今天看到MYSQL手册的Index Merge Optimization,不禁有一些想法,所以记录如下文
先来解释下2种方式不同:
这两种方式都使用一个table中的不同二级索引进行,注意是单个表。
merge union :在使用or的时候如果二级索引包含了所有的key part,那么就可以得到排序好的聚集索引的键值或者ROWID,那么简单的union 去重就可以了,不需要额外的排序
源码接口quick_ror_union_select类
merge sort_union :和上面的不同的是没有包含二级索引所有的key part,那么要首先要获得排序好的聚集索引键值或者ROWID,才能对聚集索引键值或者ROWID进行union操作
源码接口quick_index_merge_select
参考手册:9.2.1.4 Index Merge Optimization
总的来说只要mysql 不能确定主键是排序好的方式就需要额外的排序操作。
如果我们对merge sort算法有一定了解,可以看到这样的处理是必须的,
我们知道在进行归并的时候所有的需要归并的子集是需要排序好的,下面是一个简单的归并算法的图解:
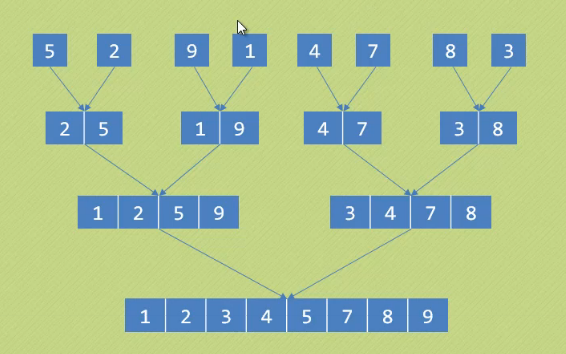
如果我们把 1 2 5 9 和 3 4 7 8看成primary key 那么他们就是要排序好才能完成最后的归并,
当然上层的排序操作可以归并也可以用其他排序方式,只要排序好就可以,另外提一点,归并
排序熟悉数据结构的朋友应该知道他也是外部磁盘排序的一种好方式。
这里要理解我们需要对组合索引在INNODB B+树页块的排列有一个了解:
比如:seq int,id1 int,id2 int seq是主键,ID1,DI2是一个组合B+索引
那么我们插入值
values(1,1,2)
values(2,1,3)
values(3,1,2)
显然在组合索引的叶节点排列顺序如下:
1 2 3
id1:1 id1:1 id1:1
id2:2 id2:2 id2:3
seq:1 seq:3 seq:2
也就是先按照id1进行排序然后按照id2排序最后按照主键seq排序.
那么可以看到最后主键的顺序为 1 3 2并不是有序的,很明显这样的
结果集不能作为归并的结果集,那么我们就需要进行排序,这也是为什么
sort_union sort的来源。
那么下面来演示2种执行计划的不同
脚本:
create table testmer
(seq int,id1 int,id2 int,id3 int,id4 int,primary key(seq),key(id1,id2),key(id3,id4));
insert into testmer values(1,1,2,4,4);
insert into testmer values(2,1,3,4,5);
insert into testmer values(3,1,2,4,4);
insert into testmer values(4,2,4,5,6);
insert into testmer values(5,2,6,5,8);
insert into testmer values(6,2,10,5,3);
insert into testmer values(7,4,5,8,10);
insert into testmer values(8,0,1,3,4);
mysql> select * from testmer;
+-----+------+------+------+------+
| seq | id1 | id2 | id3 | id4 |
+-----+------+------+------+------+
| 1 | 1 | 2 | 4 | 4 |
| 2 | 1 | 3 | 4 | 5 |
| 3 | 1 | 2 | 4 | 4 |
| 4 | 2 | 4 | 5 | 6 |
| 5 | 2 | 6 | 5 | 8 |
| 6 | 2 | 10 | 5 | 3 |
| 7 | 4 | 5 | 8 | 10 |
| 8 | 0 | 1 | 3 | 4 |
+-----+------+------+------+------+
Using sort_union:
mysql> explain select * from testmer force index(id1,id3) where id1=1 or id3=4;
+----+-------------+---------+------------+-------------+---------------+---------+---------+------+------+----------+----------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------------+---------------+---------+---------+------+------+----------+----------------------------------------+
| 1 | SIMPLE | testmer | NULL | index_merge | id1,id3 | id1,id3 | 5,5 | NULL | 6 | 100.00 | Using sort_union(id1,id3); Using where |
+----+-------------+---------+------------+-------------+---------------+---------+---------+------+------+----------+----------------------------------------+
1 row in set, 1 warning (5.07 sec)
很明显这里只看 key(id1,id2) 就需要排序了,因为排列如下:
1 2 3
id1:1 id1:1 id1:1
id2:2 id2:2 id2:3
seq:1 seq:3 seq:2
如果我们把二级索引KEY_PART带全
mysql> explain select * from testmer force index(id1,id3) where id1=1 and id2=2 or id3=4 and id4=1;
+----+-------------+---------+------------+-------------+---------------+---------+---------+------+------+----------+-----------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------------+---------------+---------+---------+------+------+----------+-----------------------------------+
| 1 | SIMPLE | testmer | NULL | index_merge | id1,id3 | id1,id3 | 10,10 | NULL | 2 | 100.00 | Using union(id1,id3); Using where |
