如果一个大表要抽取数据导出成csv文件,我们有什么策略,如何改进。
一、问题背景
今天开发的同学找到我,他们需要做一个数据统计分析,需要我提供一些支持,把一个统计库中的大表数据导出成文本提供给他们。
这个表有多大呢,数据量有4亿+,而且使用了分库分表的策略,所以看起来这不是一个简单的问题。
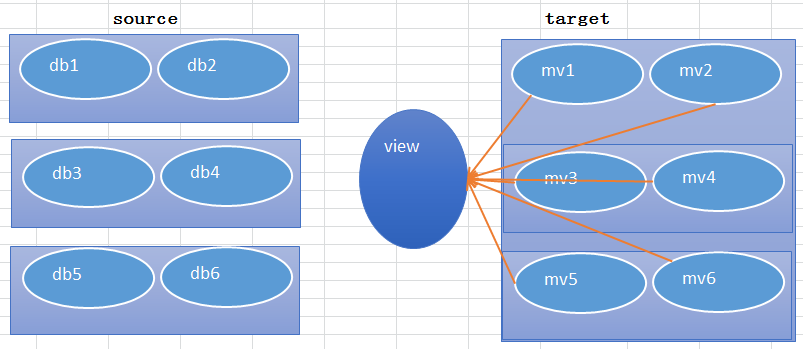
简单来说就是下面的架构方式,在右侧的目标端存在的都是物化视图,存在12个子集,也就意味着有12个物化视图存在。
这里就有两个重要的内容需要说一下:
1)大表如何平均切分,而不单单考虑是否为分区表。
2)如何规范化,标准化的抽取数据。
二、大表如何切分
大表的切分一直以来是数据迁移中的重头戏,我在以前的时间积累中也为此困扰。一个表如果不是分区表,存在1000万的数据,如果我们希望以数据条数为基准进行切分,能否实现。
比如1000万数据的表,100万为单位,那就生成10个csv文件,每个文件包含100万数据。
当然这个工作是可以做成的,实现的基础就是ROWID切分。直接上脚本。
#### $1 dba conn details
#### $2 table owner
#### $3 table_name
#### $4 subobject_name
#### $5 parallel_no
function normal_split
{
sqlplus -s $1 <<EOF
set linesize 200
set pages 0
set feedback off
spool rowid_range_$3_x.lst
select rownum || ', ' ||' rowid between '||
chr(39)||dbms_rowid.rowid_create( 1, DOI, lo_fno, lo_block, 0 ) ||chr(39)|| ' and ' ||
chr(39)||dbms_rowid.rowid_create( 1, DOI, hi_fno, hi_block, 1000000 )||chr(39) data
from (
SELECT DISTINCT DOI, grp,
first_value(relative_fno) over (partition BY DOI,grp order by relative_fno, block_id rows BETWEEN unbounded preceding AND unbounded following) lo_fno,
first_value(block_id ) over (partition BY DOI,grp order by relative_fno, block_id rows BETWEEN unbounded preceding AND unbounded following) lo_block,
last_value(relative_fno) over (partition BY DOI,grp order by relative_fno, block_id rows BETWEEN unbounded preceding AND unbounded following) hi_fno,
last_value(block_id+blocks-1) over (partition BY DOI,grp order by relative_fno, block_id rows BETWEEN unbounded preceding AND unbounded following) hi_block,
SUM(blocks) over (partition BY DOI,grp) sum_blocks,SUBOBJECT_NAME
FROM(
SELECT obj.OBJECT_ID,
obj.SUBOBJECT_NAME,
obj.DATA_OBJECT_ID as DOI,
ext.relative_fno,
ext.block_id,
( SUM(blocks) over () ) SUM,
(SUM(blocks) over (ORDER BY DATA_OBJECT_ID,relative_fno, block_id)-0.01 ) sum_fno ,
TRUNC( (SUM(blocks) over (ORDER BY DATA_OBJECT_ID,relative_fno, block_id)-0.01) / (SUM(blocks) over ()/ $5 ) ) grp,
ext.blocks
FROM dba_extents ext, dba_objects obj
WHERE ext.segment_name = UPPER('$3')
AND ext.owner = UPPER('$2')
AND obj.owner = ext.owner
AND obj.object_name = ext.segment_name
AND obj.DATA_OBJECT_ID IS NOT NULL
ORDER BY DATA_OBJECT_ID, relative_fno, block_id
) order by DOI,grp
);
spool off;
EOF
}
sub_partition_name=$4
if [[ $sub_partition_name = 'x' ]]
then
normal_split $1 $2 $3 x $5
fi 说实话,这段脚本值得你好好体会一番,而不是看过就看过了,很多产品工具的核心就是一些很细小的东西,点到为止。
脚本的运行结果如下,我们期望是切分为20份。输出结果会直接打印出边界的ROWID,运行结果如下:
$ksh gen_rowid.sh test_dba/xxx accstat ACC00_USER_SOCIETY_INFO x 20
1, rowid between 'AAFO0gAIFAAPhoJAAA' and 'AAFO0gAMhAAPUj/EJA'
2, rowid between 'AAFO0gAMhAAPUkAAAA' and 'AAFO0gAMhAAPYj/EJA'
3, rowid between 'AAFO0gAMhAAPYkAAAA' and 'AAFO0gANvAAD21/EJA'
4, rowid between 'AAFO0gANvAAD22AAAA' and 'AAFO0gANvAAD5h/EJA'
 有了第一步的辅助,那么第二步就顺手推舟了,不过还得再加把劲儿。
有了第一步的辅助,那么第二步就顺手推舟了,不过还得再加把劲儿。
三、如何规范化导出海量数据?
