整理自官方文档 Oracle database 11g R2 《concepts》
 、
、


001 概要
本部分说明了数据库如何处理SQL语句。具体而言,本部分说明了数据库
处理创建对象的DDL语句、修改数据的DML语句、和检索数据的查询语句
等的处理方式。
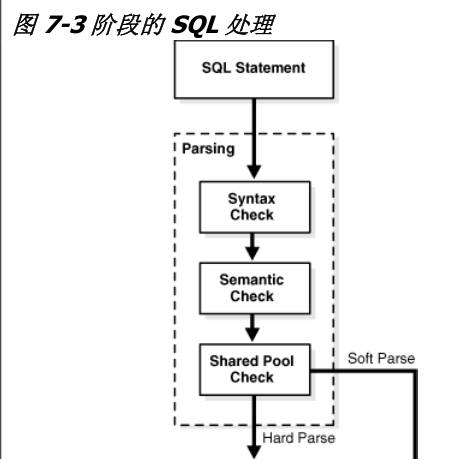
002 SQL处理的阶段
图7-3显示了SQL处理的一般阶段:
解析、优化、产生行源、和执行。
数据库可能会忽略某些步骤,这取决于具体的语句。
、
003 SQL解析
如图7-3 ,SQL处理的第一阶段是解析。这一阶段涉及将SQL语句的各个
片断分离到一个可由其他例程处理的数据结构。数据库会在应用程序的指示
下,对一个语句进行解析,这意味着只有应用程序可以减少解析数目,而不是数据库本身。
当应用程序发出SQL语句时,该应用程序向数据库发出一个解析调用,以准备执行该语句。解析调用会打开或创建一个游标,它是一个对特定于会话
的私有SQL区的句柄,其中包含了已分析的SQL语句和其他处理信息。游
标和私有SQL区位于PGA中。
在解析调用期间,数据库会执行以下检查:
? 语法检查
? 语义检查
? 共享池检查
前面的检查
确定在语句执行之前可以发现的错误。一些错误不能通过解析来
捕获。例如,数据库在数据转换过程中可能会遇到死锁或错误,但这仅在语
句执行中才会发生。
3-1 语法检查
Oracle 数据库必须检查
每个 SQL 语句的语法有效性。违反了标准格式的
SQL语法规则的语句无法通过检查。例如,下面的语句会失败,因为FROM
关键字被错误地拼写为FORM :
SQL> SELECT * FORM employees;
SELECT * FORM employees
*
ERROR at line 1:
ORA-00923: FROM keyword not found where expected
3-2 语义检查
语句的语义即是它的含义。因此,语义检查确定
一条语句是否是有意义的,
例如,该语句中的对象和列是否存在。语法正确的语句可能通不过语义检
查,如下例所示, 查询一个不存在的表:
SQL> SELECT * FROM nonexistent_table;
SELECT * FROM nonexistent_table
*
ERROR at line 1:
ORA-00942: table or view does not exist
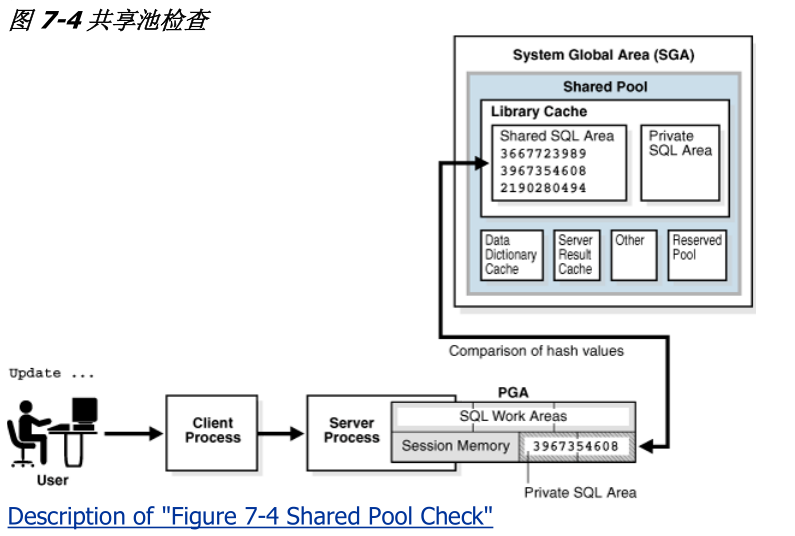
3-3 共享池检查
在解析期间,数据库执行一个共享池检查,以确定
是否可以跳过占用大量资
源的语句处理步骤。为此,数据库使用一种哈希算法为每个SQL语句生成
一个哈希值。语句的哈希值即是在V$SQL.SQL_ID中显示的SQL ID。
当用户提交一个SQL语句时,数据库搜索
共享SQL区,以查看是否已经有
一个现成的已分析的语句具有相同的哈希值。SQL语句的哈希值有别于下
列值:
?
