本文任何观点为作者观点,水平有限难免有误
关于组合索引不需要多谈就是多个列一起建立的索引,关于组合索引很常见的一个问题就是当谓词中出现了前导列才能够使用索引,如果
没有出现前导列是不能使用索引,当然index skip scan和index full scan除外。
理论如此,但是为什么谓词中没有前导列就不能使用索引,接下来通过DUMP来看看组合索引如何存放数据
建立测试表,为了方便论述和区别这里使用全数字同时组合索引的两个列完全是反序的:
create table testt1 (id1 number(10),id2 number(10),name varchar2(10));
declare
i number(10);
a number(10);
begin
for i in 1..100000
loop
select 100000-i into a from dual;
insert into testt1
values(i,a,'gaopeng');
end loop;
end;
create index testt1_c on testt1(id1,id2);
首先找到其OBJECT_ID,进行DUMP 索引结构
SQL> oradebug setmypid
Statement processed.
SQL> oradebug tracefile_name
/ora11g/diag/rdbms/test/test/trace/test_ora_14088.trc
SQL> alter session set events 'immediate trace name treedump level 76511';
查看其结构:
branch: 0x1000a43 16779843 (0: nrow: 290, level: 1)
leaf: 0x1000a44 16779844 (-1: nrow: 364 rrow: 364)
leaf: 0x1000a45 16779845 (0: nrow: 359 rrow: 359)
leaf: 0x1000a46 16779846 (1: nrow: 359 rrow: 359)
..................
leaf: 0x1000a6d 16779885 (38: nrow: 342 rrow: 342)
leaf: 0x1000a6e 16779886 (39: nrow: 342 rrow: 342)
leaf: 0x1000a6f 16779887 (40: nrow: 342 rrow: 342)
leaf: 0x1000a71 16779889 (41: nrow: 342 rrow: 342)
..................
leaf: 0x1000c19 16780313 (139: nrow: 342 rrow: 342)
leaf: 0x1000c1a 16780314 (140: nrow: 342 rrow: 342)
leaf: 0x1000c1b 16780315 (141: nrow: 342 rrow: 342)
leaf: 0x1000c1c 16780316 (142: nrow: 342 rrow: 342)
..................
leaf: 0x1000cad 16780461 (285: nrow: 359 rrow: 359)
leaf: 0x1000cae 16780462 (286: nrow: 359 rrow: 359)
leaf: 0x1000caf 16780463 (287: nrow: 359 rrow: 359)
leaf: 0x1000cb0 16780464 (288: nrow: 221 rrow: 221)
限于篇幅这里不能给出完整的DUMP,不过已经足够说明问题
这里可以看到本索引只有一个根节点然后就是叶节点
然后我们DUMP根节点:
进行DBA换算
SQL> select dbms_utility.data_block_address_file(16779843),
2 dbms_utility.data_block_address_block(16779843) from dual;
DBMS_UTILITY.DATA_BLOCK_ADDRES DBMS_UTILITY.DATA_BLOCK_ADDRES
------------------------------ ------------------------------
4 2627
进行DUMP
SQL> oradebug setmypid
Statement processed.
SQL> oradebug tracefile_name
/ora11g/diag/rdbms/test/test/trace/test_ora_14103.trc
SQL> alter system dump datafile 4 block 2627;
System altered.
这里去掉块的CACHE LAYER,TRASACTION LAYER,TABLE DIRECTORY,剩下可以说明问题的部分
同时去头去尾部,因为限于篇幅但是足够说明问题
......
kdxbrlmc 16779844=0x1000a44
......
row#0[8047] dba: 16779845=0x1000a45
col 0; len 3; (3): c2 04 42
col 1; TERM
row#1[8038] dba: 16779846=0x1000a46
col 0; len 3; (3): c2 08 19
col 1; TERM
row#2[8029] dba: 16779847=0x1000a47
col 0; len 3; (3): c2 0b 54
col 1; TERM
row#3[8020] dba: 16779848=0x1000a48
col 0; len 3; (3): c2 0f 2b
col 1; TERM
.........