这个部分可能存在一些争议,怎样算规范化,怎么样的算海量数据,我们先不拘束于这些,我们先说说导出数据为csv有哪几种方式,除了图形工具外,Oracle命令行的方式导出有SQL, PL/SQL,其它编程语言的方式。
SQL导出的要点就是设置分隔符,假设分隔符为逗号,SQL*Plus中设置属性colsep " ," (以逗号分隔),这种方式的输出实在不敢恭维,还有一种就是手工设置风格符,比如通过chr(44)的方式来设置。毫无疑问,还是太繁琐。
PL/SQL导出的方式也有标准版,高配版两种方式,标准版我留使用utl_file来完成,通过设置目录的方式。
比如我们创建了一个目录为TMP_DATA,则可以使用如下的方式来完成。
create directory TMP_DATA as '/U01/app/tmp_data';
grant read,write on directory tmp_data to test_dba;
使用如下的脚本来完成基本的数据抽取,生成文件为output.txt
这里我们就使用ROWID的方式来抽取数据。
declare
v_filehandle UTL_FILE.FILE_TYPE;
begin
v_filehandle:=utl_file.fopen('TMP_DATA','output.txt','w');
UTL_FILE.PUTF (v_filehandle,'---export data from table ACC00_USER_SOCIETY_INFO:', SYSTIMESTAMP);
UTL_FILE.NEW_LINE (v_filehandle);
for i in(select
*
FROM accstat.ACC00_USER_SOCIETY_INFO where rowid between 'AAFO0gAIFAAPhoJAAA' and 'AAFO0gAMhAAPUj/EJA' ) loop
UTL_FILE.PUTF (v_filehandle, '%s,%s\n',i.uin,i.age);
end loop;
UTL_FILE.FCLOSE (v_filehandle);
end;
/ 这种方式相对来说可控一些,但是一个比较繁琐的部分就是字段都得一一映射,这可不大好。
有没有更好的方式呢,有的,我们得想起了Thomas Kyte大师的脚本了,之前他提供过,创建一个FUNCTION即可。
CREATE function dump_csv( p_query in varchar2,
p_separator in varchar2
default ',',
p_dir in varchar2 ,
p_filename in varchar2 )
return number
AUTHID CURRENT_USER
is
l_output utl_file.file_type;
l_theCursor integer default dbms_sql.open_cursor;
l_columnValue varchar2(2000);
l_status integer;
l_colCnt number default 0;
l_separator varchar2(10) default '';
l_cnt number default 0;
begin
l_output := utl_file.fopen( p_dir, p_filename, 'w' );
dbms_sql.parse( l_theCursor, p_query, dbms_sql.native );
for i in 1 .. 255 loop
begin
dbms_sql.define_column( l_theCursor, i,
l_columnValue, 2000 );
l_colCnt := i;
exception
when others then
if ( sqlcode = -1007 ) then exit;
else
raise;
end if;
end;
end loop;
dbms_sql.define_column( l_theCursor, 1, l_columnValue,
2000 );
l_status := dbms_sql.execute(l_theCursor);
loop
exit when ( dbms_sql.fetch_rows(l_theCursor) <= 0 );
l_separator := '';
for i in 1 .. l_colCnt loop
dbms_sql.column_value( l_theCursor, i,
l_columnValue );
utl_file.put( l_output, l_separator ||
l_columnValue );
l_separator := p_separator;
end loop;
utl_file.new_line( l_output );
l_cnt := l_cnt+1;
end loop;
dbms_sql.close_cursor(l_theCursor);
utl_file.fclose( l_output );
return l_cnt;
end dump_csv;
/如果需要导出一个表里的数据,这样使用就可以了,还是根据ROWID来切分数据。
select dump_csv('select * from accstat.ACC00_USER_SOCIETY_INFO where rowid between ''AAFO0gAIFAAPhoJAAA'' and ''AAFO0gAMhAAPUj/EJA'' and rownum<1000',',','TMP_DATA','data.csv') from dual;
;当然要点就是这些,我们可以写几个SQL即可生成数据。
整个过程其实涉及到一些技术细节,还是需要大家多加揣摩,掌握好了之后,在数据迁移的场景中就能够大展拳脚。
我也给自己的公众号设置了一个简单的封面,看起来还行吧。纯手工PS抠图补字完成。