以下所说的统计学术语大家可以参考小蚊子blog的内容
(http://blog.sina.com.cn/s/blog_49f78a4b0102dwz9.html)
术语是帮助我们打开思路,通过多个角度对数据进行深度解读,数据分析师不能仅仅靠着对数据的一种感觉和敏感来进行数据分析,这样的主观性太强,在合理必要的情况下,使用前人已经总结和使用的方法往往对我们更有帮助,但也要记住不要陷入这个指标误区中,核心还在于人(但不是让你凭感觉作分析),在于人对待问题的思考方式,解决办法。
今天来说说描述性统计分析,统计性描述分析是作为统计分析的第一步,在日常的数据分析中其实我们经常使用一些特征值,尤其是我们做周报或者月报的分析时,这些描述性的统计分析特征值对于我们有一定的帮助,描述性统计分析是进行正确的统计推断的先决条件。通过数据的分布类型和特点、集中和离散程度可进行初步分析。
鄙人经常使用Excel或者SPSS进行描述性的统计分析,描述性的统计分析包括数据收集、整理、显示,对数据信息的初步提取分析,在SPSS中我们有专门的描述性分析,其中涉及了很多的统计量,今天就索性把这些都列出来,给大家参考学习一下,需要说明的是这里列出来的不代表你就必须使用这些统计量,还是要根据业务的需要,适当的选取参考的统计量指标,这些指标是帮助我们分析数据异动,变化的“工具”,但请不要陷入指标的误区,每个指标的使用都是有一定的适用范围,大家需谨慎使用。
集中趋势:平均数(算数平均数、几何平均数、调和平均数、算术-几何平均数、平均数不等式)、众数、中位数等。
离散程度:全距、内距、平均差、标准误、离散系数等。
分布:偏态系数、峰度系数,反映数据偏离正态分布的程度。
下面为大家解释一下这些统计量,知识源于MBALIB、百度百科、wiki。
首先来看平均数,平均数是统计学最常用的统计量,用于表示各观测值相对集中较多的中心位置,可以说是对数据集中趋势的反映,通常情况下初学者容易把平均数认为一组数据之和除以该组数据的个数,其实这样认识是有一定问题的,严格来说,平均数包括算数平均数、几何平均数、调和平均数、众数和中位数。具体的来看一下每个平均数的定义,适用范围。
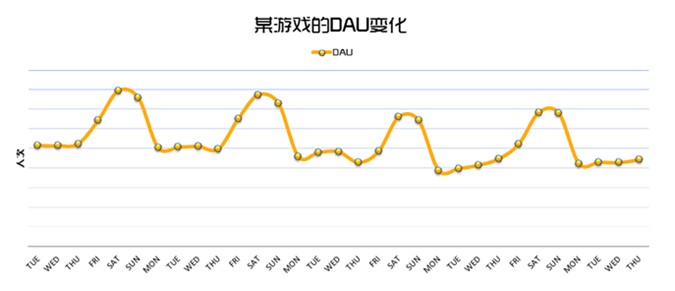
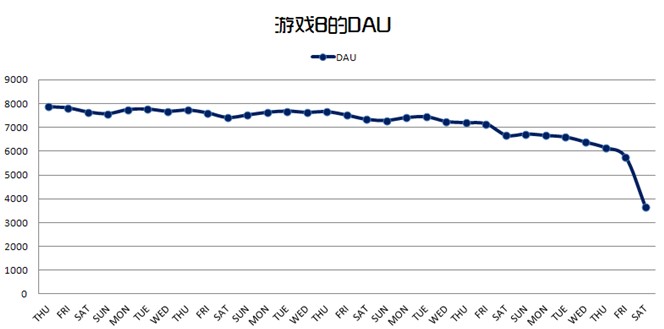
算数平均数:各观测值的总和除以观测值个数所得的商,简称平均数或均数,在统计学上的优点就是它较中位数、众数更少受到随机因素影响,缺点是它更容易受到极端数影响。比如在游戏日活跃人数方面,不同的游戏的活跃波动幅度是不同的,有的游戏会出现明显的异动和极值情况,比如一周内,周五、周六和周日的日活跃和PCU非常高,那么我们在计算这一周7天的平均日活跃时最好是不要计算一周的算数平均数,当然波动幅度不是非常大还是可以使用的,如下图所示的两款游戏的日活跃曲线,A游戏最好分开计算周末和平日的日活跃,B游戏则不需要分开计算。
A游戏
B游戏
(http://zh.wikipedia.org/wiki/%E7%AE%97%E6%95%B8%E5%B9%B3%E5%9D%87%E6%95%B8)
几何平均数:n个变量值连乘积的n次方根,适用于对比率数据的平均,并主要用于计算数据平均增长(变化)率。
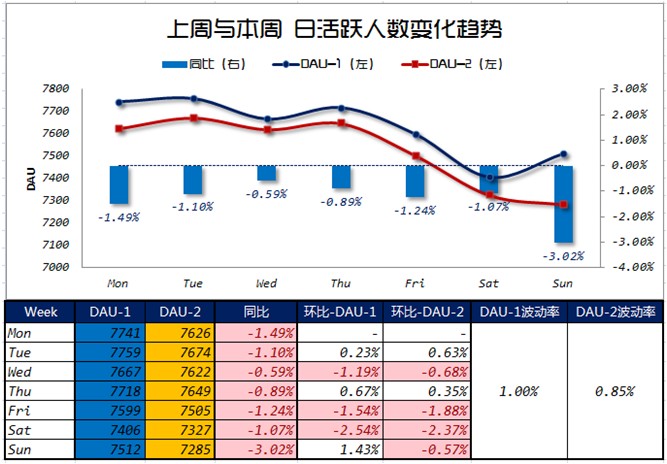
