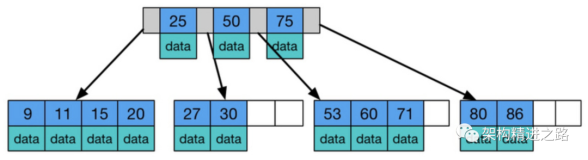
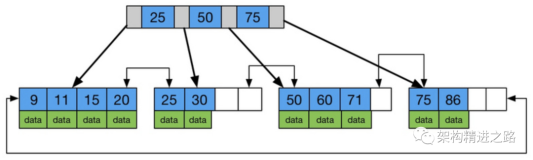
为了描述这个技巧,我们将使用AdventureWorks数据库的一张表并查询这张表。我使用的这张表是Person.Address。下面的屏幕截图显示了这张表当前的结构。我们可以看到在这张表有四个索引。
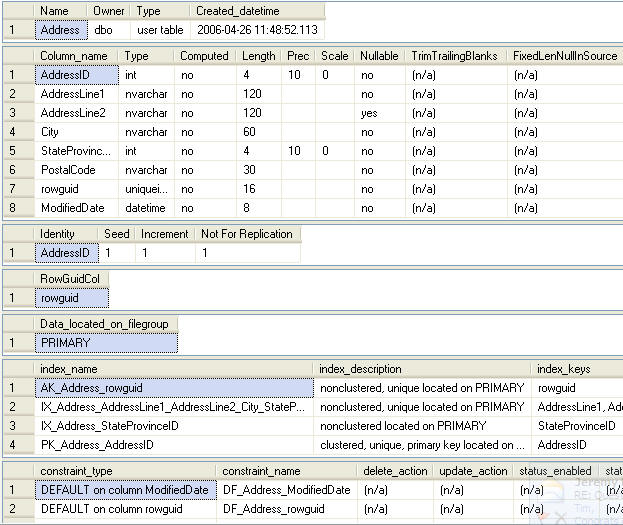
图一
为了搜集一些索引使用资料,我将在AdventureWorks数据库中运行下面的查询5次。
| SELECT AddressLine1, AddressLine2 FROM Person.Address WHERE StateProvinceID = 1 |

图二
这个索引查找扫描一个非聚簇索引来查找与提供值匹配的记录。
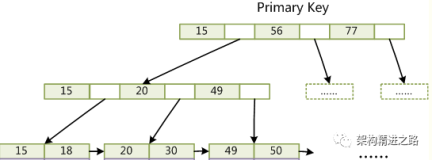
关键查找用于查找聚簇索引中的实际数据。
要看这些索引实际上是如何使用的,我们可以执行下面的查询。
| SELECT OBJECT_NAME(S.[OBJECT_ID]) AS [OBJECT NAME], I.[NAME] AS [INDEX NAME], USER_SEEKS, USER_SCANS, USER_LOOKUPS, USER_UPDATES FROM sys.dm_db_index_usage_stats AS S INNER JOIN sys.indexes AS I ON I.[OBJECT_ID] = S.[OBJECT_ID] AND I.INDEX_ID = S.INDEX_ID WHERE OBJECT_NAME(S.[OBJECT_ID]) = 'Address' |

图三
如果这是一个用户如何访问我们的数据库的真正情况,那么我们可以得出结论:索引IX_Address_StateProvinceID可以是一个更好的聚簇索引,因为我们向来在这个字段上查找,因此我们可以消除这个占据了我们执行计划96%的关键词查找。
既然我们知道了自己想把StateProvinceID当作聚簇索引来使用,因此我们需要进行下面一些步骤。我们需要删除现有的主键/聚簇索引,但是由于外码参照了这张表,因此我们也需要删除它们。下面的查询教你怎样删除外码、主码并创建新的聚簇索引。在一个实际情况下,你可能想重新创建这个主码,也想输出这些外码的创建,因此在你做了这些更改之后,你可能会重新创建它们。
| ALTER TABLE [HumanResources].[EmployeeAddress] DROP CONSTRAINT [FK_EmployeeAddress_Address_AddressID] ALTER TABLE [Sales].[CustomerAddress] DROP CONSTRAINT [FK_CustomerAddress_Address_AddressID] ALTER TABLE [Purchasing].[VendorAddress] DROP CONSTRAINT [FK_VendorAddress_Address_AddressID] ALTER TABLE [Sales].[SalesOrderHeader] DROP CONSTRAINT [FK_SalesOrderHeader_Address_ShipToAddressID] ALTER TABLE [Sales].[SalesOrderHeader] DROP CONSTRAINT [FK_SalesOrderHeader_Address_BillToAddressID] ALTER TABLE Person.Address DROP CONSTRAINT PK_Address_AddressID CREATE CLUSTERED INDEX IX_StateProvinceID ON Person.Address(StateProvinceID)
|
现在既然我们创建了新的聚簇索引,那么我们可以重新查询这张表并看到新的执行计划是什么样的。
| SELECT AddressLine1, AddressLine2 FROM Person.Address WHERE StateProvinceID = 1 |
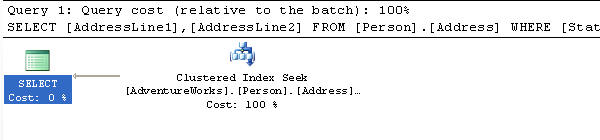
图四
如果我们查询这个索引使用统计资料,我们也可以看到它们的差异。现在我们只有USER_SEEKS,而不再有USER_LOOKUPS。要注意的一点是当你更改一张表上的索引时,这些统计资料将重置为0。所以看起来这些改变对于我们的表来说是一种成功。

图五