Oracle Data Recovery Advisor(DRA) 数据恢复顾问
对DBA而言,数据备份、还原是日常工作的基本功。Oracle发展到今天,自动化、智能化是一个重要的发展方向。数据库可以自动的诊断问题故障,并且解决修复错误,可能离我们并不遥远。
数据备份和还原,在Oracle DBA学习过程中,占到了很大的篇幅。从冷备份到热备份,从完全恢复到非完全恢复,这个过程中涉及了很多的技术细节和知识点。一些DBA初始接触这些概念和操作,容易被弄乱。Oracle 11g推出的Data Recovery Advisor,就是提供给我们一个自动诊断、修复数据库的选择。
1、Advisor
从9i和10g开始,我们就开始接触各种的Advisor。从内存大小,例如SGA、Buffer Cache和PGA,到存储段结构Segment Space Advisor和SQL Tuning Advisor,Oracle在试图构建起一个Advisor Framework。
Oracle的Advisor大都是有“后台运行、自动建议”的特点。这些Advisor往往是和Oracle自动后台作业绑定,由一个或者多个后台进程进行自动信息收集诊断,并且最后生成诊断建议。
应该说,Advisor是Oracle迈向自动化、智能化的一个重要战略步骤。本篇介绍的Data Recovery Advisor就是应用于数据恢复领域的一个重要Advisor组件。
Data Recovery Advisor(以下简称DRA)是Oracle的一个内置(Build-In)工具,用于进行数据错误、损坏的报告和修复建议。比如,DRA能够自动发现当前存在坏块,并且查看备份资料库(RMAN),给出修复建议和语句。DRA甚至可以做到“一键式”的恢复,敲一个修复命令,就自动执行修复脚本,将错误解除。
DRA是和Oracle经典备份还原工具RMAN绑定使用的。DRA是自动在后台进行数据库状态检查和数据收集,一旦发现错误,就会自动的进行修复建议的提示。DRA目前可以在两种方式下进行工作,一个是数据库启动障碍,比如启动过程报错。另一个是运行过程障碍,例如运行中数据库异常损坏(如数据文件被后台删除)。
目前DRA可以支持User界面和命令行两种方式工作。在OEM中,我们点击修复链接,查看或者直接解决问题。在命令行中,我们可以使用RMAN的命令进行处理。
2、环境准备
所谓,“巧妇难为无米之炊”。应该注意:DRA是一个自动辅助工具,对DBA而言,是一个规范操作的辅助者,而不是“点石成金”的“万灵药”。DRA进行数据恢复所依据的,也是Oracle原有的备份还原体系,并没有引入什么特殊功能。换句话说,一个非归档、无备份、无冗余配置的数据库,有致命错误发生的时候,DRA也是无能为力的。
这也就是说,备份还是要做。我们首先在实验前,进行一个完整备份。选择Oracle 11g进行实验,开启归档模式。
[oracle@bspdev ~]$ sqlplus /nolog
SQL*Plus: Release 11.2.0.1.0 Production on Fri Sep 6 06:09:292013
Copyright (c) 1982, 2009, Oracle. Allrights reserved.
SQL> conn / as sysdba
Connected to an idle instance.
SQL> startup mount
ORACLE instance started.
Total System Global Area 849530880 bytes
(篇幅原因,有省略……)
RedoBuffers 5132288bytes
Database mounted.
--查看是否归档模式
SQL> archive log list;
Database logmode ArchiveMode
Automaticarchival Enabled
Archivedestination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 172
Next log sequence to archive 174
Current logsequence 174
使用RMAN进行一个全备份。
SQL> alter database open;
Database altered.
[oracle@bspdev ~]$ rman nocatalog
Recovery Manager: Release 11.2.0.1.0 - Production on FriSep 6 06:14:28 2013
Copyright (c) 1982, 2009, Oracle and/or itsaffiliates. All rights reserved.
RMAN> connect target /
connected to target database: WILSON (DBID=3906514064)
using target database control file instead of recoverycatalog
RMAN> backup database plus archivelog delete input;
Starting backup at 06-SEP-13
current log archived
(略过细节......)
在RMAN中,我们可以使用list failure all;的DRA命令来查看当前存在的错误列表。
RMAN> list failure all;
no failures found that match specification
下面,我们分别选择启动过程和运行过程两个场景进行恢复演示。
3、启动过程数据库故障演示
在启动过程出现数据库错误占到了数据库错误的相当比例。DRA是可以在这个过程中帮助我们解决问题的。
首先,我们先制造一个问题。当前存在两个控制文件,互为备份。
SQL> col name for a100;
SQL> select name from v$controlfile;
NAME
---------------------------------------------------------------
/u01/oradata/WILSON/controlfile/o1_mf_7xt44jkr_.ctl
/u01/flash_recovery_area/WILSON/controlfile/o1_mf_7xt44kbv_.ctl
意外中断系统,删除一个控制文件。
SQL> conn / as sysdba
Connected.
SQL> shutdown abort;
ORACLE instance shut down.
