本来这算不上一篇文章,但是我仍旧写了,除了解决一个小问题还要说点其他的关于数据分析的想法,首先先解决一个小问题。
第一部分
问题描述:处理游戏帐号信息时发现有重复的帐号,比如帐号A有N个重复项,希望留下1个重复帐号,但是要把剩下N-1个删除重复帐号删除。具体的原数据(黄色)模拟如下:
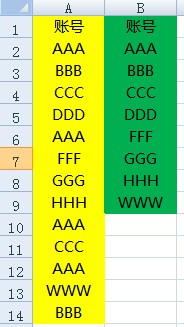
而我们希望得到的最终处理数据格式如右侧一列(绿色)所示。针对这个处理,其实有很多方法,可以参看小蚊子的《谁说菜鸟不会数据分析》,比如使用条件筛选就能搞定,今天不谈这个方法,说说另一种思路。
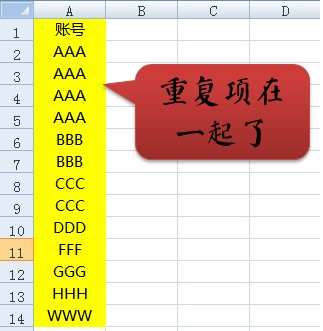
首先我们对于原数据进行排序,怎么排序都OK,重要的是重复项会在一起,如下图所示:
之后我们使用IF和Exact函数嵌套使用,解决这个问题,操作如下:
增加一列,叫做标识项,并写下公式=if(exact(A2,A3),1,2),关于Exact()和if()函数的使用介绍这里不再累术,自行查阅Excel函数帮助文档就OK了,具体公式如下图显示:
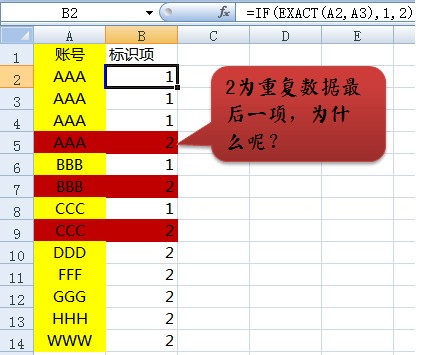
这里公式的秘密和为什么不解释了,估计大家看到这里都明白了,下面我们要继续操作,解决问题,之后选中第一行,快捷键“Crtl+Shift+L”打开自动筛选功能,筛选标识项为“1”的数据,如下图:
之后,选择这几行数据,然后删除,之后打开再次打开筛选,选择全部,结果数据如下所示:

但是到了这样这一步,其实已经完成了,可是很多人还是有疑问,那些空白行怎么办啊,我们需要数据都是像最开始的那个绿色的格式最好了,这样有空白的位置不好,至于这个问题,这里不回答了,大家自己想一想,其实很简单,非常容易解决。期待大家的答案。
第二部分
这一部分,其实还是想发一些牢骚和学习数据分析的建议,作为数据分析师,首先是先把数据处理和优化工作做好,当然这之前必须要进行商业理解,把问题搞明白,才能后期把数据提取出来,进而才能借助模型、算法进行数据处理,模型发布,评估,分析,这是一个完整的CRISP-DM,数据处理优化要用去整体流程80%的时间,因此快速有效掌握数据提取,处理方法很关键,其意义不仅仅在于效率效能的提升,最关键的是锻炼思维和形成一套自己的方法。
你说的有点夸大了吧?
很多人会有这个疑问,很正常,大多数情况下,我们喜欢把数据需求明确,然后让DBA同志帮助我们取数据,解决数据处理过程,但是往往需求理解的差异,导致了后续CRISP-DM全部错误,而且相当不容易发现,所以很多时候我们要自己来做,一个DMA同时也要会一点SQL,数据量非常大时自己倒入数据库,练习一下SQL操作。
当然这是适用于那些学过计算机的人,很多DMA是没怎么学过SQL,因此就会基本上借助Excel、SPSS解决数据处理,这个时候其实非常关键,早期我喜欢拿着网上的文档或者什么宝典来解决问题,发现没用,因为你看了你也记不住,你也不会用,只有当问题摆在面前时,你才有需求,要学习,但是往往又不能找到合适的答案,所以很多人借助别人力量解决,但是解决完了,你仍旧不会,下次问题摆在你面前,你还是不会。
所以,请不要逃避问题,有问题才是你学习Excel,数据处理的最佳时期和机会,不要小看摆渡,如果你能从浩瀚的搜索中找到解决你问题的办法,这是一种能力,如果借助那个答案,你有新的更好的解决之道这就是提升了。这是一种学习能力,通过问题学习。
其二,表述问题,找到自己的习惯。在搜索上如何把自己的问题表述出来,寻找答案,这是你的本事,就像你要求助于他人解决这个问题时,你依然要别人先理解你的需求,才能解决一样,在这一个问题肯定有很多的办法来解决,但不是每个办法都适合你,但是总有一个适合你,因此找到自己解决这种问题的习惯,以后越用越好,融会贯通。
其三,你要学会排列组合。这个排列组合不是真的排列组合,其实是说,日常我们在进行数据处理时,基本上80%以上的工作只需要20%左右的函数和方法就可以搞定了,比如vlookup,sumif,countif,if,条件筛选,排序等等,这也是符合幂律分布的。所以,尽管我们面临不同的问题和需求,但是通过这些公式的嵌套,组合,最后基本上都能解决我们的数据处理和分析需求,而如何优化,组合这就是看你的能力和发挥了,难道你说这不是一种锻炼吗?DMA的工作不仅仅是对得出来分析结果进行分析,在这个过程中,你如何应对产生的一系列问题都将有助于你发散思维,解决最后的分析。
好了废话太多,近期有时间,分享一些我的Excel技巧,欢迎大家也分享和评论。