该语句的内存地址
Oracle 数据库使用SQL ID在一个查找表中执行一个"键——值"读取。通过
这种方式,数据库获取该语句的所有可能的内存地址。
?
该语句的执行计划的哈希值
SQL语句在共享池中可以有多个计划。每个计划都具有不同的哈希
值。如果一个相同的SQL ID有多个计划哈希值,则数据库知道针对
该SQL ID有多个计划存在。
基于所提交语句的类型和哈希检查的结果,解析操作分为以下类别:
? 硬解析
如果数据库不能重用现有代码,则它必须生成应用程序代码的一个新
的可执行版本。此操作称为一个硬解析,或库缓存未命中。数据库对
DDL始终执行硬解析。
在硬解析期间,数据库多次访问库缓存和数据字典缓存以检查数据字
典。当数据库访问这些区域时,它在所需对象上使用一个叫做闩锁的
串行化设备,以便它们的定义不会被更改。闩锁
争用会增加语句的执行时间,并降低并发性。
? 软解析
任何不是硬解析的解析都是软解析。如果提交的语句与在共享池中的
某个可重用SQL语句相同,则数据库将重用该现有代码。重用代码
也称为库缓存命中。
软解析要执行的工作量不是完全固定的。例如,配置会话的共享SQL
区有时可以减少软解析中的闩锁用量,使它们“更软”。
一般地,软解析比硬解析更可取,因为数据库可以
跳过优化和行源生
成步骤,而直接进入到执行阶段。
图 7-4 是在专用的服务器体系结构中,一个UPDATE语句的共享池检查的
简化表示。
如果检查到共享库中有一个语句具有相同的哈希值,则数据库执行语义和环
境检查,以确定其含义是否相同。相同的语法是不够的。例如,假设两个不
同用户登录到数据库并发出以下 SQL 语句:
CREATE TABLE my_table ( some_col INTEGER );
SELECT * FROM my_table;
两个用户的 SELECT 语句的语法相同,但这是两个独立的模式对象,名字都
是 my_table。这种语义差异意味着第二个语句不能重用第一个语句的代
码。
即使两个语句在语义上是相同的,某个环境差异也可能使其强制进行硬解
析。在这种情况下,环境是可以影响执行计划生成的全部会话设置,如工作
区大小或优化器设置等。请考虑以下由单个用户执行的一系列 SQL 语句:
ALTER SYSTEM
FLUSH SHARED_POOL;
SELECT * FROM my_table;
ALTER SESSION SET OPTIMIZER_MODE=FIRST_ROWS;
SELECT * FROM my_table;
ALTER SESSION SET SQL_TRACE=TRUE;
SELECT * FROM my_table;
在前面的示例中,相同的SELECT语句在三种不同的优化器环境中执行。因
此,数据库为这些语句创建三个单独的共享SQL区域,并对每个语句强制
进行硬解析。
004 SQL 优化
