,如果f(z;θ)是一个多层神经网络,那么前几层就用来将标准正态分布的w变成真正的隐变量z,后面几层才是将z映射成x,但由于w和z是一一对应关系,所以w某种意义上说也是一股神秘力量。就演化成w和x的关系了,既然w也是神秘变量,我们就还是叫回z,把那个之前我们认为的神秘变量z忘掉吧。
好,更加波澜壮阔的历程要开始了,请坐好。
我们现在已经有了
Pz(z)=N(0,I),
Pxz(DX|z;θ)=N(DX|f(x;θ),σ2∗I),
Pt(DX)=∫Pxz(DX|z;θ)Pz(z)dz,
我们现在就可以专心攻击f了,由于f是一个神经网络,我们就可以梯度下降了。但是另一个关键点在于我们怎么知道这个f生成的样本,和DX更加像呢?如果这个问题解决不了,我们根本都不知道我们的目标函数是什么。
3. 设定目标函数
我们先来定义个函数 Q(z|DX),数据集DX的发生,z的概率密度函数,即如果DX发生,Q(z|DX)就是z的概率密度函数,比如一个数字图像0,z隐式代表0的概率就很大,而那些代表1的概率就很小。如果我们有办法搞到这个Q的函数表示,我们就可以直接使用DX算出z的最佳值了。为什么会引入Q呢?其实道理很简单,如果DX是x这个变量直接生成的,要想找回x的模型,就要引入一个概率密度函数T(x|DX),亦即针对DX,我们要找到一个x的最佳概率密度函数。
现在的问题就变成了,我们可以根据DX计算出Q(z|DX)来让他尽量与理想的Pz(z|DX)尽量的趋同,这就要引入更加高深的功夫了——相对熵,也叫KL散度(Kullback-Leibler divergence,用 D表示)。
离散概率分布的KL公式
KL(p∥q)=∑p(x)logp(x)q(x)连续概率分布的KL公式
KL(p∥q)=∫p(x)logp(x)q(x)dxPz(z|DX)和Q(z|DX)的KL散度为
D[Q(z|DX)∥Pz(z|DX)]=∫Q(z|DX)[logQ(z|DX)–logPz(z|DX)]
也可写成
D[Q(z|DX)∥Pz(z|DX)]=Ez∼Q[logQ(z|DX)–logPz(z|DX)]
通过贝叶斯公式
Pz(z|DX)=P(DX|z)P(z)P(DX)
这里不再给P起名,其实Pz(z)直接写成P(z)也是没有任何问题的,前面只是为了区分概念,括号中的内容已经足以表意。
因为logP(DX)与z变量无关,直接就可以提出来了,进而得到闪闪发光的公式(2):
公式(2)是VAE的核心公式,我们接下来分析一个这个公式。
公式的左边有我们的优化目标P(DX),同时携带了一个误差项,这个误差项反映了给定DX的情况下的真实分布Q与理想分布P的相对熵,当Q完全符合理想分布时,这个误差项就为0,而等式右边就是我们可以使用梯度下降进行优化的,这里面的Q(z|DX)特别像一个DX->z的编码器,P(DX|z)特别像z->DX的解码器,这就是VAE架构也被称为自编码器的原因。
由于DX早已不再有分歧,我们在这里把所有的DX都换成了X。
我们现在有公式(2)的拆分:
– 左侧第一项:logP(X)
– 左侧第二项:D(Q(z|X∥P(z|X))
– 右边第一项:Ez∼Q[logP(X|z)]