row#284[5234] dba: 16780460=0x1000cac
col 0; len 4; (4): c3 0a 54 2d
col 1; TERM
row#285[5224] dba: 16780461=0x1000cad
col 0; len 4; (4): c3 0a 58 04
col 1; TERM
row#286[5214] dba: 16780462=0x1000cae
col 0; len 4; (4): c3 0a 5b 3f
col 1; TERM
row#287[5204] dba: 16780463=0x1000caf
col 0; len 4; (4): c3 0a 5f 16
col 1; TERM
row#288[5194] dba: 16780464=0x1000cb0
col 0; len 4; (4): c3 0a 62 51
col 1; TERM
这里可以看到这里排列是按照ID1进行的升序的排列,而根节点中压根就没有ID2,这个可以通过,查询索引状态看到是升序的
COLUMN_NAME DESCEND
-------------------------------------------------------------------------------- -------
ID1 ASC
ID2 ASC
对开头和结尾的2个页节点的值进行分析,这个值实际上叶节点的开始位置:
row#0[8047] dba: 16779845=0x1000a45
col 0; len 3; (3): c2 04 42
col 1; TERM
row#288[5194] dba: 16780464=0x1000cb0
col 0; len 4; (4): c3 0a 62 51
col 1; TERM
c2 04 42=(4-1)*100^(2-1)+(66-1)*100^(1-1)=300+65=365
c3 0a 62 51=(10-1)*100^(2-0)+(98-1)*100^(2-1)+(81-1)*100^(2-2)=99780
因为索引是排序好的所以这里快16779845的启始值是365,而结束值(不包含)是16779846的开始值
而16780464作为最后一个块99780是其起始值,结束值就是最后。
如果注意到COL 1这里是TERM,实际上非叶节点会有此标示
接下来我们对16779845和16780464块进行DUMP看看组合索引到底如何存储的,这里的16779845实际是索引叶节点的第二个块,第一个块
实际上是kdxbrlmc 16779844=0x1000a44
16779845进行DUMP:
row#0[8014] flag: ------, lock: 0, len=18
col 0; len 3; (3): c2 04 42
col 1; len 4; (4): c3 0a 61 24
col 2; len 6; (6): 01 00 09 c7 00 1e
row#1[7996] flag: ------, lock: 0, len=18
col 0; len 3; (3): c2 04 43
col 1; len 4; (4): c3 0a 61 23
col 2; len 6; (6): 01 00 09 c7 00 1f
.......
row#358[1578] flag: ------, lock: 0, len=18
col 0; len 3; (3): c2 08 18
col 1; len 4; (4): c3 0a 5d 4e
col 2; len 6; (6): 01 00 09 c3 00 3a
可以看到这里的第一个值是c2 04 42和根节点的DUMP出来的值是一致的,他们实际上是
ID1,ID2,ROWID的排列
16780464进行DUMP
row#0[8014] flag: ------, lock: 0, len=18
col 0; len 4; (4): c3 0a 62 51
col 1; len 3; (3): c2 03 15
col 2; len 6; (6): 01 00 0b 32 00 1e
row#1[7996] flag: ------, lock: 0, len=18
col 0; len 4; (4): c3 0a 62 52
col 1; len 3; (3): c2 03 14
col 2; len 6; (6): 01 00 0b 32 00 1f
...........