[oracle@bspdev ~]$ cd /u01/oradata/WILSON/controlfile/
[oracle@bspdev controlfile]$ ls -l
total 9856
-rw-r----- 1 oracle oinstall 10076160 Sep 606:36 o1_mf_7xt44jkr_.ctl
[oracle@bspdev controlfile]$ mv o1_mf_7xt44jkr_.ctlo1_mf_7xt44jkr_.ctl.bak
[oracle@bspdev controlfile]$ ls -l
total 9856
-rw-r----- 1 oracle oinstall 10076160 Sep 606:36 o1_mf_7xt44jkr_.ctl.bak
再次启动的时候,数据库必然会有一个报错的动作。
SQL> conn / as sysdba
Connected to an idle instance.
SQL> startup
ORACLE instance started.
Total System Global Area 849530880 bytes
FixedSize 1339824bytes
VariableSize 616566352bytes
DatabaseBuffers 226492416 bytes
RedoBuffers 5132288bytes
ORA-00205: error in identifying control file, check alertlog for more info
定位控制文件失败,从alert log中找到内容。
MMNL started with pid=16, OS id=4418
starting up 1 shared server(s) ...
ORACLE_BASE from environment = /u01
Fri Sep 06 07:06:42 2013
ALTER DATABASE MOUNT
ORA-00210: cannot open the specified control file
ORA-00202: control file:'/u01/oradata/WILSON/controlfile/o1_mf_7xt44jkr_.ctl'
ORA-27037: unable to obtain file status
Linux Error: 2: No such file or directory
Additional information: 3
ORA-205 signalled during: ALTER DATABASE MOUNT...
Fri Sep 06 07:06:44 2013
Checker run found 1 new persistent data failures
在进入mount阶段的时候,Oracle发现control file不能读取的问题。注意alert log片段的最后一行,Oracle说:我引入的checker不断在进行轮询过程,发现这个问题还存在。这个时候,熟练的DBA是可以继续工作的,或者用备份进行恢复,或者拷贝一个完全版本。但是在DRA时代,我们还可以“问问Oracle Advisor怎么办?”。
此时,我们使用rman,来查看信息。
RMAN> list failure ;
List of Database Failures
=========================
Failure ID Priority Status TimeDetected Summary
---------- -------- --------- ------------- -------
3842 CRITICAL OPEN 06-SEP-13 Controlfile /u01/oradata/WILSON/controlfile/o1_mf_7xt44jkr_.ctl is missing
信息非常详细,Oracle给这个错误一个编号,并且分了级别,有了说明信息。明确说明问题在哪儿。
List failure命令是将所有的错误失败显示出来,我们还可以针对一个failure id进行信息显示。
RMAN> list failure 3842 detail;
List of Database Failures
=========================
Failure ID Priority Status TimeDetected Summary
---------- -------- --------- ------------- -------
3842 CRITICALOPEN 06-SEP-13 Control file/u01/oradata/WILSON/controlfile/o1_mf_7xt44jkr_.ctl is missing
Impact: Database cannot be mounted
List failure是第一个DRA命令。Advise failure是问问Oracle怎么办?
RMAN> advise failure;
List of Database Failures
=========================
Failure ID Priority Status TimeDetected Summary
---------- -------- --------- ------------- -------
3842 CRITICALOPEN 06-SEP-13 Control file/u01/oradata/WILSON/controlfile/o1_mf_7xt44jkr_.ctl is missing
Impact: Database cannot be mounted
analyzing automatic repair options; this may take sometime
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=20 device type=DISK
analyzing automatic repair options complete
Mandatory Manual Actions
========================
no manual actions available
Optional Manual Actions
=======================
no manual actions available
Automated Repair Options
========================
Option Repair Description –可用的修复措施
------ ------------------
1 Use a multiplexed copy to restorecontrol file /u01/oradata/WILSON/controlfile/o1_mf_7xt44jkr_.ctl
Strategy: The repair includes complete media recoverywith no data loss
Repair script./u01/diag/rdbms/wilson/wilson/hm/reco_148645850.hm
Oracle DRA说,我们可以使用Control File的另一个冗余拷贝进行恢复。并且给出了一个repair script。
[oracle@bspdev controlfile]$ cat cat/u01/diag/rdbms/wilson/wilson/hm/reco_148645850.hm
cat: cat: No such file or directory
# restore control file using multiplexed copy
restore controlfile from'/u01/flash_recovery_area/WILSON/controlfile/o1_mf_7xt44kbv_.ctl';
sql 'alter database mount';
两条语句,都是要求在rman下面运行。一个是使用当前镜像文件进行恢复,另一个是启动数据库。
我们听从DRA的指令,手工运行一下脚本命令。此时,数据库处在一个中间启动状态。
--实例已经启动
[oracle@bspdev controlfile]$ ps -ef | grep pmon
oracle 4360 1 007:06 ? 00:00:00 ora_pmon_wilson
oracle 4551 3270 0 07:15 pts/0 00:00:00grep pmon
SQL> select status from v$instance;
STATUS
------------
STARTED
RMAN中执行程序脚本。
--执行脚本命令
RMAN> restore controlfile from'/u01/flash_recovery_area/WILSON/controlfile/o1_mf_7xt44kbv_.ctl';
Starting restore at 06-SEP-13
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=1 device type=DISK
channel ORA_DISK_1: copied control file copy
output file name=/u01/oradata/WILSON/controlfile/o1_mf_7xt44jkr_.ctl
output filename=/u01/flash_recovery_area/WILSON/controlfile/o1_mf_7xt44kbv_.ctl
Finished restore at 06-SEP-13
RMAN> sql 'alter database mount';
sql statement: alter database mount
released channel: ORA_DISK_1
此时,数据库可以顺利的open,并且原来的list failure错误信息消失。
--进入open状态
SQL> conn / as sysdba
Connected.
