联动贴:http://blog.itpub.net/29510932/viewspace-1777673/
left join on之中出现的一些有偏差的理解, 也是由于对SQL逻辑查询顺序的不了解导致的
-------------------------------------------------------------------------------------------------正文---------------------------------------------------------------------------------------------------------------
问题出现于生产环境,为了方便表述,在测试环境构造了类似的场景,同时部分验证和测试例子隐去了一些生产环境的信息
有开发人员对生产环境中出现的一些现象提出了疑问,然后仔细查阅资料,特意明确了这一个知识点,顺便又挖了一个坑......_(:з」∠)_
------------------------------------------------------------------------------------------------知识点--------------------------------------------------------------------------------------------------------------
SQL伪代码
SQL伪代码的执行顺序
大前提:在MySQL中,忽略ICP(Index condition Pushdown),忽略数据库对order by,group by, limit等语法的优化
需要注意的是,SQL语句在执行各个步骤之后,都会把结果临时存储起来,姑且记为TM*
1.取出left_table 和right_table , 然后对两个表的数据做笛卡尔积,得到临时结果TM1;
2. 根据ON的<join_conditionjoin_condition过滤,留下符合条件的结果,得到临时结果TM2;
3.检查join_type,如果是left或者right,那么则会把left_table<left_table或者<right_tableright_table的行数补齐,得到临时结果TM3.1;
(3.1)如果存在更多的表要进行join,则读取下一张需要join的表的数据,重复1-3的步骤,直到得到最终的临时结果TM3;
4.对TM3的数据,依据where_condition进行过滤,得到临时结果TM4;
5.对TM4的数据,依据group_by_list<group_by_list进行分组操作,得到临时结果TM5;
6.对TM5的数据,进行CUBE或者ROLLUP操作,得到临时结果TM6;
7.对TM6的数据,依据having_condition<having_condition进行过滤,得到临时结果TM7;
8.对TM7的数据,执行投影操作(和聚集函数计算?),得到临时结果TM8;
9.对TM8的数据,执行去重操作,得到临时结果TM9;
10.对TM9的数据,执行排序操作,得到临时结果TM10;
11.对TM10的数据,执行排序操作,得到临时结果TM11;
-------------------------------------------------------------------------------------------联动帖的情况-----------------------------------------------------------------------------------------------------------
那么回顾联动帖里面的问题,在left join on的条件中,除了常见的列关联,还存在col>1之类的选择条件,把整个语句代入到上面的执行逻辑里面,
可以发现,在第2步里面确实是把不符合col>1的列过滤掉了,但是在第3步,依据left join的特性,又把左表中的列补全了,且不符合条件的全部使用null进行填充,
所以才会出现实验中的结果;
同样的,换成inner join以后,得到的结果也完全可以解释清楚,因此联动帖中的现象可以根据这个处理逻辑来理解和判断~
-------------------------------------------------------------------------------------------知识点的应用------------------------------------------------------------------------------------------------------------
背景:分页查询
于生产环境下截图,SQL语句稍加改动,截图隐去部分信息
问题:根据SQL逻辑查询顺序的描述来看,分页查询的两个语句应该消耗差不多的时间,
实际上分页查询的count(*)比分页查询查内容的时候,要慢了800多倍;
问题语句的复现:
完全按照SQL逻辑执行顺序来重新分析这两个语句,这两个语句确实是差不太多的,都会执行步骤 1-4和6,下面一个语句还会在最后再执行一个limit,选出从0开始的100行数据;
那么实际看看执行结果:
count(*)

分页查询

去掉limit的分页查询()