+----+-------------+---------+------------+-------------+---------------+---------+---------+------+------+----------+-----------------------------------+
这里当然不需要排序我们看 id1=1 and id2=2(id3=4 and id4=1 也是一样)
排列如下:
1 2
id1:1 id1:1
id2:2 id2:2
seq:1 seq:3
也就说如果KEY_PART包含完整那么主键自然排序好的结果,
其实我是在DEBUG环境下跑的,断点打在了Unique::unique_add
(gdb) info b
Num Type Disp Enb Address What
1 breakpoint keep y 0x0000000000ebd333 in main(int, char**) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/main.cc:25
breakpoint already hit 1 time
6 breakpoint keep y 0x000000000145de13 in Unique::unique_add(void*) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/uniques.h:52
breakpoint already hit 2 times
在执行select * from testmer force index(id1,id3) where id1=1 and id2=1 or id3=4 and id4=1;
没有触发Unique::unique_add,也就是没有进行排序操作。
最后说明下源码的merge_sort 排序的接口
QUICK_INDEX_MERGE_SELECT::read_keys_and_merge()
调用
Unique::unique_add
(使用balanced binary trees,平衡二叉树非红黑树区别参考:
http://blog.itpub.net/7728585/viewspace-2127419/
)
下面是源码read_keys_and_merge()的注释:
/*
Perform key scans for all used indexes (except CPK), get rowids and merge
them into an ordered non-recurrent sequence of rowids.
The merge/duplicate removal is performed using Unique class. We put all
rowids into Unique, get the sorted sequence and destroy the Unique.
If table has a clustered primary key that covers all rows (TRUE for bdb
and innodb currently) and one of the index_merge scans is a scan on PK,
then rows that will be retrieved by PK scan are not put into Unique and
primary key scan is not performed here, it is performed later separately.
RETURN
0 OK
other error
*/
下面是我gdb时候的堆栈信息:
(gdb) bt
#0 tree_insert (tree=0x7fffd801c768, key=0x7fffd801ada0, key_size=0, custom_arg=0x7fffd80103d0) at /root/mysql5.7.14/percona-server-5.7.14-7/mysys/tree.c:207
#1 0x000000000145df19 in Unique::unique_add (this=0x7fffd801c260, ptr=0x7fffd801ada0) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/uniques.h:56
#2 0x000000000178e6a8 in QUICK_INDEX_MERGE_SELECT::read_keys_and_merge (this=0x7fffd89083f0) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/opt_range.cc:10700
#3 0x0000000001778c73 in QUICK_INDEX_MERGE_SELECT::reset (this=0x7fffd89083f0) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/opt_range.cc:1601
#4 0x000000000155e529 in join_init_read_record (tab=0x7fffd8906e20) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_executor.cc:2471
#5 0x000000000155b6a1 in sub_select (join=0x7fffd8905b08, qep_tab=0x7fffd8906e20, end_of_records=false)
at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_executor.cc:1271
#6 0x000000000155b026 in do_select (join=0x7fffd8905b08) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_executor.cc:944
#7 0x0000000001558efc in JOIN::exec (this=0x7fffd8905b08) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_executor.cc:199
#8 0x00000000015f91c6 in handle_query (thd=0x7fffd8000df0, lex=0x7fffd80033d0, result=0x7fffd8007a60, added_options=0, removed_options=0)
at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_select.cc:184