row#220[4161] flag: ------, lock: 0, len=14
col 0; len 2; (2): c3 0b
col 1; len 1; (1): 80
col 2; len 6; (6): 01 00 0b 32 00 fa
同样的可以看到第一个值c3 0a 62 51和根节点的DUMP出来的值也是一致的。
那么现在我们可以回答为什么当谓词中出现了前导列才能够使用索引,如果
没有出现前导列是不能使用索引了。
因为在根节点乃至分支节点中,压根就没有存储非前导列的值,B-TREE的结构完全
取决于前导列。
接下来我们来回答另外一个问题,当前导列值相同的情况下,其他非前导列是否进行了排序
我们在查看索引列信息的时候有如下标示
COLUMN_NAME DESCEND
-------------------------------------------------------------------------------- -------
ID1 ASC
ID2 ASC
可以看到ID2也是升序排列的,接下来我们我们来进行验证。
建立测试数据
create table testt2 (id1 number(10),id2 number(10),id3 number(10),name varchar2(10));
declare
i number(10);
begin
for i in 1..1000
loop
insert into testt2
values(i,round(dbms_random.value(1,5)),round(dbms_random.value(1,5)),'gaopeng');
insert into testt2
values(i,round(dbms_random.value(1,5)),round(dbms_random.value(1,5)),'gaopeng');
insert into testt2
values(i,round(dbms_random.value(1,5)),round(dbms_random.value(1,5)),'gaopeng');
insert into testt2
values(i,round(dbms_random.value(1,5)),round(dbms_random.value(1,5)),'gaopeng');
insert into testt2
values(i,round(dbms_random.value(1,5)),round(dbms_random.value(1,5)),'gaopeng');
insert into testt2
values(i,round(dbms_random.value(1,5)),round(dbms_random.value(1,5)),'gaopeng');
insert into testt2
values(i,round(dbms_random.value(1,5)),round(dbms_random.value(1,5)),'gaopeng');
insert into testt2
values(i,round(dbms_random.value(1,5)),round(dbms_random.value(1,5)),'gaopeng');
insert into testt2
values(i,round(dbms_random.value(1,5)),round(dbms_random.value(1,5)),'gaopeng');
insert into testt2
values(i,round(dbms_random.value(1,5)),round(dbms_random.value(1,5)),'gaopeng');
end loop;
end;
create index testt2_c on testt2(id1,id2,id3);
如此我们对每个数据都插入10次,同时ID2,ID3取随机值,然后建立ID1,ID2,ID3的联合索引。
我们取出其中一个片段进行分析
SQL> select dbms_rowid.rowid_block_number(rowid),dbms_rowid.rowid_row_number(rowid),testt2.*from testt2 where id1=5 order by dbms_rowid.rowid_row_number(rowid);
DBMS_ROWID.ROWID_BLOCK_NUMBER( DBMS_ROWID.ROWID_ROW_NUMBER(RO ID1 ID2 ID3 NAME
------------------------------ ------------------------------ ----------- ----------- ----------- ----------
3014 40 5 1 2 gaopeng
3014 41 5 4 4 gaopeng
3014 42 5 3 4 gaopeng
3014 43 5 4 2 gaopeng
3014 44 5 3 3 gaopeng
3014 45 5 2 2 gaopeng
3014 46 5 5 3 gaopeng
3014 47 5 4 1 gaopeng
3014 48 5 5 3 gaopeng
3014 49 5 4 4 gaopeng
可以看到在块中ID2和ID3的数据排列实际上是杂乱无章的。本来嘛就是随机输出的。
但是如果我们不用dbms_rowid.rowid_row_number(rowid)排序得出的结果如下:
SQL> select * from testt2 where id1=5;
ID1 ID2 ID3 NAME
----------- ----------- ----------- ----------
5 1 2 gaopeng
5 2 2 gaopeng
5 3 3 gaopeng
5 3 4 gaopeng
5 4 1 gaopeng
5 4 2 gaopeng
5 4 4 gaopeng
5 4 4 gaopeng
5 5 3 gaopeng
5 5 3 gaopeng