其实有对比就很明显了, 这肯定是 limit 0,100 导致这个时间上的差距 ,那么是MySQL做了什么额外的操作使得limit的速度变得那么快了?
看看explain:
分页查询
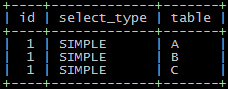
去掉limit的分页查询
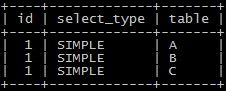
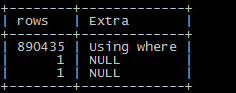
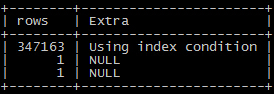
单纯在这个 分页查询里面,多出来了一个index condition的信息,这是5.6新加的特性 ICP(Index condition Pushdown)(又挖一个坑..._(:з」∠)_...),
在这个特性的帮助下,在步骤1就会减少读取进来的数据量(rows也发生了变化 ),所以极大的降低了分页查询的执行时间;
去掉limit之后,count(*)和实际查询的时间虽然还有差距, 不过也是在同一个级别上了,这里面应该还是有一些MySQL自己做的优化处理在里面,这其中的东西,就不太了解了。
-------------------------------------------------------------------------------------------完结的分割线-----------------------------------------------------------------------------------------------------------
PS:实际上在这个过程中,还是遇到了一些其他的“奇怪”的现象,继续摸索ing;每一个问题的背后,知识点经常是一个扣着一个,学无止境_(:з」∠)_...
</having_condition<></group_by_list<></right_table<></left_table<></join_condition<>
left join on之中出现的一些有偏差的理解, 也是由于对SQL逻辑查询顺序的不了解导致的
-------------------------------------------------------------------------------------------------正文---------------------------------------------------------------------------------------------------------------
问题出现于生产环境,为了方便表述,在测试环境构造了类似的场景,同时部分验证和测试例子隐去了一些生产环境的信息
有开发人员对生产环境中出现的一些现象提出了疑问,然后仔细查阅资料,特意明确了这一个知识点,顺便又挖了一个坑......_(:з」∠)_
------------------------------------------------------------------------------------------------知识点--------------------------------------------------------------------------------------------------------------
SQL伪代码
点击(此处)折叠或打开
- SELECT DISTINCT <select_list>
- FROM <left_table>
- <join_type> JOIN <right_table>
- ON <join_condition>
- WHERE <where_condition>
- GROUP BY <group_by_list>
- HAVING <having_condition>
- ORDER BY <order_by_condition>
- LIMIT <limit_number>
SQL伪代码的执行顺序
点击(此处)折叠或打开
- (8) SELECT (9) DISTINCT <select_list>
- (1) FROM <left_table>
- (3) <join_type> JOIN <right_table>
- (2) ON <join_condition>
- (4) WHERE <where_condition>
- (5) GROUP BY <group_by_list>
- (6) WITH {CUBE | ROLLUP}
- (7) HAVING <having_condition>
- (10) ORDER BY <order_by_list>
- (11) LIMIT <limit_number>
大前提:在MySQL中,忽略ICP(Index condition Pushdown),忽略数据库对order by,group by, limit等语法的优化
需要注意的是,SQL语句在执行各个步骤之后,都会把结果临时存储起来,姑且记为TM*
1.取出left_table 和right_table , 然后对两个表的数据做笛卡尔积,得到临时结果TM1;
2. 根据ON的<join_conditionjoin_condition过滤,留下符合条件的结果,得到临时结果TM2;
3.检查join_type,如果是left或者right,那么则会把left_table<left_table或者<right_tableright_table的行数补齐,得到临时结果TM3.1;
(3.1)如果存在更多的表要进行join,则读取下一张需要join的表的数据,重复1-3的步骤,直到得到最终的临时结果TM3;
4.对TM3的数据,依据where_condition进行过滤,得到临时结果TM4;
5.对TM4的数据,依据group_by_list<group_by_list进行分组操作,得到临时结果TM5;
6.对TM5的数据,进行CUBE或者ROLLUP操作,得到临时结果TM6;
7.对TM6的数据,依据having_condition<having_condition进行过滤,得到临时结果TM7;
8.对TM7的数据,执行投影操作(和聚集函数计算?),得到临时结果TM8;
9.对TM8的数据,执行去重操作,得到临时结果TM9;
10.对TM9的数据,执行排序操作,得到临时结果TM10;
11.对TM10的数据,执行排序操作,得到临时结果TM11;
-------------------------------------------------------------------------------------------联动帖的情况-----------------------------------------------------------------------------------------------------------
那么回顾联动帖里面的问题,在left join on的条件中,除了常见的列关联,还存在col>1之类的选择条件,把整个语句代入到上面的执行逻辑里面,
可以发现,在第2步里面确实是把不符合col>1的列过滤掉了,但是在第3步,依据left join的特性,又把左表中的列补全了,且不符合条件的全部使用null进行填充,
所以才会出现实验中的结果;
同样的,换成inner join以后,得到的结果也完全可以解释清楚,因此联动帖中的现象可以根据这个处理逻辑来理解和判断~
-------------------------------------------------------------------------------------------知识点的应用------------------------------------------------------------------------------------------------------------
背景:分页查询
于生产环境下截图,SQL语句稍加改动,截图隐去部分信息
问题:根据SQL逻辑查询顺序的描述来看,分页查询的两个语句应该消耗差不多的时间,
实际上分页查询的count(*)比分页查询查内容的时候,要慢了800多倍;
问题语句的复现:
点击(此处)折叠或打开
- select count(*)
- from A
- left B on A.order_id= B.order_id
- left C on A.apply_id= C.apply_id
- WHERE
- a.`shop_id` IN (3 1,2,3,4,5,6,7,8,9,10)
- and a.`create_time` >= '2015-09-06 00:00:00'
- ------------------------------------------------------------
- select A.col1, B.col1, C.col1
- from A
- left B on A.col1= B.col1
- left C on A.col1= C.col1
- WHERE
- a.`shop_id` IN (1,2,3,4,5,6,7,8,9,10)
- and a.`create_time` >= '2015-09-06 00:00:00'
- limit 0,100
完全按照SQL逻辑执行顺序来重新分析这两个语句,这两个语句确实是差不太多的,都会执行步骤 1-4和6,下面一个语句还会在最后再执行一个limit,选出从0开始的100行数据;
那么实际看看执行结果:
count(*)
分页查询
去掉limit的分页查询()
其实有对比就很明显了, 这肯定是 limit 0,100 导致这个时间上的差距 ,那么是MySQL做了什么额外的操作使得limit的速度变得那么快了?
看看explain:
分页查询
去掉limit的分页查询
单纯在这个 分页查询里面,多出来了一个index condition的信息,这是5.6新加的特性 ICP(Index condition Pushdown)(又挖一个坑..._(:з」∠)_...),
在这个特性的帮助下,在步骤1就会减少读取进来的数据量(rows也发生了变化 ),所以极大的降低了分页查询的执行时间;
去掉limit之后,count(*)和实际查询的时间虽然还有差距, 不过也是在同一个级别上了,这里面应该还是有一些MySQL自己做的优化处理在里面,这其中的东西,就不太了解了。
-------------------------------------------------------------------------------------------完结的分割线-----------------------------------------------------------------------------------------------------------
PS:实际上在这个过程中,还是遇到了一些其他的“奇怪”的现象,继续摸索ing;每一个问题的背后,知识点经常是一个扣着一个,学无止境_(:з」∠)_...
</having_condition<></group_by_list<></right_table<></left_table<></join_condition<>