#9 0x00000000015ac025 in execute_sqlcom_select (thd=0x7fffd8000df0, all_tables=0x7fffd8006e98) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_parse.cc:5391
#10 0x00000000015a4640 in mysql_execute_command (thd=0x7fffd8000df0, first_level=true) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_parse.cc:2889
#11 0x00000000015acff6 in mysql_parse (thd=0x7fffd8000df0, parser_state=0x7ffff0fd6600) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_parse.cc:5836
#12 0x00000000015a0eb5 in dispatch_command (thd=0x7fffd8000df0, com_data=0x7ffff0fd6d70, command=COM_QUERY)
at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_parse.cc:1447
#13 0x000000000159fce6 in do_command (thd=0x7fffd8000df0) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_parse.cc:1010
#14 0x00000000016e1c08 in handle_connection (arg=0x3c1c880) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/conn_handler/connection_handler_per_thread.cc:312
#15 0x0000000001d71ed0 in pfs_spawn_thread (arg=0x3bec1b0) at /root/mysql5.7.14/percona-server-5.7.14-7/storage/perfschema/pfs.cc:2188
#16 0x0000003ca62079d1 in start_thread () from /lib64/libpthread.so.0
#17 0x0000003ca5ee8b6d in clone () from /lib64/libc.so.6
再附上2种方式函数接口调用情况:
merge sort_union:
T@3: | | | | | | | | | | >QUICK_INDEX_MERGE_SELECT::QUICK_INDEX_MERGE_SELECT
T@3: | | | | | | | | | | <QUICK_INDEX_MERGE_SELECT::QUICK_INDEX_MERGE_SELECT 1589
T@3: | | | | | | | | | | >QUICK_INDEX_MERGE_SELECT::init
T@3: | | | | | | | | | | <QUICK_INDEX_MERGE_SELECT::init 1595
T@3: | | | | | | | | >QUICK_INDEX_MERGE_SELECT::reset
T@3: | | | | | | | | | >QUICK_INDEX_MERGE_SELECT::read_keys_and_merge
T@3: | | | | | | | | | <QUICK_INDEX_MERGE_SELECT::read_keys_and_merge 10716
T@3: | | | | | | | | <QUICK_INDEX_MERGE_SELECT::reset 1602
T@3: | | | | | | | | >QUICK_INDEX_MERGE_SELECT::get_next
T@3: | | | | | | | | <QUICK_INDEX_MERGE_SELECT::get_next 10753
T@3: | | | | | | | | >QUICK_INDEX_MERGE_SELECT::get_next
T@3: | | | | | | | | <QUICK_INDEX_MERGE_SELECT::get_next 10753
T@3: | | | | | | | | >QUICK_INDEX_MERGE_SELECT::get_next
T@3: | | | | | | | | <QUICK_INDEX_MERGE_SELECT::get_next 10753
T@3: | | | | | | | | >QUICK_INDEX_MERGE_SELECT::get_next
T@3: | | | | | | | | <QUICK_INDEX_MERGE_SELECT::get_next 10753
T@3: | | | | | | | >QUICK_INDEX_MERGE_SELECT::~QUICK_INDEX_MERGE_SELECT
T@3: | | | | | | | <QUICK_INDEX_MERGE_SELECT::~QUICK_INDEX_MERGE_SELECT 1635
merge union:
T@3: | | | | | | | | | | >QUICK_ROR_UNION_SELECT::init
T@3: | | | | | | | | | | <QUICK_ROR_UNION_SELECT::init 1942
T@3: | | | | | | | | >QUICK_ROR_UNION_SELECT::reset
T@3: | | | | | | | | <QUICK_ROR_UNION_SELECT::reset 2004
T@3: | | | | | | | | >QUICK_ROR_UNION_SELECT::get_next
T@3: | | | | | | | | <QUICK_ROR_UNION_SELECT::get_next 10948
T@3: | | | | | | | | >QUICK_ROR_UNION_SELECT::get_next
T@3: | | | | | | | | <QUICK_ROR_UNION_SELECT::get_next 10948
T@3: | | | | | | | | >QUICK_ROR_UNION_SELECT::get_next
T@3: | | | | | | | | <QUICK_ROR_UNION_SELECT::get_next 10913
T@3: | | | | | | | >QUICK_ROR_UNION_SELECT::~QUICK_ROR_UNION_SELECT
T@3: | | | | | | | <QUICK_ROR_UNION_SELECT::~QUICK_ROR_UNION_SELECT 2021
可以看到调用路径,查看源码调用情况我只是想证明确实进行了排序,然后看看使用的什么方式排序.
