K-Means聚类的Python实践
K-Means应该是最简单的聚类算法之一了吧,理论上很简单,就是随即初始化几个中心点,不断的把他们周围的对象聚集起来,然后根据这群对象的重置中心点,不断的迭代,最终找到最合适的几个中心点,就算完成了。
然后,真正实践的时候才会思考的更加深入一点,比如本文的实践内容就是一个失败的案例(算法是成功的,场景是失败的)。
什么是聚类
简单的说,就是对于一组不知道分类标签的数据,可以通过聚类算法自动的把相似的数据划分到同一个分类中。即聚类与分类的区别主要在于,聚类可以不必知道源数据的标签信息。
K-Means(K均值)
K均值是一种比较简单的聚类算法,下图是来自wiki:
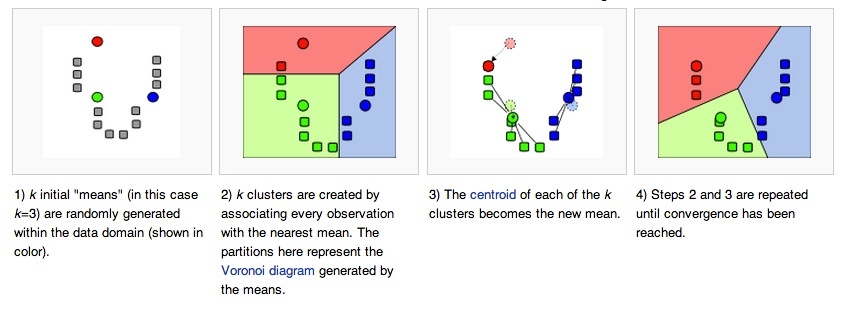
从图中可以看出,K-Means首先在空间中随机选取三个点(彩色的),这些点可以是某个数据点所在的位置,也可以是纯粹的空间随机点。然后类似拉帮结派一样,到自己附近“抓人”。第一轮抓完之后形成了三个稳定的新“帮派”,这时候每一个帮派由于成员发生了变化,大家就重新投票选择新的“核心”,也就是中间点。选好新的核心之后,这个核心就又开始新一轮的拉帮结派。然后不断的循环迭代,直到整个空间稳定时停止。
K-Means算法描述
上面对K-Means的介绍已经比较详细了,现在,如果把K-Means算法总结成算法描述,其实只需要四步骤:
- 任意选择k个点,作为初始的聚类中心。
- 遍历每个对象,分别对每个对象求他们与k个中心点的距离,把对象划分到与他们最近的中心所代表的类别中去,这一步我们称之为“划分”。
- 对于每一个中心点,遍历他们所包含的对象,计算这些对象所有维度的和的中值,获得新的中心点。
- 计算当前状态下的损失(用来计算损失的函数叫做Cost Function,即价值函数),如果当前损失比上一次迭代的损失相差大于某一值(如1),则继续执行第2、3步,知道连续两次的损失差为某一设定值为止(即达到最优,通常设为1)。
距离函数
计算距离有很多种方式,我这里使用的是最简单的欧氏距离,其他的几种距离可以参考酷壳的这篇博客。
损失函数(Cost Function)
每一次选取好新的中心点,我们就要计算一下当前选好的中心点损失为多少,这个损失代表着偏移量,越大说明当前聚类的效果越差,计算公式称为(Within-Cluster Sum of Squares, WCSS):
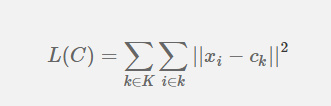
其中,$ x_{i} $ 表示某一对象,$c_{k}$表示该对象所属类别的中心点。整个式子的含义就是对各个类别下的对象,求对象与中心点的欧式距离的平方,把所有的平方求和就是$L(C)$。
评价标准
采用聚类的数据,通常没有已知的数据分类标签,所以通常就不能用监督学习中的正确率、精确度、召回度来计算了(如果有分类标签的话,也是可以计算的)。
常用于聚类效果评价的指标为:Davies Bouldin Index,它的表达式可以写为:
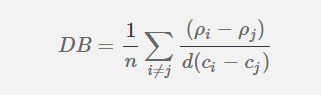
其中,$ rho_{i} $和 $ rho_{j} $ 都表示i,j两个分类中的所有对象到中心点的平均距离。而分母中的$c_{i}$和分别表示i,j两个分类的中心点之间的距离。整个表达式的含义就是,聚类效果越好,两个分类间的距离应该越远,分类内部越密集。
Python实践
#### 一、数据准备 — 如之前所写的朴素贝叶斯分类详解一样,我们的第一步依然是进行数据准备,所不同的是,由于我们不再需要对模型进行训练,所以不必拆分原始数据为训练和测试两部分。
数据向量化
这部分是要格外注意的,要根据不同的数据使用不同的度量单位,比如我们现在是对新闻进行聚类,最初我使用的是,每一个单词作为一个向量,单词的频度就是该维度上的值,但是后来发现结果非常差,经过请教前辈,发现对新闻聚类最好不要使用词频,而且要抛出新闻长度对结果的影响。
举个例子:假如一个新闻A包含Google,Baidu两个词各一次,而B分别包含两个单词歌两次,那么实际上他们属于同一种分类的概率应该是一样的,也就是距离为0才对。
另外,即便是不使用词频,也要注意抛弃总长度对结果的影响,比如A(Google,Baidu),而B是(Google,Baidu,Netease),那么A、B的欧式长度分别是根号2和根号3,这也不合理,我们需要正规化操作,让他们的欧氏距离总长度都相等(参看我代码里的normalize函数)。
二、初始化随机点
我们的新闻数据已知属于5个类别,所以我们就初始设定5个随机点,我使用了random.random()函数来随机选择,具体代码在initCenters函数部分。
在初始化过程完成的工作有:
- 第一次设定初始聚类中心
- 第一次为这些中心点分配对象
- 分配对象完成之后进行重新定位中心点
- 对定位后的中心点计算损失函数
三、迭代进行K-Means优化
如上面介绍K-Means算法的时候提到的,这部分需要不断的重新划分对象,重新定位中心点和计算损失函数,然后根据损失函数与上一次的对比决定是不是要继续迭代。
这部分代码在start函数内。
四、Cost Function
具体损失函数如何计算的,之前是在costFunction内,但是我发现分配对象到中心点的时候,可以顺便把损失计算出来,为了提升性能,我把costFunction的代码合并到了split函数内。
下面是完整的程序代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
|
#!/usr/bin/env python
#coding:utf-8
import os
import random
import math
class Center(object):
def __init__(self, vector):
self.vector = vector
self.objects = []
class Vector(object):
"""单个数据记录的向量表示"""
def __init__(self, label):
# 由于当前向量比较稀疏,所以使用字典而非数组来表示
self.words = {}
self.label = label