如"优化器概述"中所述,
查询优化是选择执行SQL语句的最有效手段的过
程。数据库对查询的优化基于对正在访问的实际数据收集的统计信息。优化
器使用行数、数据集大小、和其他因素,来生成各种可能的执行计划,并为
每个计划分配一个成本数值。数据库会使用具有最低成本的计划。
数据库对每个唯一的DML语句必须至少执行一次硬解析,并在解析期间执
行优化。DDL永远不会被优化,除非它包括需要优化的DML组件,如子查
询。
SQL 行源生成
行源生成器是一种软件,它从优化器接收经过优化的执行计划,并生成一个
称为查询计划的迭代计划,可供数据库的其余部分使用。迭代计划是一个二
进制程序,由SQL虚拟机执行,以生成结果集。
查询计划采用组合多个步骤的形式。
每一步返回一个行集。该集合中的行可以在下一步被使用,或在最后一步返回给发出SQL语句的应用程序。
行源是执行计划中的某一步骤所返回的行集,且带有能够迭代该行集的控制
结构
。行源可以是表、视图、或联接操作或分组操作的结果。
行源生成器产生一个行源树,它是一个行源的集合。行源树显示以下信息:
? 由语句所引用的多个有次序的
表
? 在语句中提及的每个表的
访问方法
? 在语句中受联接操作影响的各个表的
联接方法
? 进行的
数据操作,如筛选、 排序、或聚合等
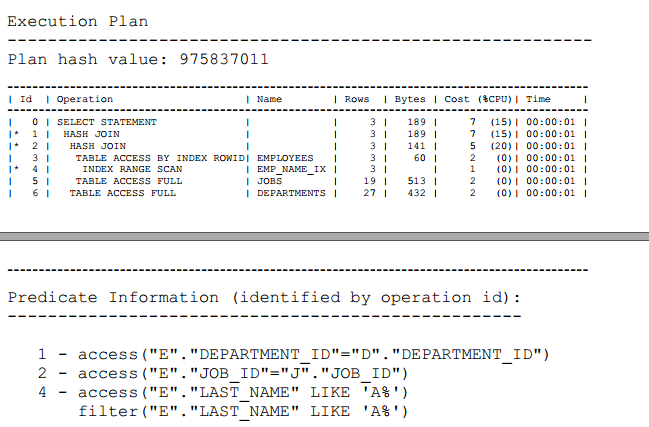
示例 7-6 显示一个 AUTOTRACE 处于启用状态的 SELECT 语句的执行计
划。该语句选择其姓氏以 A 开头的所有雇员的姓氏、 职位名称、和部门名
称。此语句的执行计划是行源生成器的输出(入?)。
示例 7-6
SELECT e.last_name, j.job_title, d.department_name
FROM hr.employees e, hr.departments d, hr.jobs j
WHERE e.department_id = d.department_id
AND e.job_id = j.job_id
AND e.last_name LIKE 'A%' ;
005 SQL 执行
在执行期间,
SQL引擎执行行源生成器所产生的树中的每个行源。这一步
是在DML处理中唯一的强制性步骤。
图7-5是一个执行树,也称为解析树,显示了行源从一步流向另一个步。
通常,执行步骤的顺序与计划中顺序相反,所以你应该从底向上来阅读计
划。在Operation列中的初始空格表示层次结构关系。例如,如果一个
操作的名称前面有两个空格,则此操作是前面有一个空格的操作的子操作。
前面有一个空格的操作是SELECT语句本身的子操作。
图 7-5 行源树
在图 7-5 中,树的每个节点作为一个行源,这意味着每个步骤的执行计划
要么从数据库中检索行,要么接受一个或多个行源中的行作为输入。SQL
引擎这样执行每个行源,如下所示:
?
