最近自从把备库纳入zabbix的监控体系之后,有一个备库总是在午夜发来一条报警邮件。内容大体如下:
adb0_s1@10.127.xx.xx_报警
------------------------------------
报警内容: CPU utilization is too high
------------------------------------
报警级别: PROBLEM
------------------------------------
监控项目: CPU idle time:53.8 %
------------------------------------
报警时间:2015.09.29-01:50:27
单纯从报警信息来看,这是一个备库中发出的报警,所以很自然联想到是有大量的批量查询任务在运行。
每次看到都直接忽略,看着最近的报警信息处理,多多少少都能发现点什么,就决定好好挖掘一下,看看有什么能改进的,目标就是不改动报警阀值,能够把负载控制在合理范围之内。
根据报警的时间点来抓取ash报告,前后浮动几分钟,这次没有连错就是备库,但是没有发现任何的信息,连top event都没有。
查看crontab,也没有发现任何相关的任务在运行。
自己都有点怀疑是不是CPU使用瞬间抖动造成的,是否为误报。貌似数据库层面没有很明显的发现,至少通过前后的几分钟时间来看,没有发现任何active session信息。我们来看看系统级的CPU使用情况,是否存在着明显的CPU过载现象。
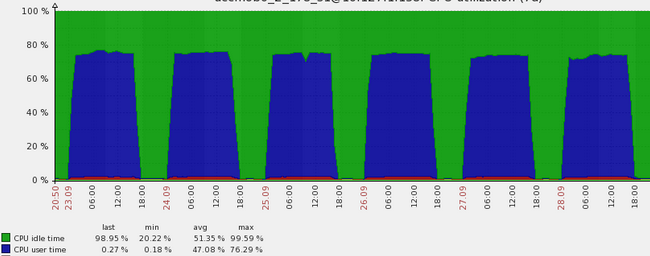
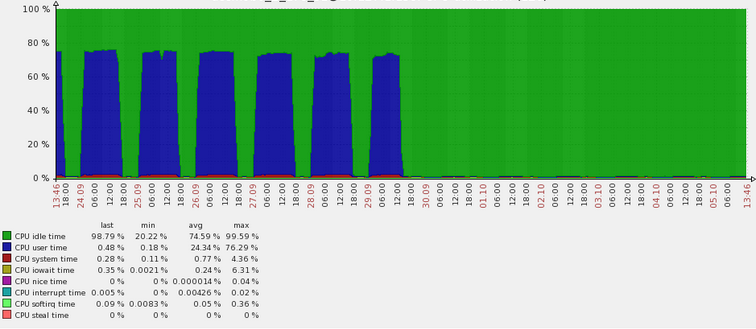
蓝色部分是CPU使用的比例,在每天的凌晨到晚上6点都在满负荷运行,然后会有一些短暂的空闲期。每天都是如此。
所以CPU的过载问题是很明显而且有规律的。
第二天早上查看的时候,发现这个时间段还是在问题时间段之内,使用sar命令也确实能够看到CPU的使用率情况(最后一列)
01:20:01 AM all 0.24 0.00 0.16 0.11 0.00 99.48
01:30:01 AM all 5.22 0.00 0.50 0.58 0.00 93.70
01:40:01 AM all 32.27 0.00 1.11 0.07 0.00 66.54
01:50:01 AM all 51.26 0.00 1.39 0.05 0.00 47.29
02:00:01 AM all 56.99 0.00 1.49 0.05 0.00 41.46
02:10:01 AM all 60.05 0.00 1.61 0.05 0.00 38.30
02:20:01 AM all 70.70 0.00 1.90 0.05 0.00 27.35
02:30:01 AM all 70.61 0.00 1.84 0.04 0.00 27.51
这个时候还是使用top命令来看,能够抓取到目前正在占用大量CPU资源的几个进程都是oracle用户进程。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1113 oracle 19 0 16.0g 9.1g 9.1g R 96.3 29.0 299:56.69 oracleadb0 (LOCAL=NO)
980 oracle 17 0 16.0g 9.1g 9.1g S 91.6 29.0 303:02.33 oracleadb0 (LOCAL=NO)
599 oracle 16 0 16.0g 9.2g 9.2g S 89.0 29.2 321:21.08 oracleadb0 (LOCAL=NO)
1313 oracle 16 0 16.0g 9.1g 9.1g R 88.0 29.0 290:09.17 oracleadb0 (LOCAL=NO)
982 oracle 15 0 16.0g 9.1g 9.1g R 86.7 29.0 302:18.63 oracleacdb0 (LOCAL=NO)
884 oracle 17 0 16.0g 9.1g 9.1g R 85.7 29.0 308:39.81 oracleadb0 (LOCAL=NO)
拿出第一个进程分析,看看这个进程在干嘛。
SID SERIAL# USERNAME OSUSER MACHINE PROCESS TERMINAL TYPE LOGIN_TIME
5270 687 APP_USER_TEST WEB_XXX_xxx 1234 USER 2015-09-29 01:23:43
.