如下图所示的DAU-1和DAU-2的波动率就是使用了几何平均数来进行的计算,在Excel中有专门的统计函数计算几何平均数Geomean(),通过对环比-DAU-1和环比-DAU-2进行几何平均数的计算得到两个波动率,来衡量数据在每天的波动情况,进而进行下一步深入的分析过程。
(http://wiki.mbalib.com/wiki/%E5%B9%B3%E5%9D%87%E6%95%B0)
调和平均数:求一组数值的平均数的方法中的一种,一般是在计算平均速率时使用,在游戏数据分析方面暂时没有想到应用之处。
众数:指一组数据中出现次数最多的那个数据,一组数据可以有多个众数,也可以没有众数。从分布角度看,众数是具有明显集中趋势的数值。众数不受极大或极小值的影响。众数的计算只有在总体比较多,而且又是明显集中于某个变量值时才具有意义,举个例子,比如我们看待游戏中交易成交的价格是多少,就可以利用计算众数帮助分析。
(http://wiki.mbalib.com/wiki/%E5%B9%B3%E5%9D%87%E6%95%B0)
中位数:将数据按大小顺序排列起来,形成一个数列,居于数列中间位置的那个数据。所研究的数据中有一半小于中位数,一半大于中位数。中位数的作用与算术平均数相近,也是作为所研究数据的代表值。在一个等差数列或一个正态分布数列中,中位数就等于算术平均数。
在数列中出现了极端变量值的情况下,用中位数作为代表值要比用算术平均数更好,因为中位数不受极端变量值的影响;如果研究目的就是为了反映中间水平,当然也应该用中位数。在统计数据的处理和分析时,可结合使用中位数。
在玩家的金币存留和消耗方面,我们会使用中位数作为一种辅助的分析思路,玩家的消费能力和充值能力会受到个人的能力等其他因素的影响,那么意味着这其中必然存在低端消费充值,也存在高端的消费充值,在使用算数平均数计算ARPU的同时,我们也利用中位数进行性付费客群的消费和充值的划分和研究,究竟在付费用户金子塔中,50%的消费充值居于什么样的水平,和ARPU的计算究竟差多少,如果是严格的正态分布,那么ARPU和中位数应该是一致的,但实际肯定不一致,我们要看看这个峰度系数究竟是多少,当然只看这个是不够的,在众数存在的情况下,结合这几个指标,横向和纵向的对比分析,能够帮助我们打开一下思路进行分析。
(http://wiki.mbalib.com/wiki/%E5%B9%B3%E5%9D%87%E6%95%B0)
全距:最大值与最小值之间的差距,离散程度的最简单测度值,易受极端值影响。
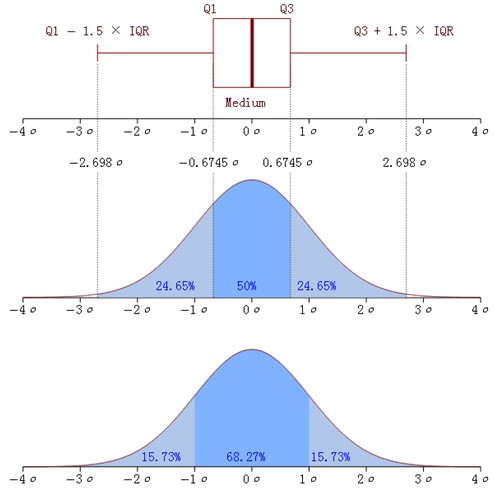
内距(四分位差):将一组数据从小到大升序排列,分成4等分,出于1/4,1/2,3/4的数就是四分位数,有关四分位数的一些内容可以参考箱线图那篇文章内容的描述。
平均差:总体所有单位与其算术平均数的离差绝对值的算术平均数。平均差是一种平均离差。离差是总体各单位的标志值与算术平均数之差。因离差和为零,离差的平均数不能将离差和除以离差的个数求得,而必须讲离差取绝对数来消除正负号。
平均差是反应各标志值与算术平均数之间的平均差异。平均差异大,表明各标志值与算术平均数的差异程度越大,该算术平均数的代表性就越小;平均差越小,表明各标志值与算术平均数的差异程度越小,该算术平均数的代表性就越大。
(http://baike.baidu.com/view/1244191.htm)