– 右边第二项:D[Q(z|X)∥P(z)]
还有下面这些:
– P(z)=N(0,I),
– P(X|z)=N(X|f(z),σ2∗I),
– Q(z|X)=N(z|μ(X),Σ(X))
我们再明确一下每个概率的含义:
– P(X)——当前这个数据集发生的概率,但是他的概率分布我们是不知道,比如,X的空间是一个一维有限空间,比如只能取值0-9的整数,而我们的 X = { 0, 1, 2, 3, 4 },那么当概率分布是均匀的时候,P(X)就是0.5,但是如果不是这个分布,就不好说是什么了,没准是0.1, 0.01,都有可能。P(X)是一个函数,就好像是一个人,当你问他X=某个值的时候,他能告诉发生的概率。
– P(z) —— 这个z是我们后来引入的那个w,还记得吗?他们都已经归顺了正态分布,如果z是一维的,那他就是标准正态分布N(0, I)。
– P(X|z) —— 这个函数的含义是如果z给定一个取值,那么就知道X取某个值的概率,还是举个例子,z是一个神奇的变量,可以控制在计算机屏幕上出现整个屏幕的红色并且控制其灰度,z服从N(0,1)分布,当z=0时代表纯正的红色,z越偏离0,屏幕的红色就越深,那么P(X|z)就表示z等于某个值时X=另一值的概率,由于计算机是精确控制的,没有额外的随机因素,所以如果z=0能够导致X取一个固定色值0xFF0000,那么P(X=0xFF0000|z=0)=1,P(x!=0xFF0000|z=0) = 0,但如果现实世界比较复杂附加其他的随机因素,那么就可能在z确定出来的X基础值之上做随机了。这就是我们之前讨论的,大数定理,P(X|z)=N(X|f(x),σ2∗I)。f(z)就是X与z直接关系的写照。
– P(z|X) —— 当X发生时,z的概率是多少呢?回到刚才计算机屏幕的例子,就非常简单了P(z=0|X=0xFF0000) = 1, P(z!=0|X=0xFF0000) = 0,但是由于概率的引入,X|z可以简化成高斯关系,相反,也可以简化高斯关系。这个解释对下面的Q同样适用。
– Q(z) —— 对于Q的分析和P的分析是一样的,只不过Q和P的不同时,我们假定P是那个理想中的分布,是真正决定X的最终构成的背后真实力量,而Q是我们的亲儿子,试着弄出来的赝品,并且希望在现实世界通过神经网络,让这个赝品能够尝试控制产生X。当这个Q真的行为和我们理想中的P一模一样的时候,Q就是上等的赝品了,甚至可以打出如假包换的招牌。我们的P已经简化成N(0,I),就意味着Q只能向N(0, I)靠拢。
– Q(z|X) —— 根据现实中X和Q的关系推导出的概率函数, 当X发生时,对应的z取值的概率分布情况。
– Q(X|z) —— 现实中z发生时,取值X的概率。
我们的目标是优化P(X),但是我们不知道他的分布,所以根本没法优化,这就是我们没有任何先验知识。所以有了公式(2),左边第二项是P(z|X)和Q(z|X)的相对熵,意味着X发生时现实的分布应该与我们理想的分布趋同才对,所以整个左边都是我们的优化目标,只要左边越大就越好,那么右边的目标就是越大越好。