SQL> select status from v$instance;
STATUS
------------
MOUNTED
SQL> alter database open;
Database altered.
[oracle@bspdev controlfile]$ ls -l
total 19712
-rw-r----- 1 oracle oinstall 10076160 Sep 6 07:21o1_mf_7xt44jkr_.ctl
-rw-r----- 1 oracle oinstall 10076160 Sep 606:36 o1_mf_7xt44jkr_.ctl.bak
RMAN> list failure all;
no failures found that match specification
这个案例告诉我们,RMAN中的DRA可以做到在启动过程中,不断诊断发现问题,提供解决方案。更重要的是还可以提供状态修改的脚本语句。
下面,我们进行一个Open状态故障的诊断,并且看看怎么在DRA如何实现“一键式”系统修复。
4、运行过程中故障
在运行过程中的oracle故障,坏块和文件异常删除出现的比较多,特别是初级DBA刚刚上手的时候。我们先来模拟一下这个场景。
Undo表空间是Oracle核心表空间之一,删除之后会引起比较严重的问题故障。
SQL> select file_name from dba_data_files wheretablespace_name='UNDOTBS1';
FILE_NAME
--------------------------------------------------------------------------------
/u01/oradata/WILSON/datafile/o1_mf_undotbs1_7xt3yzl5_.dbf
当前数据库处在Open运行状态,突然Undo文件被后OS层面删除。
[oracle@bspdev datafile]$ ls -l | grep undo
-rw-r----- 1 oracle oinstall 346038272 Sep 607:21 o1_mf_undotbs1_7xt3yzl5_.dbf
[oracle@bspdev datafile]$ mv o1_mf_undotbs1_7xt3yzl5_.dbfo1_mf_undotbs1_7xt3yzl5_.dbf.bak
[oracle@bspdev datafile]$ ls -l | grep undo
-rw-r----- 1 oracle oinstall 346038272 Sep 607:21 o1_mf_undotbs1_7xt3yzl5_.dbf.bak
此时,alert log中可以出现上篇中那个“checker”的工作过程。
Fri Sep 06 07:25:47 2013
Checker run found 1 new persistent data failures
Fri Sep 06 07:26:34 2013
Starting background process SMCO
Fri Sep 06 07:26:34 2013
SMCO started with pid=19, OS id=4819
Fri Sep 06 07:26:46 2013
Errors in file /u01/diag/rdbms/wilson/wilson/trace/wilson_mmnl_4418.trc:
ORA-01116: error in opening database file 3
ORA-01110: data file 3:'/u01/oradata/WILSON/datafile/o1_mf_undotbs1_7xt3yzl5_.dbf'
ORA-27041: unable to open file
Linux Error: 2: No such file or directory
Additional information: 3
Fri Sep 06 07:26:48 2013
Errors in file/u01/diag/rdbms/wilson/wilson/trace/wilson_m000_4835.trc:
ORA-01116: error in opening database file 3
ORA-01110: data file 3:'/u01/oradata/WILSON/datafile/o1_mf_undotbs1_7xt3yzl5_.dbf'
ORA-27041: unable to open file
Linux Error: 2: No such file or directory
Additional information: 3
差不多两秒钟报一个错误,发现文件被删除无法打开。
此时,我们在rman上使用list failure命令,查看生成的错误信息。
RMAN> list failure all;
List of Database Failures
=========================
Failure ID Priority Status TimeDetected Summary
---------- -------- --------- ------------- -------
242 HIGH OPEN 06-SEP-13 One ormore non-system datafiles are missing
我们使用advisor failure,查看一个Oracle的建议。
RMAN> advise failure ;
List of Database Failures
=========================
Failure ID Priority Status TimeDetected Summary
---------- -------- --------- ------------- -------
242 HIGH OPEN 06-SEP-13 One ormore non-system datafiles are missing
analyzing automatic repair options; this may take sometime
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=30 device type=DISK
analyzing automatic repair options complete