标准误:样本均数的标准差,是描述均数抽样分布的离散程度及衡量均数抽样误差大小的尺度,反映的是样本均数之间的变异。标准误不是标准差,是多个样本平均数的标准差。
标准误用来衡量抽样误差。标准误越小,表明样本统计量与总体参数的值越接近,样本对总体越有代表性,用样本统计量推断总体参数的可靠度越大。因此,标准误是统计推断可靠性的指标。
(http://baike.baidu.com/view/538412.htm)
离散系数:又称变异系数,是统计学当中的常用统计指标,主要用于比较不同水平的变量数列的离散程度及平均数的代表性。
变异系数是衡量资料中各观测值变异程度的一个统计量。当进行两个或多个资料变异程度的比较时,如果度量单位与平均数相同,可以直接利用标准差来比较。如果单位和(或)平均数不同时,比较其变异程度就不能采用标准差,而需采用标准差与平均数的比值(相对值)来比较。
(http://baike.baidu.com/view/108059.htm)
偏态系数:以平均值与中位数之差对标准差之比率来衡量偏斜的程度,偏态系数小于0,因为平均数在众数之左,是一种左偏的分布,又称为负偏。偏态系数大于0,因为均值在众数之右,是一种右偏的分布,又称为正偏。偏态系数是根据众数、中位数与均值各自的性质,通过比较众数或中位数与均值来衡量偏斜度的。
(http://baike.baidu.com/view/1393095.htm)
峰度系数:用四阶中心矩来测定峰度的,反映频数分布曲线顶端尖峭或扁平程度的指标,在正态分布情况下,峰度系数值是0。正的峰度系数说明观察量更集中,有比正态分布更长的尾部;负的峰度系数说明观测量不那么集中,有比正态分布更短的尾部
(http://baike.baidu.com/view/1265654.htm)
标准差:方差的算术平方根,反映组内个体间的离散程度。一组数据的平均值及标准差常常同时作为参考的依据。从某种意义上说,如果用平均值来考量数值的中心的话,则标准差也就是对统计的分散度的一个"自然"的测度。
(http://zh.wikipedia.org/wiki/%E6%A8%99%E6%BA%96%E5%B7%AE)
方差:描述离散程度,也就是该变量离其期望值的距离。
(http://zh.wikipedia.org/wiki/%E6%96%B9%E5%B7%AE)
P.S.这些都是一些统计上的术语,今天说的主要是描述统计方面的基本术语,这些不需要我去解释,只是这里通过我自己的搜索和学习,帮助各位新人了解和学习一下,知识很多,但不一定都要去学习,先把和工作有关,能帮助我们分析的术语了解,掌握,慢慢融汇的学习,每一个术语都有使用的范围和限定,大家要灵活和谨慎。当我们使用SPSS,SAS这些软件时会涉及这些术语,我们可能不需要了解具体是怎么计算的,但是我们起码要知道这些术语能代表什么含义,同时把这些计算出来的指标横向的和纵向的分析一下,不要只抓着一个中位数或者众数,你还要看到算术平均数等其它的指标,综合分析。这点很重要。关于这些指标的更加有力的解释,大家可以关注小蚊子的微博,最近他做了一个统计术语分享解释的内容,很不错,这里给大家地址(http://blog.sina.com.cn/s/blog_49f78a4b0102dwz9.html)
近期会给大家说说怎么通过SPSS进行描述性分析,大家可以自己看看研究一下,其实很简单,我只是做个帖子帮助新人热热身。