拨开云雾见天日……
一.问题引入
昨晚和老婆深入交流了下,得出了重大结论:必须要创业。
最后一次给孩子们讲课讲的这个,不过效果不怎么理想,一问才知道大一的说只要一涉及到树就不懂了,我就怀疑讲树哥们怎么讲的(呵呵,纯属调侃,勿怪),竟然让孩子们连入门都没有,不过在这么久我也见怪勿怪了,很多老师都只是空谈,何谈入门,怪不得美国重视启蒙教育。
我坚信:没有不好的学生,只有垃圾的教育。话虽这么说,但是我即便讲得再好也没有多少人会感激我,没有利益关系,算了,社会就这样……
二.理论准备
说之前,我想再说一下,树图等只是一种逻辑表示,存在于脑海里,关键要靠存储结构以及节点间的相互联系体现出来,所以我们常说算法和数据结构,课件算法离不开数据结构的支持,否则就是无本之木、无源之水,兔子的尾巴长不了。
好啦,权当放松下心情,咱切入正题吧。
MST的概念相信大家都知道,不过并查集这种数据结构或许有些读者就有些模糊了,咱先说说并查集。
并查集是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。常常在使用中以森林来表示。集就是让每个元素构成一个单元素的集合,也就是按一定顺序将属于同一组的元素所在的集合合并。
实现一般有如下三个操作:
初始化:把每个点所在集合初始化为其自身,通常来说,这个步骤在每次使用该数据结构时只需要执行一次,无论何种实现方式,时间复杂度均为O(N)。
查找:查找元素所在的集合,即根节点。
合并:将两个元素所在的集合合并为一个集合。通常来说,合并之前,应先判断两个元素是否属于同一集合,这可用上面的“查找”操作实现。
例子:比如亲戚关系,食物链等,目测NOI上挺多这样的题目。
若某个家族人员过于庞大,要判断两个是否是亲戚,确实还很不容易,给出某个亲戚关系图,求任意给出的两个人是否具有亲戚关系。 规定:x和y是亲戚,y和z是亲戚,那么x和z也是亲戚。如果x,y是亲戚,那么x的亲戚都是y的亲戚,y的亲戚也都是x的亲戚。
有点类似传递关系。本题的输入数据量很大,这使得我们的程序会在输入中花去不少时间。如果你用Pascal写程序,可以用库函数SetTextBuf为输入文件设置缓冲区,这可以使输入过程加快不少。如果你是用C语言的话,就不必为此操心了,系统会自动分配缓冲区。
#include<iostream>#include<cstring>#include<cstdio>#include<cstdlib>using namespace std;int father[50002],a,b,m,n,p;int find(int x){if (father[x]!=x) father[x]=find(father[x]);return father[x];}int main(){scanf("%d%d%d",&n,&m,&p);for (int i=1;i<=n;i++) father[i]=i;for (int i=1;i<=m;i++){scanf("%d%d",&a,&b);a=find(a),b=find(b);father[a]=b;}for(int i=1;i<=p;i++){scanf("%d%d",&a,&b);a=find(a);b=find(b);if(a==b)printf("Yes");else printf("No");}return 0;}三.并查集
引入问题:在某个城市里住着n个人,现在给定关于 n个人的m条信息(即某2个人认识),假设所有认识的人一定属于同一个单位,请计算该城市最多有多少单位?
我对最多的理解:若是某两人不在给出的信息里,那么他们不认识,属于两个不同单位。
实现方法一:
n用编号最小的元素标记所在集合;n定义一个数组 set[1..n] ,其中set[i] 表示元素i 所在的集合;
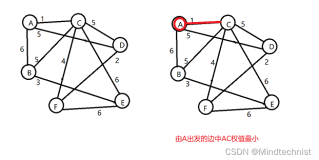
效率分析,注意下图中Merge函数的ab是根节点。
对于“合并操作”,必须搜索全部元素!试试树结构
实现方法二:
每个集合用一棵“有根树”表示,定义数组 set[1..n],set[i] = i , 则i表示本集合,并是集合对应树的根,set[i] = j, j<>i, 则 j 是 i 的父节点.
效率分析
性能有本质改进?n如何避免最坏情况?