Mandatory Manual Actions
========================
1. If file /u01/oradata/WILSON/datafile/o1_mf_undotbs1_7xt3yzl5_.dbfwas unintentionally renamed or moved, restore it
2. Automatic repairs may be available if you shutdown thedatabase and restart it in mount mode
3. Contact Oracle Support Services if the precedingrecommendations cannot be used, or if they do not fix the failures selected forrepair
Optional Manual Actions
=======================
no manual actions available
Automated Repair Options
========================
no automatic repair options available
注意,在automated repair options中,我们没有看到脚本信息。说明Oracle好像在目前也没有太好的方法。在Manual Actions中,Oracle DRA要求将数据库重启到mount状态,才能有自动脚本的出现。Manual Actions是那些Oracle觉得需要用户手工执行才能继续下去的步骤。
重新启动一下库,加载到mount状态。
--强制关闭
RMAN> shutdown abort;
Oracle instance shut down
RMAN> startup mount;
connected to target database (not started)
Oracle instance started
database mounted
Total System Global Area 849530880bytes
FixedSize 1339824bytes
VariableSize 616566352bytes
Database Buffers 226492416bytes
RedoBuffers 5132288bytes
此时再次使用DRA工具,看问题和提示内容。
RMAN> advise failure;
List of Database Failures
=========================
Failure ID Priority Status TimeDetected Summary
---------- -------- --------- ------------- -------
242 HIGH OPEN 06-SEP-13 One ormore non-system datafiles are missing
analyzing automatic repair options; this may take sometime
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=18 device type=DISK
analyzing automatic repair options complete
Mandatory Manual Actions
========================
no manual actions available
Optional Manual Actions
=======================
1. If file/u01/oradata/WILSON/datafile/o1_mf_undotbs1_7xt3yzl5_.dbf was unintentionallyrenamed or moved, restore it
Automated Repair Options
========================
Option Repair Description
------ ------------------
1 Restore and recover datafile3
Strategy: The repair includes complete media recoverywith no data loss
Repair script./u01/diag/rdbms/wilson/wilson/hm/reco_1850469943.hm
在上篇中,我们是手工打开hm文件,看里面的脚本。其实还可以使用repair failure review命令来查看执行语句。
RMAN> repair failure preview;
Strategy: The repair includes complete media recoverywith no data loss
Repair script./u01/diag/rdbms/wilson/wilson/hm/reco_1850469943.hm
contents of repair script.:
# restore and recover datafile
restore datafile 3;
recover datafile 3;
注意:此时Oracle DRA发现了当前我们有Undo的备份和归档日志。所以使用restore之后伴随recover,可以快速实现恢复。
如果在preview中没有发现什么问题,可以repair failure命令执行进行恢复。
RMAN> repair failure;
Strategy: The repair includes complete media recoverywith no data loss
Repair script. /u01/diag/rdbms/wilson/wilson/hm/reco_1850469943.hm
contents of repair script.:
# restore and recover datafile
restore datafile 3;
recover datafile 3;
Do you really want to execute the above repair (enter YESor NO)? yes
executing repair script
Starting restore at 06-SEP-13