本文只代表个人观点,如果有误起提示。谢谢!
先来解释下2种方式不同:
这两种方式都使用一个table中的不同二级索引进行,注意是单个表。
merge union :在使用or的时候如果二级索引包含了所有的key part,那么就可以得到排序好的聚集索引的键值或者ROWID,那么简单的union 去重就可以了,不需要额外的排序
源码接口quick_ror_union_select类
merge sort_union :和上面的不同的是没有包含二级索引所有的key part,那么要首先要获得排序好的聚集索引键值或者ROWID,才能对聚集索引键值或者ROWID进行union操作
源码接口quick_index_merge_select
参考手册:9.2.1.4 Index Merge Optimization
总的来说只要mysql 不能确定主键是排序好的方式就需要额外的排序操作。
如果我们对merge sort算法有一定了解,可以看到这样的处理是必须的,
我们知道在进行归并的时候所有的需要归并的子集是需要排序好的,下面是一个简单的归并算法的图解:
如果我们把 1 2 5 9 和 3 4 7 8看成primary key 那么他们就是要排序好才能完成最后的归并,
当然上层的排序操作可以归并也可以用其他排序方式,只要排序好就可以,另外提一点,归并
排序熟悉数据结构的朋友应该知道他也是外部磁盘排序的一种好方式。
这里要理解我们需要对组合索引在INNODB B+树页块的排列有一个了解:
比如:seq int,id1 int,id2 int seq是主键,ID1,DI2是一个组合B+索引
那么我们插入值
values(1,1,2)
values(2,1,3)
values(3,1,2)
显然在组合索引的叶节点排列顺序如下:
1 2 3
id1:1 id1:1 id1:1
id2:2 id2:2 id2:3
seq:1 seq:3 seq:2
也就是先按照id1进行排序然后按照id2排序最后按照主键seq排序.
那么可以看到最后主键的顺序为 1 3 2并不是有序的,很明显这样的
结果集不能作为归并的结果集,那么我们就需要进行排序,这也是为什么
sort_union sort的来源。
那么下面来演示2种执行计划的不同
脚本:
create table testmer
(seq int,id1 int,id2 int,id3 int,id4 int,primary key(seq),key(id1,id2),key(id3,id4));
insert into testmer values(1,1,2,4,4);
insert into testmer values(2,1,3,4,5);
insert into testmer values(3,1,2,4,4);
insert into testmer values(4,2,4,5,6);
insert into testmer values(5,2,6,5,8);
insert into testmer values(6,2,10,5,3);
insert into testmer values(7,4,5,8,10);
insert into testmer values(8,0,1,3,4);
mysql> select * from testmer;
+-----+------+------+------+------+
| seq | id1 | id2 | id3 | id4 |
+-----+------+------+------+------+
| 1 | 1 | 2 | 4 | 4 |
| 2 | 1 | 3 | 4 | 5 |
| 3 | 1 | 2 | 4 | 4 |
| 4 | 2 | 4 | 5 | 6 |
| 5 | 2 | 6 | 5 | 8 |
| 6 | 2 | 10 | 5 | 3 |
| 7 | 4 | 5 | 8 | 10 |
| 8 | 0 | 1 | 3 | 4 |
+-----+------+------+------+------+
Using sort_union:
mysql> explain select * from testmer force index(id1,id3) where id1=1 or id3=4;
+----+-------------+---------+------------+-------------+---------------+---------+---------+------+------+----------+----------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------------+---------------+---------+---------+------+------+----------+----------------------------------------+
| 1 | SIMPLE | testmer | NULL | index_merge | id1,id3 | id1,id3 | 5,5 | NULL | 6 | 100.00 | Using sort_union(id1,id3); Using where |
+----+-------------+---------+------------+-------------+---------------+---------+---------+------+------+----------+----------------------------------------+
1 row in set, 1 warning (5.07 sec)
很明显这里只看 key(id1,id2) 就需要排序了,因为排列如下:
1 2 3
id1:1 id1:1 id1:1
id2:2 id2:2 id2:3
seq:1 seq:3 seq:2
如果我们把二级索引KEY_PART带全
mysql> explain select * from testmer force index(id1,id3) where id1=1 and id2=2 or id3=4 and id4=1;
+----+-------------+---------+------------+-------------+---------------+---------+---------+------+------+----------+-----------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------------+---------------+---------+---------+------+------+----------+-----------------------------------+
| 1 | SIMPLE | testmer | NULL | index_merge | id1,id3 | id1,id3 | 10,10 | NULL | 2 | 100.00 | Using union(id1,id3); Using where |