注意:原文是在merge函数里先判断树的深度,再把小树挂到大树上,不过本人认为这个优化完全没必要,多写了函数不说,性能也不见得会提高,况且我见的题也不算少,从没见过谁在并查集里搞这个,来吧直接路径压缩(有人也叫秩压缩),上文采用的是递归,为便于理解,咱使用非递归。
find3(x){r = x;while (set[r] <> r) //循环结束,则找到根节点r = set[r];i = x;while (i <> r) //本循环修改查找路径中所有节点{j = set[i];set[i] = r;i = j;}}对了,课上有人问我“<>”这个符号啥意思,如果有读者也不知道啥意思,百度去吧,真心不想在着说了。




注意:路径压缩是在查找的时候压缩的,每次只会压缩一个分支,但这之后,再次查找就只需要O(1)时间了,时间节省就在这。
------------------------------------------------------------------------------------------------------------------------------------
以HDU1232为例,直接去AC吧
题目描述:某省调查城镇交通状况,得到现有城镇道路统计表,表中列出了每条道路直接连通的城镇。省政府“畅通工程”的目标是使全省任何两个城镇间都可以实现交通(但不一定有直接的道路相连,只要互相间接通过道路可达即可)。问最少还需要建设多少条道路?
最赤裸裸的并查集,无话可说~
//课上给大一写的,1s#include <stdio.h>#include <stdlib.h>const int maxn = 1005;int a[maxn];int find(int elem){int r = elem;while(r!=a[r])r = a[r];//路径压缩int x = elem;int j;while(x!=r){j = a[x];a[x] = r;x = j;}return r;}void merge(int u, int v){int i,j;int fx = find(u);int fy = find(v);if(fx!=fy)a[fx] = fy;}int main(){int i,j,k;int n,m;int u,v;while(scanf("%d",&n)&&n){scanf("%d",&m);//0号单元不用for(i=0; i<=n; i++)a[i] = i;for(i=1; i<=m; i++){scanf("%d",&u);scanf("%d",&v);merge(u,v);}int cnt = 0;//不能从0开始,因为a[0] = 0 ,这样就会多统计一个集合for(i=1; i<=n; i++){if(a[i]==i)cnt++;}printf("%d\n",cnt-1);}system("pause");return 0;}--------------------------------------------------------------------------------------------------------------------------------------------------
再看一道HDU1272。
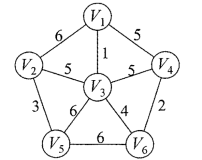
下面的例子,前两个是符合条件的,但是最后一个却有两种方法从5到达8。
第一种方法:根据MST性质(您能猜得到么),统计顶点数,边数就是输入的个数,只要“边数=顶点数-1”就ok啦。
一年前写的代码,有些丑陋,不过不影响阅读哈。
//n对点,则必有n条线段, 把所有的起点和终点保存在一维数组中,先排序,计算不重复的点有几个,便是组成的图形有几个点//也可以使用map#include <iostream>#include <map>#include <cstring>using namespace std;int main(){int i,j,k,T;int from, to;map <int ,int > mymap;int cnt = 0;while(cin>>from>>to,~from||~to){cnt = 0;//几组数据while(1){if(!(from||to))break;cnt++;if(mymap.count(from)==0)mymap[from] = to;if(mymap.count(to)==0)mymap[to] = from;cin>>from>>to;}if(mymap.size()==0){puts("Yes");continue;}if(mymap.size()==(cnt+1))puts("Yes");elseputs("No");mymap.clear();}return 0;}方法二:并查集实现
当你输入的x,y的根节点fx,fy相同时,说明已经可达,再连接就是有多余一条路径了(环),所以先判断是否同根就ok了。(迷宫应该只有一个集合,多余一个就说明不连通,哈哈,说明并查集也可以判断是否联通啊)。
具体实现留给读者。

四.最小生成树
咱们都知道经典算法就是prim和kruskal算法,二者都是贪心算法。