右边第一项:Ez∼Q[logP(X|z)]就是针对面对真实的z的分布情况(依赖Q(z|X),由X->z的映射关系决定),算出来的X的分布,类似于根据z重建X的过程。
右边第二项:D[Q(z|X)∥P(z)] 就是让根据X重建的z与真实的z尽量趋近,由于P(z)是明确的N(0, I),而Q(z|X)是也是正态分布,其实就是要让Q(z|X)趋近与标准正态分布。
现在我们对这个公式的理解更加深入了。接下来,我们要进行实现的工作。
4. 实现
针对右边两项分别实现
第二项是Q(z|X)与N(0, I)的相对熵,X->z构成了编码器部分。
Q(z|x)是正态分布,两个正态分布的KL计算公式如下(太复杂了,我也推不出来,感兴趣的看[1]):
det是行列式,tr是算矩阵的秩,d是I的秩即d=tr(I)。
变成具体的神经网络和矩阵运算,还需要进一步变化该式:
KL(N(μ,Σ)∥N(0,I))=12∑i[−log(Σi)+Σi+μ2i–1]
OK,这个KL我们也会计算了,还有一个事情就是编码器网络,μ(X)和Σ(X)都使用神经网络来编码就可以了。
第一项是Ez∼Q[logP(X|z)]代表依赖z重建出来的数据与X尽量地相同,z->X重建X构成了解码器部分,整个重建的关键就是f函数,对我们来说就是建立一个解码器神经网络。
到此,整个实现的细节就全都展现在下面这张图里了
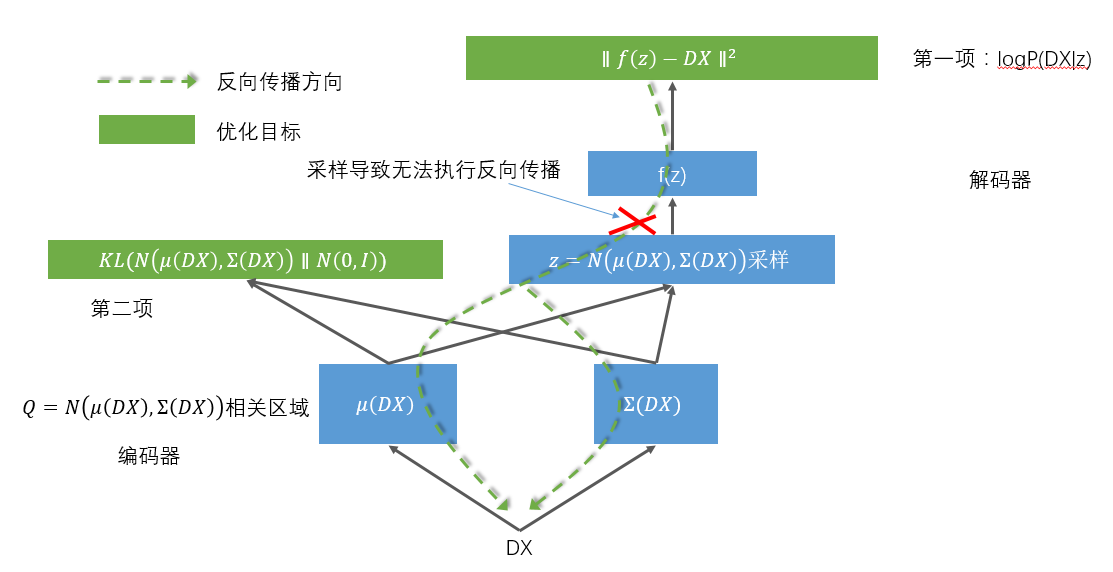
由于这个网络传递结构的一个环节是随机采样,导致无法反向传播,所以聪明的前辈又将这个结构优化成了这样:
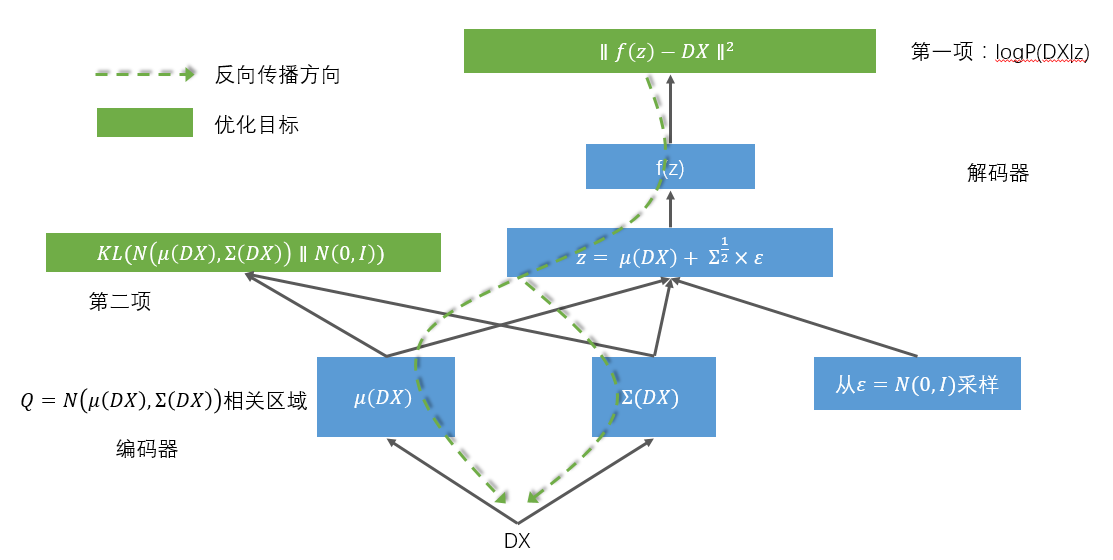
这样就可以对整个网络进行反向传播训练了。
具体的实现代码,我实现在了这里:
https://github.com/vaxin/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/variational_autoencoder.py
里面的每一步,都有配合本文章的对照解释。
5. 延伸思考
之所以关注VAE,是从文献[4]引发的,由于视觉早期的概念形成对于之后的视觉认知起了十分关键的作用,我们有理由相信,在神经网络训练时,利用这种递进关系,先构建具有基础认知能力的神经网络,再做高级认知任务时会有极大的效果提升。但通过前面神秘变量的分析,我们发现,为了充分利用高斯分布,我们将w替换成了z,也就是说真正的隐变量隐藏在f的神经网络里面,而现在的z反而容易变成说不清楚的东西,这一不利于后续的时候,二来我们需要思考,是否应该还原真实的z,从而在层次化递进上有更大的发挥空间。
[1] http://stats.stackexchange.com/questions/60680/kl-divergence-between-two-multivariate-gaussians
[2] https://arxiv.org/abs/1606.05908
[3] https://zhuanlan.zhihu.com/p/22464768
[4] https://arxiv.org/abs/1606.05579