using channel ORA_DISK_1
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: specifying datafile(s) to restorefrom backup set
channel ORA_DISK_1: restoring datafile 00003 to/u01/oradata/WILSON/datafile/o1_mf_undotbs1_7xt3yzl5_.dbf
channel ORA_DISK_1: reading from backup piece/u01/flash_recovery_area/WILSON/backupset/2013_09_06/o1_mf_nnndf_TAG20130906T061608_92l0od6w_.bkp
channel ORA_DISK_1: piecehandle=/u01/flash_recovery_area/WILSON/backupset/2013_09_06/o1_mf_nnndf_TAG20130906T061608_92l0od6w_.bkptag=TAG20130906T061608
channel ORA_DISK_1: restored backup piece 1
channel ORA_DISK_1: restore complete, elapsed time:00:00:25
Finished restore at 06-SEP-13
Starting recover at 06-SEP-13
using channel ORA_DISK_1
starting media recovery
media recovery complete, elapsed time: 00:00:02
Finished recover at 06-SEP-13
repair failure complete
--可以选择打开数据库
Do you want to open the database (enter YES or NO)? yes
database opened
我们在alert log中,可以监控到恢复的步骤。
--Restore过程
Fri Sep 06 07:35:49 2013
Full restore complete of datafile 3/u01/oradata/WILSON/datafile/o1_mf_undotbs1_92l5b0v4_.dbf. Elapsedtime: 0:00:15
checkpoint is 3838694
last deallocation scn is 3817636
Undo Optimization current scn is 3815429
Fri Sep 06 07:35:54 2013
alter database recover datafile list clear
Completed: alter database recover datafile list clear
--recovery过程
alter database recover if needed
datafile 3
Media Recovery Start
Serial Media Recovery started
Recovery of Online Redo Log: Thread 1 Group 2 Seq 176Reading mem 0
Mem# 0:/u01/oradata/WILSON/onlinelog/o1_mf_2_870n48hc_.log
Mem# 1: /u01/flash_recovery_area/WILSON/onlinelog/o1_mf_2_870n4dtl_.log
Recovery of Online Redo Log: Thread 1 Group 3 Seq 177Reading mem 0
Mem# 0:/u01/oradata/WILSON/onlinelog/o1_mf_3_870n4lsg_.log
Mem# 1:/u01/flash_recovery_area/WILSON/onlinelog/o1_mf_3_870n4o31_.log
Recovery of Online Redo Log: Thread 1 Group 1 Seq 178Reading mem 0
Mem# 0:/u01/oradata/WILSON/onlinelog/o1_mf_1_870n42n1_.log
Mem# 1:/u01/flash_recovery_area/WILSON/onlinelog/o1_mf_1_870n44z3_.log
Media Recovery Complete (wilson)
Completed: alter database recover if needed
datafile 3
Fri Sep 06 07:36:04 2013
alter database open
此时,数据库错误消除。
RMAN> list failure;
no failures found that match specification
最后,我们还有一个命令可以使用,就是change failure。Change Failure命令的作用就是显示的将错误的状态修改掉。最常用的做法是:当一个错误发生的时候,如果我们没有在RMAN层面上去解决,比如使用冷备份方法还原。Failure信息是不会变化状态的。此时,可以使用change failure命令将状态设置为Closed,命令如:change failure all closed。
5、结论
注意,目前的11g版本中,Data Recovery Advisor还不支持RAC环境。
随着版本的推进,越来越多的Advisor出现在我们周围。从目前看,Advisor只是一个信息咨询专家库,我们可以听也可以不听。很多老资格的DBA对这些“花哨”产品也是比较不屑。笔者认为大可不必。
工具的出现,自动化、智能化是任何一个事物的必然过程。可能在早期的版本中,一些Advisor存在这样或者那样的问题。但是随着不断的改进升级,这些Advisor变的越来越智能,也是不可辩驳的事实。最终智能化也只是时间的问题了。
那么,作为传统业务的DBA我们自己,应该怎么做呢?首先,原理一定要作为基础。任何技术,特别是Oracle近几个版本,都遵循9i时期奠定的基础框架和机制。很多花哨产品都是以此为基础进行研发,所以理解基础很重要。其次,业务价值。开发DBA是一个体现业务价值的重要方面,将数据库的理念带入到架构设计、开发过程,可以让我们的系统衔接的更平顺。最后就是行业优势,Oracle是死的,应用行业是多样的。每一个行业都有自己的特点和取向。作为DBA,特别是资深DBA,对业务数据的敏感度要远大于开发团队的很多人,把价值发挥出来,空间自然不会小。