+----+-------------+---------+------------+-------------+---------------+---------+---------+------+------+----------+-----------------------------------+
这里当然不需要排序我们看 id1=1 and id2=2(id3=4 and id4=1 也是一样)
排列如下:
1 2
id1:1 id1:1
id2:2 id2:2
seq:1 seq:3
也就说如果KEY_PART包含完整那么主键自然排序好的结果,
其实我是在DEBUG环境下跑的,断点打在了Unique::unique_add
(gdb) info b
Num Type Disp Enb Address What
1 breakpoint keep y 0x0000000000ebd333 in main(int, char**) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/main.cc:25
breakpoint already hit 1 time
6 breakpoint keep y 0x000000000145de13 in Unique::unique_add(void*) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/uniques.h:52
breakpoint already hit 2 times
在执行select * from testmer force index(id1,id3) where id1=1 and id2=1 or id3=4 and id4=1;
没有触发Unique::unique_add,也就是没有进行排序操作。
最后说明下源码的merge_sort 排序的接口
QUICK_INDEX_MERGE_SELECT::read_keys_and_merge()
调用
Unique::unique_add
(使用balanced binary trees,平衡二叉树非红黑树区别参考:
http://blog.itpub.net/7728585/viewspace-2127419/
)
下面是源码read_keys_and_merge()的注释:
/*
Perform key scans for all used indexes (except CPK), get rowids and merge
them into an ordered non-recurrent sequence of rowids.
The merge/duplicate removal is performed using Unique class. We put all
rowids into Unique, get the sorted sequence and destroy the Unique.
If table has a clustered primary key that covers all rows (TRUE for bdb
and innodb currently) and one of the index_merge scans is a scan on PK,
then rows that will be retrieved by PK scan are not put into Unique and
primary key scan is not performed here, it is performed later separately.
RETURN
0 OK
other error
*/
下面是我gdb时候的堆栈信息:
(gdb) bt
#0 tree_insert (tree=0x7fffd801c768, key=0x7fffd801ada0, key_size=0, custom_arg=0x7fffd80103d0) at /root/mysql5.7.14/percona-server-5.7.14-7/mysys/tree.c:207
#1 0x000000000145df19 in Unique::unique_add (this=0x7fffd801c260, ptr=0x7fffd801ada0) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/uniques.h:56
#2 0x000000000178e6a8 in QUICK_INDEX_MERGE_SELECT::read_keys_and_merge (this=0x7fffd89083f0) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/opt_range.cc:10700
#3 0x0000000001778c73 in QUICK_INDEX_MERGE_SELECT::reset (this=0x7fffd89083f0) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/opt_range.cc:1601
#4 0x000000000155e529 in join_init_read_record (tab=0x7fffd8906e20) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_executor.cc:2471
#5 0x000000000155b6a1 in sub_select (join=0x7fffd8905b08, qep_tab=0x7fffd8906e20, end_of_records=false)
at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_executor.cc:1271
#6 0x000000000155b026 in do_select (join=0x7fffd8905b08) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_executor.cc:944
#7 0x0000000001558efc in JOIN::exec (this=0x7fffd8905b08) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_executor.cc:199
#8 0x00000000015f91c6 in handle_query (thd=0x7fffd8000df0, lex=0x7fffd80033d0, result=0x7fffd8007a60, added_options=0, removed_options=0)
at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_select.cc:184
