公司数据库随着时间的增长,数据越来越多,查询速度也越来越慢。进数据库看了一下,几十万调的数据,查询起来确实很费时间。
要提升SQL的查询效能,一般来说大家会以建立索引(index)为第一考虑。其实除了index的建立之外,当我们在下SQL Command时,在语法中加一段WITH (NOLOCK)可以改善在线大量查询的环境中数据集被LOCK的现象藉此改善查询的效能。
不过有一点千万要注意的就是,WITH (NOLOCK)的SQL SELECT有可能会造成Dirty Read,就是读到无效的数据。
下面对于SQLSERVER的锁争用及nolock,rowlock的原理及使用作一个简单描述:
锁争用的描述
那些不仅仅使用行级锁的数据库使用一种称为混和锁(lock escalation)的技术来获取较高的性能。除非很明确知道是针对整个数据表,否则这些数据库的做法是开始使用行级锁, 然后随着修改的数据增多,开始使用大范围的锁机制。
不幸的是,这种混和锁的方法会产生和放大新的问题:死锁。如果两个用户以相反的顺序修改位于不同表的记录,而这两条记录虽然逻辑上不相关, 但是物理上是相邻的,操作就会先引发行锁,然后升级为页面锁。这样, 两个用户都需要对方锁定的东西,就造成了死锁。
例如:
用户A修改表A的一些记录,引发的页面锁不光锁定正在修改的记录,还会有很多其它记录也会被锁定。
用户B修改表B的一些记录,引发的页面锁锁定用户A和其它正在修改的数据。
用户A想修改用户B在表B中锁定(并不一定正在修改的)数据。
用户B想修改或者仅仅想访问用户A在表A中锁定(并不一定正在修改)的数据。
为了解决该问题,数据库会经常去检测是否有死锁存在,如果有,就把其中的一个事务撤销,好让另一个事务能顺利完成。一般来说,都是撤销 那个修改数据量少的事务,这样回滚的开销就比较少。使用行级锁的数据库 很少会有这个问题,因为两个用户同时修改同一条记录的可能性极小,而且由于极其偶然的修改数据的顺序而造成的锁也少。
而且,数据库使用锁超时来避免让用户等待时间过长。查询超时的引入也是为了同样目的。我们可以重新递交那些超时的查询,但是这只会造成数据库的堵塞。如果经常发生超时,说明用户使用SQL Server的方式有问题。正常情况是很少会发生超时的。
在服务器负载较高的运行环境下,使用混合锁的SQL Server锁机制,表现不会很好。 原因是锁争用(Lock Contention)。锁争用造成死锁和锁等待问题。在一个多用户系统中,很多用户会同时在修改数据库,还有更多的用户在同时访问数据库,随时会产生锁,用户也争先恐后地获取锁以确保自己的操作的正确性,死锁频繁发生,这种情形下,用户的心情可想而知。
确实,如果只有少量用户,SQL Server不会遇到多少麻烦。内部测试和发布的时候,由于用户较少,也很难发现那些并发问题。但是当激发几百个并发,进行持续不断地INSERT,UPDATE,以及一些 DELETE操作时,如何观察是否有麻烦出现,那时候你就会手忙脚乱地去解锁。
锁争用的解决方法
SQL Server开始是用行级锁的,但是经常会扩大为页面锁和表锁,最终造成死锁。
即使用户没有修改数据,SQL Server在SELECT的时候也会遇到锁。幸运的是,我们可以通过SQL Server 的两个关键字来手工处理:NOLOCK和ROWLOCK。
它们的使用方法如下:
SELECT COUNT(UserID) FROM Users WITH (NOLOCK) WHERE Username LIKE 'football'
和
UPDATE Users WITH (ROWLOCK) SET Username = 'admin' WHERE Username = 'football'
NOLOCK的使用
NOLOCK可以忽略锁,直接从数据库读取数据。这意味着可以避开锁,从而提高性能和扩展性。但同时也意味着代码出错的可能性存在。你可能会读取到运行事务正在处理的无须验证的未递交数据。 这种风险可以量化。
ROWLOCK的使用
ROWLOCK告诉SQL Server只使用行级锁。ROWLOCK语法可以使用在SELECT,UPDATE和DELETE语句中,不过 我习惯仅仅在UPDATE和DELETE语句中使用。如果在UPDATE语句中有指定的主键,那么就总是会引发行级锁的。但是当SQL Server对几个这种UPDATE进行批处理时,某些数据正好在同一个页面(page),这种情况在当前情况下 是很有可能发生的,这就象在一个目录中,创建文件需要较长的时间,而同时你又在更新这些文件。当页面锁引发后,事情就开始变得糟糕了。而如果在UPDATE或者DELETE时,没有指定主键,数据库当然认为很多数据会收到影响,那样 就会直接引发页面锁,事情同样变得糟糕。
下面写一个例子,来说明一下NOLOCK的作用,这里使用一个有一万多条的数据库来测试,先不用NOLOCK来看一下:
declare @start DATETIME; declare @end DATETIME; SET @start = getdate(); select * from Captions_t18; SET @end = getdate(); select datediff(ms,@start,@end);
这里为了是效果更加明显,使用了Select * ,来看一下执行结果,如下图:
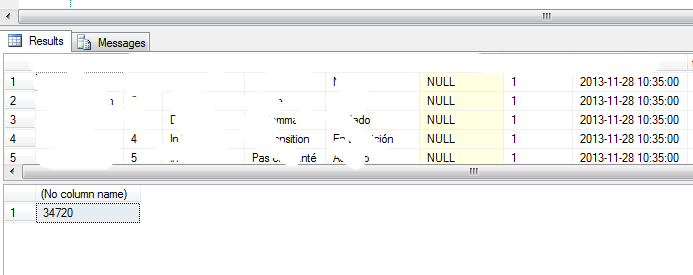
这里显示的使用时间是34720ms,下面使用NOLOCK来看一下:
declare @start DATETIME; declare @end DATETIME; SET @start = getdate(); select * from Captions_t18 with (NOLOCK); SET @end = getdate(); select datediff(ms,@start,@end);
运行结果如下图:
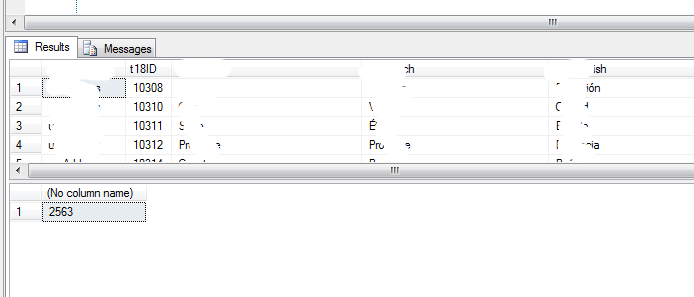
这次使用的时间是2563ms,差距体现出来了吧。个人感觉时间不应该差这么多,总之性能是提高了不少。大家多多测试看看吧~~
参考文章:http://blog.sina.com.cn/s/blog_7034dbe00100ll9n.html