def loadFromFile(self, file_name, word_dict):
with open(file_name,'r') as f:
words = f.read().split()
for word in words:
if word not in word_dict:
word_dict[word] = len(word_dict)
word_id = word_dict[word]
self.words[word_id] = 1
def addToNearestCenter(self, centers):
nearest = centers[0]
d = self.distance(centers[0].vector)
for center in centers[1:]:
new_d = self.distance(center.vector)
if new_d < d:
d = new_d
nearest = center
nearest.objects.append(self)
"""
计算两个向量之间的欧几里得距离,注意数据维度上的值非常稀疏.
"""
def distance(self, vector):
square_sum = 0.0
for word in vector.words:
if word not in self.words:
a = vector.words[word]
square_sum += math.pow(a, 2)
if word in self.words:
a,b = vector.words[word],self.words[word]
square_sum += math.pow((a-b), 2)
for word in self.words:
if word not in vector.words:
a = self.words[word]
square_sum += math.pow(a, 2)
result = math.sqrt(square_sum)
return result
class KMeans(object):
""" 准备数据,把新闻数据向量化"""
def __init__(self, dir_name):
self.word_dict = {}
self.vectors = []
self.dir_name = dir_name
# {'file_name':{word:3,word:4}}
self.centers = []
# 上一次中心点的损失
self.last_cost = 0.0
# 从指定目录加载文件
for file_name in os.listdir(dir_name):
v = Vector(file_name)
v.loadFromFile(dir_name+'/'+file_name, self.word_dict)
self.vectors.append(v)
""" 分配初始中心点,计算初始损失,并开始聚类 """
def start(self, class_num):
# 从现有的所有文章中,随机选出class_num个点作为初始聚类中心
for vector in random.sample(self.vectors, class_num):
c = Center(vector)
self.centers.append(c)
# 初始划分,并计算初始损失
print 'init center points'
self.split()
self.locateCenter()
self.last_cost = self.costFunction()
print 'start optimization'
# 开始进行优化,不断的进行三步操作:划分、重新定位中心点、最小化损失
i = 0
while True:
i += 1
print '第 ',i,' 次优化:'
self.split()
self.locateCenter()
current_cost = self.costFunction()
print '损失降低(上一次 - 当前):',self.last_cost,' - ',current_cost,' = ',(self.last_cost - current_cost)
if self.last_cost - current_cost <= 1:
break
else:
self.last_cost = current_cost
# 迭代优化损失函数,当损失函数与上一次损失相差非常小的时候,停止优化
count = 0
for center in self.centers:
count += 1
print '第', count, '组:'
for s in ['business','it','sports','yule','auto']:
s_count = 0
for vector in center.objects:
if vector.label.find(s) > 0:
s_count += 1
print s,' = ',s_count
print '---------------------------------------'
"""
根据每个聚类的中心点,计算每个对象与这些中心的距离,根据最小距离重新划分每个对象所属的分类
"""
def split(self):
print '划分对象... Objects : ', len(self.vectors)
# 先清空上一次中心点表里的对象数据,需要重新划分
for center in self.centers:
center.objects = []
# 遍历所有文件并分配向量到最近的中心点区域
for vector in self.vectors:
vector.addToNearestCenter(self.centers)
""" 重新获得划分对象后的中心点 """
def locateCenter(self):
# 遍历中心点,使用每个中心点所包含的文件重新求中心点
count = 0
for center in self.centers:
count += 1
print '计算第 ', count, ' 类的新中心点...'