Oracle 11g 新特性 -- RMAN Data Recovery Advisor(DRA) 说明
一.Data Recovery Advisor(DRA) 说明
1.1 DRA 说明
DRA在遇到错误时会自动收集数据故障信息。此外,它还能预先检查故障。在此模式中,它可以在数据库进程发现损坏并发送错误消息之前检测和分析数据故障(请注意,修复始终在人为控制之下进行)。
数据故障可能非常严重。例如,如果缺少最新的日志文件,则无法启动数据库。一些数据故障(如数据文件中的块损坏)不是灾难性故障,因为它们不会使数据库停机,也不会阻止您启动Oracle 实例。数据恢复指导可处理以下两种情况:一种情况是您无法启动数据库(因为缺少一些必需的数据库文件,或者这些数据库文件不一致或已损坏),另一种情况是运行时发现文件损坏。
解决严重数据故障的首选方法是首先将故障转移至备用数据库(前提是在Data Guard 配置下),这样用户就可以尽快恢复联机。然后,需要修复数据故障的主要原因,但幸运的是,此操作不会影响用户。
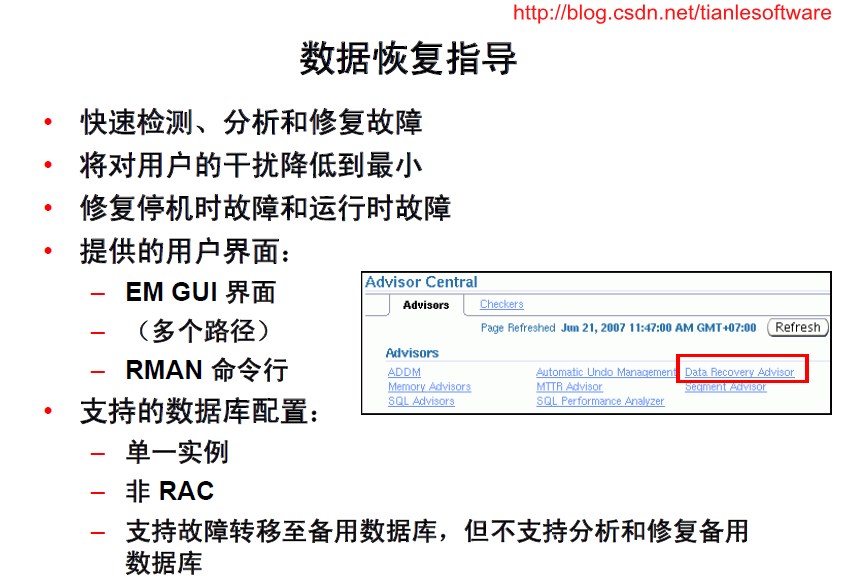
1.2 自动诊断工作流
Oracle Database11g 中的自动诊断工作流可为您执行工作流步骤。使用数据恢复指导,您只需启动建议和修复。
1. 健康状况监视器会自动执行检查,并将故障及其故障现象作为“查找结果”记录到自动诊断资料档案库(ADR) 中。
2. 数据恢复指导将查找结果与故障合并在一起。它列出了先前执行的评估结果,其中包含故障严重程度(严重或高)。
3. 如果您要求系统提供有关故障的修复建议,数据恢复指导会将故障映射到自动和手动修复选项,检查基本可行性,并为您提供修复建议。
4. 可以选择手动执行修复或者请求数据恢复指导为您执行此操作。
5. 除了健康状况监视器和数据恢复指导自动执行的主要“被动”检查之外,Oracle 还建议使用VALIDATE 命令进行“预防性”检查。

1.3 RMAN中使用DRA 步骤
Oracle的OEM已经很智能,这些操作在OEM上都可以进行,我们这里只看使用RMAN 命令来实现的步骤。
如果怀疑或已知道数据库出现故障,则可使用LIST FAILURE 命令获得关于这些故障的信息。可以列出所有故障或部分故障并以多种方式限制输出。故障由故障号进行唯一标识。请注意,这些故障号不是连续的,因此它们之间的间隔没有任何意义。
ADVISE FAILURE 命令将显示为指定故障建议的修复选项。它可打印输入故障概要并隐式关闭已修复的所有打开的故障。没有使用任何选项时,默认行为是对记录在ADR 中优先级为CRITICAL 和HIGH的所有故障提供建议。
在同一RMAN 会话中REPAIR FAILURE 命令在ADVISE FAILURE 命令后使用。默认情况下,该命令使用当前会话中上次执行ADVISEFAILURE 命令时建议的一个修复选项。如果没有任何修复选项,REPAIR FAILURE 命令将启动隐式ADVISE FAILURE 命令。修复完成后,该命令会关闭故障。
CHANGE FAILURE 命令将更改故障优先级或关闭一个或多个故障。仅可以更改HIGH 或LOW 故障优先级。修复故障后,将隐式关闭打开的故障。但是,也可以显式关闭故障。
1.3.1 列出数据故障
RMAN LISTFAILURE 命令可列出故障。如果目标实例使用恢复目录,它可以处于STARTED 模式下,否则必须处于MOUNTED 模式下。LIST FAILURE 命令不启动诊断新故障检查;它将列出先前执行的评估结果。重复执行LIST FAILURE 命令将重新验证所有现有的故障。
如果数据库诊断出新的故障(在命令执行之间),则会显示这些新故障。
如果用户手动修复故障或临时故障消失,则数据恢复指导会将这些故障从LIST FAILURE 输出中删除。
以下是语法说明:
(1) failnum:为其显示修复选项的故障数。
(2) ALL:列出所有优先级的故障。
(3) CRITICAL:列出优先级为CRITICAL 且处于OPEN 状态的故障。这些故障使整个数据库不可用(如控制文件缺失),因此需要立即引起注意。
(4) HIGH:列出优先级为HIGH 且处于OPEN状态的故障。这些故障使数据库部分不可用或不可恢复,因此应尽快修复(如归档重做日志缺失)。
(5) LOW:列出优先级为LOW 且处于OPEN状态的故障。低优先级的故障可以等到修复了更重要的故障后再进行修复。
(6) CLOSED:仅列出关闭的故障。
(7) EXCLUDE FAILURE:从列表中排除指定的故障号。
(8) DETAIL:通过展开合并的故障列出故障。例如,如果一个文件中有多个块损坏,则DETAIL选项将列出每个块损坏。
如:
RMAN> LIST FAILURE;
RMAN> LIST FAILURE DETAIL;
1.3.2 修复建议
RMAN ADVISE FAILURE 命令可显示指定故障的建议修复选项。如果从Enterprise Manager 中执行此命令,则Data Guard 将显示一个修复选项(但是,如果直接从RMAN 命令行执行此命令,则Data Guard 不会显示修复选项)。ADVISE FAILURE 命令可打印输入故障概要。该命令会隐式关闭已修复的所有打开的故障。
没有使用任何选项时,默认行为是对记录在自动诊断资料档案库(ADR) 中优先级为CRITICAL 和HIGH 的所有故障提供建议。如果自上次执行LIST FAILURE 命令后ADR 中记录了新故障,则在对所有CRITICAL 和HIGH 故障提供建议前,该命令将包含一个WARNING。
执行两个常规修复选项:无数据丢失修复和数据丢失修复。
DRA在生成自动修复选项时会生成一个脚本,用于显示RMAN 计划如何修复故障。如果不希望数据恢复指导自动修复故障,可从该脚本开始执行手动修复。该脚本的操作系统(OS) 位置将显示在命令输出的末尾。可以检查此脚本,并对其进行自定义(如果需要),还可以手动执行该脚本(例如在审计线索要求建议执行手动操作时)。
RMANADVISE FAILURE 命令有以下用途:
(1) 显示输入故障列表概要
(2) 包括警告(如果ADR 中出现新故障)
(3) 显示手动核对清单
(4) 列出一个建议的修复选项
(5) 生成修复脚本(用于自动或手动修复)
. . .