SQL_ID SQL_TEXT
------------------------------ ------------------------------------------------------------
gx34ap7fbwuvx select count(*) from user_test35 where old_id=:1
原来这是一个简单的查询语句,确有大量的CPU消耗,相必是走了全表扫描了。
查看执行计划,发现还真是。
Plan hash value: 1393919968
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 1543 (100)| |
| 1 | SORT AGGREGATE | | 1 | 7 | | |
|* 2 | TABLE ACCESS FULL| USER_TEST | 1 | 7 | 1543 (1)| 00:00:19 |
--------------------------------------------------------------------------------------
这个语句USER_TEST35其实是指向另外一个schema下的USER_TEST表。
查看索引情况,发现确实没有索引列在OLD_ID上面。至于这个部分,我们现在可以得到一个初步的结论就是表USER_TEST中缺少了列OLD_ID相关的索引,结果导致了全表扫描。
问题到此似乎也是合乎情理了,不过继续抓取了另外几个问题sql,发现表名都是一致的,但是属于不同的用户,这个时候因为是备库,索性就抓取了一个8小时的ash报告。
这个时候得到了一个相关的列表。
SQL ID Planhash of Executions % Activity
----------------------- -------------------- -------------------- --------------
Event % Event Top Row Source % RwSrc
------------------------------ ------- --------------------------------- -------
27bt3qxbjzmzn 1393919968 12153 8.47
CPU + Wait for CPU 8.45 TABLE ACCESS - FULL 8.44
select count(*) from user_test02 where old_id=:1
3qcg54j5kx190 1393919968 12110 8.44
CPU + Wait for CPU 8.41 TABLE ACCESS - FULL 8.41
select count(*) from user_test24 where old_id=:1
d59kmgha5azmv 1393919968 11767 8.21
CPU + Wait for CPU 8.18 TABLE ACCESS - FULL 8.18
select count(*) from user_test15 where old_id=:1
7ug3juzr5ta3z 1393919968 11750 8.20
CPU + Wait for CPU 8.17 TABLE ACCESS - FULL 8.16
select count(*) from user_test13 where old_id=:1
76jg6df5tvqgp 1393919968 11726 8.18
CPU + Wait for CPU 8.15 TABLE ACCESS - FULL 8.14
select count(*) from user_test22 where old_id=:1
这些操作都是在做一个查询数据条数的操作,其实关联的表名都是同一个。但是归属于不同的schema下。
那么到底有多少呢,是不是碰到一个问题就修复一个,还是抓住本质,根本上解决呢。
其实这些用户基本都是在做一个分库分表的操作,根据不同的规则把数据分布到不同的schema上去,但是表名是同一个。
按照目前的规则,相关的用户就有10多个了,而不是ash报告中抓取到的那几个了。
而查看这些用户下的表数据情况,也基本是均匀的,但是数据量还不够大,百万级。
所以我们可以在这些相关的用户上对于问题表创建索引基于列OLD_ID,
create index AdB00.IDX_USER_TEST_OLDID ON ADB00.USER_TEST(OLD_ID);
create index AdB02.IDX_USER_TEST_OLDID ON ADB02.USER_TEST(OLD_ID);
....
但是在操作之前还是看看是否有其它的相关sql,执行频率怎么样。如果要创建,主库是否有相关的dml操作,主库的负载等等,是否可以online操作,是否需要开并行等等。
所以简单的评估之后,认为还是在主库是可以操作的,就开启了并行,开始创建索引。
创建索引的时间倒不长,然后在备库中去抓取sql的执行计划是否改变。
Plan hash value: 1638289453
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 3 (100)| |
| 1 | SORT AGGREGATE | | 1 | 7 | | |
|* 2 | INDEX RANGE SCAN| IDX_USER_TEST_OLDID | 1 | 7 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
可以看到效果还是很明显的。
通过sar可以看到CPU利用率直线下降。
02:00:01 PM all 70.51 0.00 1.95 0.20 0.00 27.34
02:10:01 PM all 70.40 0.00 2.08 0.25 0.00 27.27
02:20:01 PM all 5.06 0.00 0.62 0.39 0.00 93.92
02:20:01 PM all 5.06 0.00 0.62 0.39 0.00 93.92
问题修复之后,可以看到CPU使用率马上下降了,资源已经提前解放了出来。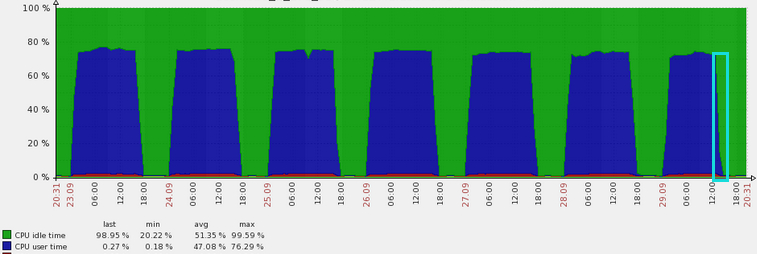
相信之后的几天里,也不会有很明显的CPU使用异常了。
通过这个案例可以看到一个很小的报警还是可能蕴含着一些值得去处理的问题,如果发现了问题,还是需要来看看问题的分析是否全面,从手头拿到的数据来看,是否已经掌握了完整的信息。
如果把这个问题和业务结合起来,还是发现问题还是有一些规律,尽管一些问题sql并没有在报告中体现出来。当然问题需要修复,什么时候修复,怎么修复,怎么来评估,还是需要自己好好琢磨一下。
##附上问题后期的持续跟进,可以看到效果确实是杠杠的。