大概分析为什么得到这样的结果呢,ID2都是排序好的 ID3也是ID2相同值的排序,犹如ORDER BY ID1,ID2,ID3
,其实没什么奇怪的这里ID1=5走了索引扫描,索引扫描是排序好了,同时这也从侧面反映了一个事实,
当ID1相同的情况ID2排序,ID2相同的情况下ID3排序,可以看看如下的执行计划,这里根本就没有ORDER的执行步骤
说明排序已经完成消除。
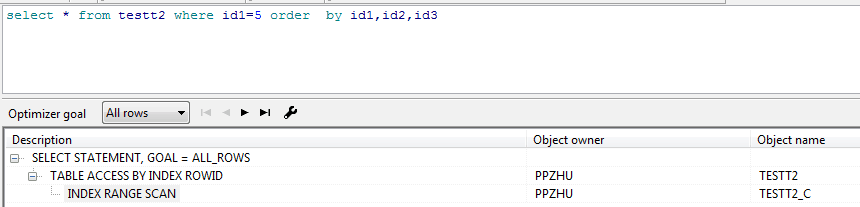
记住堆表示不排序的,任何时候都不,索引是排序的,当通过索引ROWID回表取数据的时候当然也就排好了顺序。
接下来我们还是进行一次DUMP说明,通过DUMP取出关于ID1=5的记录
row#40[7294] flag: ------, lock: 0, len=18
col 0; len 2; (2): c1 06
col 1; len 2; (2): c1 02
col 2; len 2; (2): c1 03
col 3; len 6; (6): 01 00 0b c6 00 28
row#41[7276] flag: ------, lock: 0, len=18
col 0; len 2; (2): c1 06
col 1; len 2; (2): c1 03
col 2; len 2; (2): c1 03
col 3; len 6; (6): 01 00 0b c6 00 2d
row#42[7258] flag: ------, lock: 0, len=18
col 0; len 2; (2): c1 06
col 1; len 2; (2): c1 04
col 2; len 2; (2): c1 04
col 3; len 6; (6): 01 00 0b c6 00 2c
row#43[7240] flag: ------, lock: 0, len=18
col 0; len 2; (2): c1 06
col 1; len 2; (2): c1 04
col 2; len 2; (2): c1 05
col 3; len 6; (6): 01 00 0b c6 00 2a
row#44[7222] flag: ------, lock: 0, len=18
col 0; len 2; (2): c1 06
col 1; len 2; (2): c1 05
col 2; len 2; (2): c1 02
col 3; len 6; (6): 01 00 0b c6 00 2f
row#45[7204] flag: ------, lock: 0, len=18
col 0; len 2; (2): c1 06
col 1; len 2; (2): c1 05
col 2; len 2; (2): c1 03
col 3; len 6; (6): 01 00 0b c6 00 2b
row#46[7186] flag: ------, lock: 0, len=18
col 0; len 2; (2): c1 06
col 1; len 2; (2): c1 05
col 2; len 2; (2): c1 05
col 3; len 6; (6): 01 00 0b c6 00 29
row#47[7168] flag: ------, lock: 0, len=18
col 0; len 2; (2): c1 06
col 1; len 2; (2): c1 05
col 2; len 2; (2): c1 05
col 3; len 6; (6): 01 00 0b c6 00 31
row#48[7150] flag: ------, lock: 0, len=18
col 0; len 2; (2): c1 06
col 1; len 2; (2): c1 06
col 2; len 2; (2): c1 04
col 3; len 6; (6): 01 00 0b c6 00 2e
row#49[7132] flag: ------, lock: 0, len=18
col 0; len 2; (2): c1 06
col 1; len 2; (2): c1 06
col 2; len 2; (2): c1 04
col 3; len 6; (6): 01 00 0b c6 00 30
这已经不用太多分析通过换算实际上他的顺序就是
ID1 ID2 ID3
----------- ----------- -----------
5 1 2
5 2 2
5 3 3
5 3 4
5 4 1
5 4 2
5 4 4
5 4 4
5 5 3
5 5 3
如此我们又证明的一个问题当前导列相同的情况下组合索引的其他的列实际上
按照ORDER的方式进行排序实际上就是order by col1,col2,col3
,可以猜想这样的构架为index skip scan提供了可能,在索引跳跃扫描的情况下
索引实际上被分为多个按照前导列分割的多个片段,然后进行分别扫描,因为是
后续的列是排序好的,这样代价就大大减少,在崔华的基于ORACLE的SQL优化一书
中也描述为对前导列做DISTINCT值遍历,可以想象这样的方式只适合前导列不同值
很少,而且非前导列选择率高的情况。
最后我们进行总结:
1、因为在根节点乃至分支节点中,压根就没有存储非前导列的值,B-TREE的结构完全
取决于前导列,所以普通索引扫描依赖前导列来通过B-TREE结构进行快速定位搜索
2、当前导列相同的情况下组合索引的其他的列实际上按照ORDER的方式进行排序
实际上就是order by col1,col2,col3
3、index skip scan提供了可能,在索引跳跃扫描的情况下
索引实际上被分为多个按照前导列分割的多个片段,然后进行分别扫描,因为是
后续的列是排序好的,这样代价就大大减少
4、由于这样一种结构通过索引回表后的数据是排序好的,为通过索引访问回表消除排序提供了支持

![[Oracle]索引](https://ucc.alicdn.com/pic/developer-ecology/3mfxe2r26qbaq_c50f50e14c2447959ba0c272c4967106.jpeg?x-oss-process=image/resize,h_160,m_lfit)