Repair script:
/u01/app/oracle/diag/rdbms/orcl/orcl/hm/reco_2979128860.hm
RMAN>
语法:
ADVISE FAILURE
[ ALL | CRITICAL | HIGH | LOW |failnum[,failnum,…] ]
[ EXCLUDE FAILURE failnum [,failnum,…] ]
1.3.3 执行修复
此命令应在同一RMAN 会话中的ADVISE FAILURE 命令后使用。默认情况下(没有选项),该命令使用当前会话中上次执行ADVISE FAILURE 时建议的一个修复选项。如果没有任何修复选项,REPAIRFAILURE 命令将启动隐式ADVISE FAILURE 命令。
默认情况下,您需要确认是否执行该命令,因为可能需要花费时间完成大量更改。在执行修复期间,该命令的输出将表明正在执行的修复阶段。
修复完成后,该命令会关闭故障。
语法:
REPAIR FAILURE
[PREVIEW]
[NOPROMPT]
无法运行多个并发修复会话。但是,允许并发REPAIR … PREVIEW 会话。
(1) PREVIEW 表示:不执行修复,而是显示先前生成的包含所有修复操作和注释的RMAN 脚本。
(2) NOPROMPT 表示:不要求确认。
修复故障示例
RMAN> REPAIR FAILURE PREVIEW;
RMAN> REPAIR FAILURE;
RMANREPAIR FAILURE 命令有以下用途:
(1) 遵循ADVISE FAILURE 命令
(2) 修复指定的故障
(3) 关闭已修复的故障
1.4 分类(和关闭)故障
CHANGE FAILURE 命令用于更改故障优先级或关闭一个或多个故障。
语法:
CHANGE FAILURE
{ ALL | CRITICAL | HIGH | LOW |failnum[,failnum,…] }
[ EXCLUDE FAILURE failnum[,failnum,…] ]
{ PRIORITY {CRITICAL | HIGH | LOW} |
CLOSE } - 将故障的状态更改为已关闭
[ NOPROMPT ] - 不要求用户进行确认
只能将故障优先级从HIGH 更改为LOW 和从LOW 更改为HIGH。更改CRITICAL 优先级会出现错误。(将故障的优先级从HIGH 更改为LOW 的一个原因是为了避免该故障显示在LIST FAILURE 命令的默认输出列表中。例如,如果块损坏具有HIGH 优先级,则该块位于很少使用的表空间中时,您可能希望将其临时更改为LOW。)
修复故障后,将隐式关闭打开的故障。但是,也可以显式关闭故障。这需要重新评估其它所有打开的故障,因为其中的某些故障会因故障关闭而变得不相关。
默认情况下,该命令要求用户确认请求的更改。
1.5 DRA相关的视图
查询动态数据字典视图:
(1) V$IR_FAILURE:所有故障的列表,包括已关闭的故障(LIST FAILURE 命令的结果)
(2) V$IR_MANUAL_CHECKLIST:手动建议的列表(ADVISE FAILURE命令的结果)
(3) V$IR_REPAIR:修复列表(ADVISE FAILURE 命令的结果)
(4) V$IR_FAILURE_SET:故障和建议标识符的交叉引用
1.6 预防性检查
对于非常重要的数据库,可能需要执行其它预防性检查(可以在每天的低峰时段执行)。
可通过健康状况监视器或使用RMANVALIDATE 命令安排定期的健康状况检查。通常,如果被动检查在数据库组件中检测到故障,则可能需要对受影响的组件执行更全面的检查。
RMAN VALIDATE DATABASE 命令用于调用对数据库及其组件的健康状况检查。它扩展了现有的VALIDATE BACKUPSET 命令。在验证期间检测到的所有问题都会显示出来,这些问题进而会启动故障评估。如果检测到故障,则该故障会作为查找结果记录到ADR中。可以使用LIST FAILURE 命令查看资料档案库中记录的所有故障。
VALIDATE 命令支持对单个备份集和数据块进行验证。在物理损坏中,数据库根本无法识别块。在逻辑损坏中,块的内容在逻辑上不一致。默认情况下,VALIDATE 命令只检查物理损坏。也可以指定CHECK LOGICAL 检查逻辑损坏。
块损坏可分为块间损坏和块内损坏。在块内损坏中,块本身发生损坏,可以是物理损坏也可以是逻辑损坏。在块间损坏中,块与块之间发生的损坏只能是逻辑损坏。VALIDATE 命令只检查块内损坏。
调用对数据库及其组件的预防性健康状况检查:
(1) 健康状况监视器或RMAN VALIDATE DATABASE 命令
(2) 检查逻辑和物理损坏
(3) 在ADR 中记录查找结果
二.DRA 示例
2.1 创建故障
SQL> select file_name fromdba_data_files;
FILE_NAME
--------------------------------------------------------------------------------
/u01/app/oracle/oradata/anqing/dave01.dbf
/u01/app/oracle/oradata/anqing/users01.dbf
/u01/app/oracle/oradata/anqing/undotbs01.dbf
/u01/app/oracle/oradata/anqing/sysaux01.dbf
/u01/app/oracle/oradata/anqing/system01.dbf
/u01/app/oracle/oradata/anqing/example01.dbf
--破坏users01.dbf 数据文件:
[oracle@dave anqing]$ pwd
/u01/app/oracle/oradata/anqing
[oracle@dave anqing]$ ll users01.dbf
-rw-r----- 1 oracle oinstall 34086912 10??11 22:52 users01.dbf
[oracle@dave anqing]$ echo > users01.dbf
[oracle@dave anqing]$ ll users01.dbf
-rw-r----- 1 oracle oinstall 1 10?? 1122:55 users01.dbf
--在users表空间上创建表:anqing
SQL> create table anqing(id number)tablespace users;
create table anqing(id number) tablespaceusers
*
ERROR at line 1:
ORA-01115: IO error reading block fromfile (block # )
ORA-01110: data file 4:'/u01/app/oracle/oradata/anqing/users01.dbf'
ORA-27072: File I/O error
Additional information: 4
Additional information: 3
--错误信息会写入ADR,验证:
adrci> show homepath
ADR Homes:
diag/rdbms/dave/dave
diag/tnslsnr/dave/listener
adrci> set homepath diag/rdbms/dave/dave
adrci> show alert -tail
…
2012-10-11 22:53:39.334000 +08:00
Starting background process SMCO
SMCO started with pid=33, OS id=11016
2012-10-1122:56:34.746000 +08:00
Checker run found 1 newpersistent data failures
2.2 RMAN LIST FAILURE
[oracle@dave ~]$rman target /
Recovery Manager: Release 11.2.0.3.0 -Production on Thu Oct 11 23:06:52 2012
Copyright (c) 1982, 2011, Oracle and/or itsaffiliates. All rights reserved.
