Three challenges you’re going to face when building a chatbot

Developing your own chatbot? You're likely to meet these challenges. Continue reading to find out what we've learned from developing a medical bot.
Recently we have released Symptomate Bot – one of the world’s first health check-up chatbots. The road towards a working service was a new experience for us. We decided to share some lessons we’ve learned during the process, hoping other bot developers will benefit from them. We'd love to hear your opinion and also learn from your experiences.
At Infermedica we've developed a diagnostic engine that collects symptoms, asks diagnostic questions and presents likely health issues underlying this evidence. The engine uses a complex probabilistic model built on top of a knowledge base curated by medical professionals and enriched by machine learning. It is available via API and has provided helpful information to over 1M patients through a number of symptom checker apps, intelligent patient intake forms and other applications. Symptomate Bot is our attempt at building a conversational interface to the engine that will work as a symptom checker chatbot.

Here are three of the challenges we had to face during the process.
1. Scalable architecture for handling messages
Chatbots are a new trend, which makes it extremely difficult to predict the amount of traffic the bot will be exposed to. If you take the undertaking seriously, you should anticipate the possibility of a sudden traffic increase even if it doesn’t seem likely to come soon. Keep in mind that chat platforms allow users to report a defunct or misbehaving bot, which could result in a sudden account shutdown, not to mention a loss of credibility.
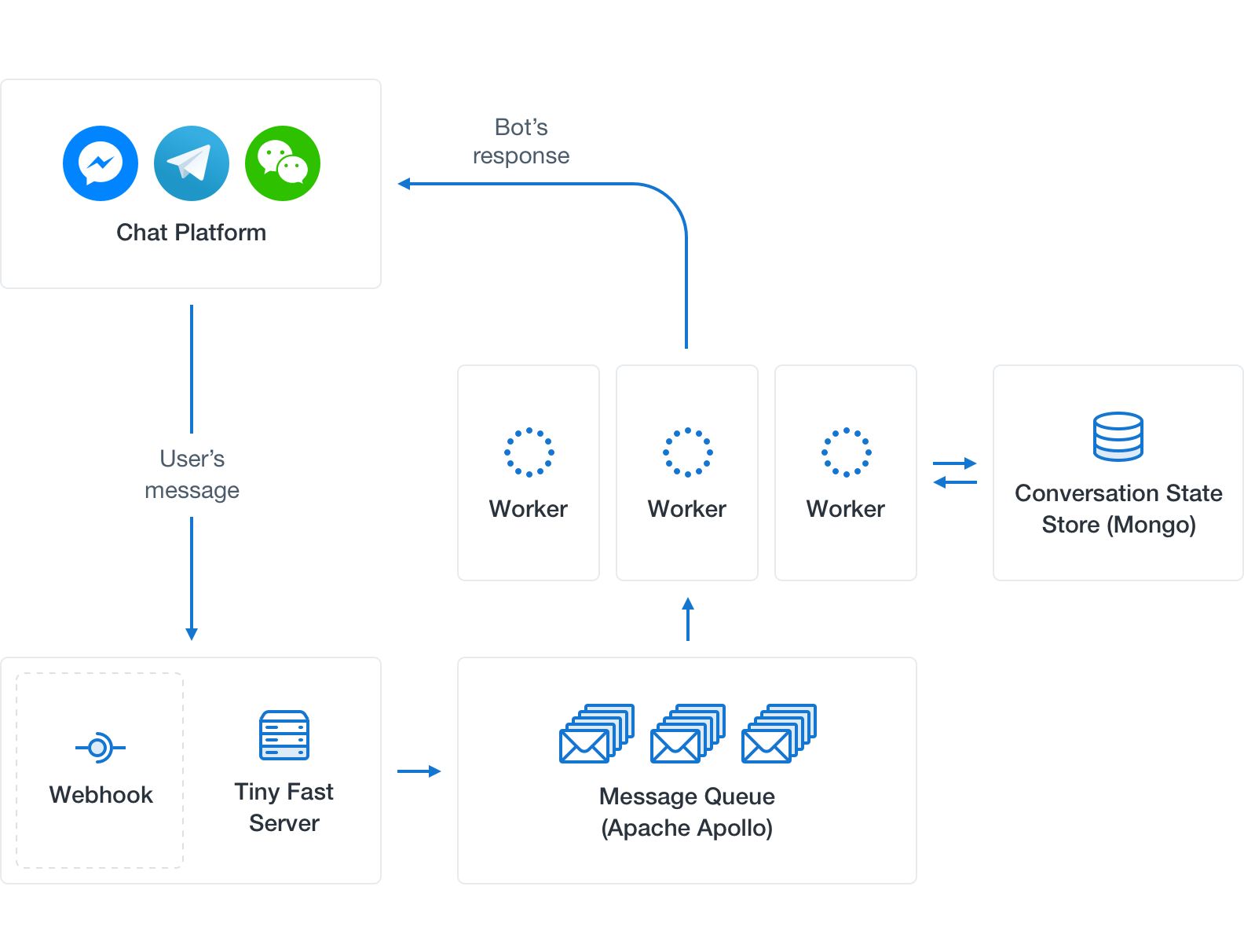
On most platforms (Facebook Messenger included) the bot developer is responsible for exposing a webhook. Your webhook will be called each time a user messages the bot. Handling each message involves understanding the message given the current state of the conversation with the user, altering the conversation state and possibly sending back responses. It may require some expensive operations (in our case calling our API which hosts both diagnostic reasoning and NLP services).
“You should anticipate the possibility of a sudden traffic increase even if it doesn’t seem likely to come soon.”
The setting described above fits well into an architectural pattern called message broker. In this model, user messages are stored in a message queue from which a number of concurrent workers will pick them up and handle them. Here are some especially important requirements for chatbots:
- Instant handling – The server sitting behind the webhook should handle incoming messages instantly by moving them straight to the message queue. Some chat platforms may be pretty touchy about delays, so better safe than sorry.
- Assigned worker – The message queue should guarantee that each user will always be handled by the same worker (consumer in message queue lingo). This is necessary to ensure that messages sent by a user are always handled in the order in which they are sent.
- Load-balancing – The message queue should also perform load-balancing to keep the workers reasonably occupied with tasks.
- Propagation – If a worker dies, the queue should be able to transfer its responsibilities to another worker.
- Event processing loop – A worker’s event processing loop includes these steps: pop a message from the queue, fetch the conversation state associated with the user, handle the message, possibly replying to the user, and push the updated state back.
- Storage – The storage place for the per-user conversation state should allow flexible structure and fast read/write access. The best choice seems to be a NoSQL database. We opted for MongoDB because its simple and extensible document format seems perfect for keeping track of the conversation state.
We did some research on message queue software. Our first finding was that requirements 2 and 3 are satisfied by a feature called Message Groups.
What came as a surprise is that the most popular implementations, such as ActiveMQ and RabbitMQ, do not support this feature (the tumultuous history of message queue projects is perhaps worth a read on its own). We found a working and user-friendly implementation of message groups in Apache Apollo and we can recommend it as a working solution even though it's not the most recent project in the message queue family. We’d love to hear your opinions and experiences in this matter.
2. A conversational agent must converse
There’s no way around it. If users just wanted to tap and swipe, they wouldn't be using a messenger; they'd go to your fancy responsive website. Go to botlist.co, pick a category, start interacting with random bots and you’ll likely see a lot of oversized tables filled with buttons and awkwardly cropped images, all squeezed into a tiny chat window.
Having said that, we think there's nothing wrong with using response templates for simple questions with a small number of possible answers. Using them wisely may direct the user towards the answers they need without giving the impression of talking to an IVR system (everyone hates to hear “press 1 for help”).
Natural Language Processing
If you want to join the chatbot hype and position your product as an intelligent one, you need to implement at least very basic Natural Language Processing (NLP) techniques. Take the time to come up with use cases and likely conversation scenarios. Try writing down intents the user may express when chatting. With an anticipated spectrum of intents in front of you, it will be easier to prepare to recognize them.
“If users just wanted to tap and swipe, they wouldn't be using a messenger; they'd go to your fancy responsive website.”
In the case of a symptom checker, we anticipated users trying to communicate their symptoms, attempting to correct misunderstood observations or telling the bot that they have nothing more to say.
Also, think about objects in your domain that the user may want to address. Do they have names? Do they have synonyms? Are they typically expressed as noun phrases or do you also need to deal with clauses (e.g., “my back hurts”) in some descriptions?
We realised that understanding of symptom mentions in text is an important task. There are excellent tools out there to help you recognize medical concepts — such as Lexigram API. It’s worth mentioning that Infermedica offers an entity recognition tool tailored to work together with our customized medical knowledge base. We've made the tool available as a text analysis endpoint in our API.
Chat language
Last but not least, chat language is far from standard English. You can refuse to deal with spelling errors, or face the chat reality and implement spelling correction. While there is an abundance of open-source projects related to spell-checking and spelling correction, you'd be surprised how slow most implementations are.
Before adopting a solution it makes sense to perform some tests on your own. You can't afford to spend 200 milliseconds on each word. For industrial-strength spelling correction you should consider the Symmetric Delete algorithm.
3. Users will get frustrated
During initial testing it became clear to us that much of the time users are going to be misunderstood. To put it bluntly, a huge proportion of messages will not be understood at all and there is little we can do about it. What we can do is anticipate user frustration and alleviate the situation by offering a little help and managing expectations. In some situations we can turn an utter lack of understanding into partial understanding, which is a huge win.