files_count = float(len(center.objects))
# 新的中心点,格式为 {word1:0,word2:5...}
new_center = {}
# 遍历所有该中心包含的文件
for vector in center.objects:
# 遍历该文件包含的单词
for word in vector.words:
if word not in new_center:
new_center[word] = 1
else:
# 由于不使用词频计算,所以出现的词都是加1,最后再求平均
new_center[word] += 1
for word in new_center:
new_center[word] = new_center[word]/files_count
# 中心点对象
center.vector = Vector('center')
center.vector.words = new_center
""" 损失函数 """
def costFunction(self):
print '开始计算损失函数'
total_cost = 0.0
count = 0
for center in self.centers:
count += 1
print '计算第 ', count, ' 类的损失 objects : ', len(center.objects)
for vector in center.objects:
# 求距离平方作为损失
total_cost += math.pow(vector.distance(center.vector),2)
print '本轮损失为:',total_cost
return total_cost
if __name__ == '__main__':
km = KMeans('allfiles')
km.start(5)
|
输出结果:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
2454 files loaded
初始化随机中心点个数
: 5
划分对象并计算损失
...
计算第
1 点的新中心点...
计算第
2 点的新中心点...
计算第
3 点的新中心点...
计算第
4 点的新中心点...
计算第
5 点的新中心点...
第
1 次迭代:
划分对象并计算损失
...
计算第
1 点的新中心点...
计算第
2 点的新中心点...
计算第
3 点的新中心点...
计算第
4 点的新中心点...
计算第
5 点的新中心点...
损失
(上一次 - 当前): 4375.51247663 - 2034.9234715 = 2340.58900512
第
2 次迭代:
划分对象并计算损失
...
计算第
1 点的新中心点...
计算第
2 点的新中心点...
计算第
3 点的新中心点...
计算第
4 点的新中心点...
计算第
5 点的新中心点...
损失
(上一次 - 当前): 2034.9234715 - 2033.91112679 = 1.01234470898
第
1 组:
business = 314
it = 68
sports = 15
yule = 10
auto = 79
---------------------------------------
第
2 组:
business = 10
it = 16
sports = 26
yule = 132
auto = 10
---------------------------------------
第
3 组:
business = 4
it = 15
sports = 4
yule = 4
auto = 16
---------------------------------------
第
4 组:
business = 158
it = 226
sports = 388
yule = 281
auto = 338
---------------------------------------
第
5 组:
business = 14
it = 183
sports = 40
yule = 33
auto = 70
---------------------------------------
|
由于初始点是随机选择的,所以结果并不是很好,这点可以使用k-means++算法改进,以后再写吧。
1、对于运算速度非常慢:
瓶颈在于两个地方,主要就是计算欧氏距离的时候,需要所有对象分别与中心点求差平方,而中心点根据实际使用,发现维度高达2W或3W,2500个文章,相当于进行2500 * 3W次的(基本运算+乘法运算),目前网上有不少库专门做这个事情,但总结起来还是没法根本上解决此问题。
2、对于分类效果较差:
我选择的场景更适合用朴素贝叶斯这种概率分类或者SVM这种间隔分类,因为K-Means的效果对初始的几个点的依赖非常大,如果运气不好选在了边缘或者几个分类的中间,那效果就会奇差。
解决办法:
避免在新闻分类或其他高维数据下使用K-Means,除非能解决初始中心点的选择问题,关于这点,我们后面的高斯混合模型可以部分解决这个问题。
而对于性能问题我目前无解,暂时想不到合适的数据结构来简化计算,唯一能想到的就是用C函数替代欧氏距离和损失函数的计算部分。
如果您有好的解决办法,请联系我QQ:83534146 ,望不吝指导,多谢!