#9 0x00000000015ac025 in execute_sqlcom_select (thd=0x7fffd8000df0, all_tables=0x7fffd8006e98) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_parse.cc:5391
#10 0x00000000015a4640 in mysql_execute_command (thd=0x7fffd8000df0, first_level=true) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_parse.cc:2889
#11 0x00000000015acff6 in mysql_parse (thd=0x7fffd8000df0, parser_state=0x7ffff0fd6600) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_parse.cc:5836
#12 0x00000000015a0eb5 in dispatch_command (thd=0x7fffd8000df0, com_data=0x7ffff0fd6d70, command=COM_QUERY)
at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_parse.cc:1447
#13 0x000000000159fce6 in do_command (thd=0x7fffd8000df0) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/sql_parse.cc:1010
#14 0x00000000016e1c08 in handle_connection (arg=0x3c1c880) at /root/mysql5.7.14/percona-server-5.7.14-7/sql/conn_handler/connection_handler_per_thread.cc:312
#15 0x0000000001d71ed0 in pfs_spawn_thread (arg=0x3bec1b0) at /root/mysql5.7.14/percona-server-5.7.14-7/storage/perfschema/pfs.cc:2188
#16 0x0000003ca62079d1 in start_thread () from /lib64/libpthread.so.0
#17 0x0000003ca5ee8b6d in clone () from /lib64/libc.so.6
再附上2种方式函数接口调用情况:
merge sort_union:
T@3: | | | | | | | | | | >QUICK_INDEX_MERGE_SELECT::QUICK_INDEX_MERGE_SELECT
T@3: | | | | | | | | | | <QUICK_INDEX_MERGE_SELECT::QUICK_INDEX_MERGE_SELECT 1589
T@3: | | | | | | | | | | >QUICK_INDEX_MERGE_SELECT::init
T@3: | | | | | | | | | | <QUICK_INDEX_MERGE_SELECT::init 1595
T@3: | | | | | | | | >QUICK_INDEX_MERGE_SELECT::reset
T@3: | | | | | | | | | >QUICK_INDEX_MERGE_SELECT::read_keys_and_merge
T@3: | | | | | | | | | <QUICK_INDEX_MERGE_SELECT::read_keys_and_merge 10716
T@3: | | | | | | | | <QUICK_INDEX_MERGE_SELECT::reset 1602
T@3: | | | | | | | | >QUICK_INDEX_MERGE_SELECT::get_next
T@3: | | | | | | | | <QUICK_INDEX_MERGE_SELECT::get_next 10753
T@3: | | | | | | | | >QUICK_INDEX_MERGE_SELECT::get_next
T@3: | | | | | | | | <QUICK_INDEX_MERGE_SELECT::get_next 10753
T@3: | | | | | | | | >QUICK_INDEX_MERGE_SELECT::get_next
T@3: | | | | | | | | <QUICK_INDEX_MERGE_SELECT::get_next 10753
T@3: | | | | | | | | >QUICK_INDEX_MERGE_SELECT::get_next
T@3: | | | | | | | | <QUICK_INDEX_MERGE_SELECT::get_next 10753
T@3: | | | | | | | >QUICK_INDEX_MERGE_SELECT::~QUICK_INDEX_MERGE_SELECT
T@3: | | | | | | | <QUICK_INDEX_MERGE_SELECT::~QUICK_INDEX_MERGE_SELECT 1635
merge union:
T@3: | | | | | | | | | | >QUICK_ROR_UNION_SELECT::init
T@3: | | | | | | | | | | <QUICK_ROR_UNION_SELECT::init 1942
T@3: | | | | | | | | >QUICK_ROR_UNION_SELECT::reset
T@3: | | | | | | | | <QUICK_ROR_UNION_SELECT::reset 2004
T@3: | | | | | | | | >QUICK_ROR_UNION_SELECT::get_next
T@3: | | | | | | | | <QUICK_ROR_UNION_SELECT::get_next 10948
T@3: | | | | | | | | >QUICK_ROR_UNION_SELECT::get_next
T@3: | | | | | | | | <QUICK_ROR_UNION_SELECT::get_next 10948
T@3: | | | | | | | | >QUICK_ROR_UNION_SELECT::get_next
T@3: | | | | | | | | <QUICK_ROR_UNION_SELECT::get_next 10913
T@3: | | | | | | | >QUICK_ROR_UNION_SELECT::~QUICK_ROR_UNION_SELECT
T@3: | | | | | | | <QUICK_ROR_UNION_SELECT::~QUICK_ROR_UNION_SELECT 2021
可以看到调用路径,查看源码调用情况我只是想证明确实进行了排序,然后看看使用的什么方式排序.
本文只代表个人观点,如果有误起提示。谢谢!