先看克鲁斯卡尔算法(并查集实现)。
为什么kruskal可以用并查集实现?我的理解是这个算法执行的过程就是按照规定一个个连通支合并的过程,使最后只剩一个连通支。
#include <stdio.h>#include <stdlib.h>#include <algorithm>using namespace std;const int N = 150;int m,n,u[N],v[N],w[N],p[N],r[N];int cmp(const int i,const int j){return w[i] > w[j];}int find(int x){return p[x]==x?x:p[x]=find(p[x]);}int kruskal(){int cnt=0,x,y,i,ans=0;//n是点数,m是边数,汝佳那本书上是如此//并查集初始化for(i=0;i<n;i++)p[i]=i;//边编号for(i=0;i<m;i++)r[i]=i;sort(r,r+m,cmp);for(i=0;i<m;i++){//取出未加入的边权最小的边的编号int e=r[i];x=find(u[e]);y=find(v[e]);if(x!=y){ans += w[e];p[x]=y;cnt++;}}//找不到最小生成树if(cnt<n-1)ans=0;return ans;}int main(){int i,ans;while(scanf("%d%d",&m,&n)!=EOF&&m){for(i=0;i<m;i++){scanf("%d%d%d",&u[i],&v[i],&w[i]);}ans=kruskal();if(ans)printf("%d\n",ans);else //说明不存在最小生成树puts("存在最小生成树!");}return 0;}再看普利姆算法。
普里姆算法的基本思想,从连通网N={V,E}中的某一顶点U0出发,选择与它关联的具有最小权值的边(U0,v),将其顶点加入到生成树的顶点集合U中。以后每一步从一个顶点在U中,而另一个顶点不在U中的各条边中选择权值最小的边(u,v),把它的顶点加入到集合U中。如此继续下去,直到网中的所有顶点都加入到生成树顶点集合U中为止。
以NYOJ38为例,下面这个是以前写的,没按数据结构课本上来。
http://www.cnblogs.com/hxsyl/archive/2012/05/19/2508896.html
我又实现了下,按严蔚敏课本上来实现。
#include<stdio.h>#include<string.h>using namespace std;int map[505][505];int v, e;int prime(){bool vis[505];int dist[505];int i,j,sum=0;for(i=1;i<=v;i++){vis[i]=0;//先假设编号为1的点加入MSTdist[i]=map[1][i];}vis[1]=1;for(i=1;i<v;i++){int k,min=0x3f3f3f3f;for(j=1;j<=v;j++){if(!vis[j]&&dist[j]<min){min=dist[j];k=j;}}/*在这也统计下加入了几天边,判断是否构成MST*/sum+=dist[k];vis[k]=1;//下面更新已加入最小生成树的点离其它点的最短距离for(j=1;j<=v;j++){if(!vis[j]&&dist[j]>map[k][j])dist[j]=map[k][j];}}return sum;}int main(){int n;int i;int waibu;scanf("%d", &n);while(n--){memset(map, 0, sizeof(map));scanf("%d %d", &v, &e);int a, b, c;for(i = 0; i< e; i++){scanf("%d %d %d", &a, &b, &c);map[a][b] = c;map[b][a] = c;}int min = 0x3f3f3f3f;for(i = 0; i< v; i++){scanf("%d", &waibu);if(min > waibu)min = waibu;}printf("%d\n", prime() + min);}return 0;}对了,今天查资料时看了什么破圈法实现普利姆算法,思路是每次找到任意一个圈,去掉权值最大的边,一直找直到没有圈。他的那个实现代码太难看了,可以说恶心(代码极度不规则),也没看懂,有了解的给指点下。
虽然算法实现了,不过对于算法的正确性本人确实不怎么了解,不知道如何证明,懂得指点下。
五.结束语
本来想把MST的扩展应用也加上呢,后来发现加上就太长了,影响阅读体验,在此本人郑重声明,若是您感觉意犹未尽,就请关注本人的下一篇博文,定然不让您失望,若是您感觉阅读本文后有所收获,就请您动动手指头,点下推荐,您的支持是对博主最大的鼓励;不过若是您发现不当之处,本人深感抱歉,希望没有误导到您,还望指正出来,本人会发专文感谢大家的支持与鼓励,谢谢……
我在这,你在哪?
本文参考了杭电的课件和百度上某些佚名作者的资料,在此表示感谢。