黑框所示的步骤物理地从数据库中检索对象的数据。这些步骤即是访
问路径,或某种从数据库中检索数据的技术。
o 第 6 步使用全表扫描来从 departments 表中检索所有行。
o 第 5 步使用全表扫描来从 jobs 表中检索所有行。
o 第 4 步顺序扫描 emp_name_ix 索引,查找以字母 A 开头的
每个键,并检索相应的rowid。例
如,与Atkinson对应的rowid是
AAAPzRAAFAAAABSAAe。
o 第 3 步,从 employees 表中检索由第 4 步所返回的 rowids
所在的行。例如,数据库使用 rowid AAAPzRAAFAAAABSAAe
来检索 Atkinson 的行。
?
白框中所示的步骤操作行源。
o 第2步执行一个哈希联接,它从第3步和第5步中接受行
源,将第5步行源中的每一行与第3步中的相应行连接,并
将结果行返回给第1步。
例如,雇员 Atkinson 所在行与职位 Stock Clerk 相关
联。
o 第1步执行另一个哈希连接,从第2步和第6步接受行源,
将第6步行源中的每一行与第2步中的相应行连接,并将结
果返回客户端。
例如,雇员Atkinson所在行与名为 Shipping 的部门相关
联。
在某些执行计划中的步骤是迭代的,而其他一些则是顺序的。示例7-6中
所示的计划是迭代的,因为SQL引擎多次在索引、表、客户端重复这些步
骤。
在执行过程中,如果数据不在内存中,数据库则从磁盘读取数据到内存。为
确保数据的完整性,数据库还取得任何必要的锁和闩锁,并为SQL执行过
程中所做的任何更改记录日志。处理SQL语句的最后一个阶段是关闭游
标。
006
Oracle数据库如何处理DML
大多数DML语句都有一个查询组件。在一个查询中,游标执行后会将查询
结果放入一个称为结果集的行集。
结果集中的行可以每次读取一行或一组。在读取阶段,数据库选择行,如果
该查询要求排序,则将其排序。每次后续读取从结果中检索下一行,直到最
后一行已被读取。
通常,只有直到读取了最后一行,数据库才知道一个查询到底需要检索多少
行数。Oracle数据库检索数据来响应读取调用,因此数据库读取的行越
多,则它执行的工作就越多。对于某些查询,数据库会尽可能快地返回第一
行,而其它一些则是先创建整个结果集之后才返回第一行。
读一致性
通常,查询通过使用数据库读取一致性机制来检索数据。这一机制使用撤消
数据来显示以前版本的数据,保证查询所读取的所有数据块都是单点时间一
致的。
举一个读取一致性的例子,假设一个查询在一次全表扫描中必须读取 100
个数据块。该查询处理前面的10块,而在另一个会话中的DML修改了第
75块。当第一个会话读到第75块时,发现数据已更改,于是就使用撤消
数据来检索旧的、未经修改的版本,并在内存中构造一个第75块的非当前
版本。
数据改变
必须更改数据的DML语句,使用读取一致性机制来检索,只与修改开始时
的搜索条件匹配的数据。然后,这些语句检索数据块,如同他们处于当前状
态,并作出必要的修改。数据库必须执行其他与数据修改有关的操作,如生
成重做和撤消数据。
007 Oracle数据库如何处理DDL
Oracle 数据库对DDL的处理不同于DML。例如,在创建表时,数据库并不
会优化CREATE TABLE语句。相反,数据库只是解析该DDL语句并执行该
命令。
数据库以不同方式处理DDL的原因是,它是一种在数据字典中定义对象的
方式。通常,为执行DDL命令,数据库必须解析和执行许多递归SQL语
句。假设您创建一个表,如下所示:
CREATE TABLE mytable (mycolumn INTEGER);
通常,数据库将运行数十个递归语句来执行前面的语句。递归SQL会执行
以下操作:
? 在执行CREATE TABLE语句之前,发出一个COMMIT命令
? 验证用户权限足以创建表
? 确定表应位于的表空间
? 确保不超过表空间配额
? 确保在模式中没有具有相同的名称的对象
? 将定义表的行插入到数据字典
? 如果DDL语句成功,发出一个COMMIT,或者如果未成功,发出一
个ROLLBACK