The scale of the comprehension problems will depend on the size of the domain. If the bot is to print out the current exchange rates, there is little room for misunderstanding. Our domain is common health problems. The bot is a conversational interface to our diagnostic engine, built on top of a knowledge base curated by medical professionals. While the knowledge base contains over 1400 symptoms and thousands of synonyms, some users will inevitably want to report observations that are not covered. Also, no NLP technology is perfect and ours is no different; language allows for enormous freedom of expression and some descriptions of known symptoms are not going to be understood.
Analytics
In Symptomate Bot we keep track of some basic statistics gathered during each “visit” (a conversation which starts with the user being asked to report his/her symptoms and finishes with the presentation of possible diagnoses). These statistics include a measure of anticipated frustration, which is used to decide when to digress in order to offer a bit of contextual help, or at least acknowledge that we are aware of current shortcomings.
“To put it bluntly, a huge proportion of messages will not be understood at all and there is little we can do about it.”
Also, we've found it worthwhile to fall back on a partial understanding mechanism when our main NLP module fails to detect any symptom in the user’s story. This mechanism assumes that the story was a description of exactly one symptom (the main NLP module can capture multiple mentions). We use a vector space model to find the textually most similar symptoms and ask if the user meant any of those.
Conclusion
We've just shared a few hints and thoughts stemming from our experience building a conversational interface to our medical inference engine. We hope you’ll find these observations useful when building your own chatbot, whatever the domain. Stay tuned for more articles — we’ll be covering topics in healthcare, AI and NLP.
Read more in: Architecture, Chatbots, NLP, Symptom Checker, Technical![]()
Adam Radziszewski
Share
Subscribe to our newsletter
We’ll send you the latest articles from this blog and updates on what we’re working on.