connected to target database: DAVE(DBID=856255083)
RMAN> list failure;
using target database control file insteadof recovery catalog
List of Database Failures
=========================
Failure ID Priority Status Time Detected Summary
---------- -------- --------- --------------------
282 HIGH OPEN 11-OCT-12 One or morenon-system datafiles are corrupt
注意:
Listfailure 命令会显示任何open 状态的failures,并会优先显示critical 或high的failure,如果没有类似的failure,那么会显示low 的failures。
2.3 RMAN ADVISE FAILURE
RMAN> advise failure;
List of Database Failures
=========================
Failure ID Priority Status Time Detected Summary
---------- -------- --------- --------------------
282 HIGH OPEN 11-OCT-12 One or more non-system datafiles arecorrupt
analyzing automatic repair options; thismay take some time
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=18 device type=DISK
analyzing automatic repair options complete
Mandatory Manual Actions
========================
no manual actions available
Optional Manual Actions
=======================
no manual actions available
Automated Repair Options
========================
Option Repair Description
------ ------------------
1 Restore and recover datafile 4
Strategy: The repair includes complete media recovery with no data loss
Repair script: /u01/app/oracle/diag/rdbms/dave/dave/hm/reco_1992614502.hm
--这里能恢复的前提是有有效的RMAN 备份,否则这里不能进行restore。
--这个是恢复的脚本:可以手动执行,也可以使用自动执行:
[oracle@dave ~]$cat/u01/app/oracle/diag/rdbms/dave/dave/hm/reco_1992614502.hm
#restore and recover datafile
restore datafile 4;
recover datafile 4;
sql 'alter database datafile 4 online';
2.4 RMAN REPAIR FAILURE
RMAN> repair failure preview;
Strategy: The repair includes completemedia recovery with no data loss
Repair script:/u01/app/oracle/diag/rdbms/dave/dave/hm/reco_1992614502.hm
contents of repair script:
#restore and recover datafile
restore datafile 4;
recover datafile 4;
sql 'alter database datafile 4 online';
--默认情况下,repair failure 命令会提示用户确认修复,这里我们使用noprompt跳过验证:
RMAN> repair failure noprompt;
Strategy: The repair includes completemedia recovery with no data loss
Repair script:/u01/app/oracle/diag/rdbms/dave/dave/hm/reco_1992614502.hm
contents of repair script:
#restore and recover datafile
restore datafile 4;
recover datafile 4;
sql 'alter database datafile 4 online';
executing repair script
Starting restore at 11-OCT-12
using channel ORA_DISK_1
channel ORA_DISK_1: starting datafilebackup set restore
channel ORA_DISK_1: specifying datafile(s)to restore from backup set
channel ORA_DISK_1: restoring datafile00004 to /u01/app/oracle/oradata/anqing/users01.dbf
channel ORA_DISK_1: reading from backuppiece /u01/backup/ave_lev0_0bnnh6co_1_1_20121011
channel ORA_DISK_1: piecehandle=/u01/backup/ave_lev0_0bnnh6co_1_1_20121011 tag=DAVE_LEV0
channel ORA_DISK_1: restored backup piece 1
channel ORA_DISK_1: restore complete,elapsed time: 00:00:07
Finished restore at 11-OCT-12
Starting recover at 11-OCT-12
using channel ORA_DISK_1
starting media recovery
media recovery complete, elapsed time:00:00:01
Finished recover at 11-OCT-12
sql statement: alter database datafile 4online
repair failure complete
database opened
RMAN>
2.5 RMAN CHANGE FAILURE
Change failure 命令可以改变failure的级别,在2.2 节,我们的failure级别是high。如果有一个failure,在我们没有修复之前,或者暂时不想修复,那么我们就可以调低它的级别,级别的修改不影响系统的正常使用。
如:
RMAN> CHANGEFAILURE 282 PRIORITY LOW;
2.6 验证 VALIDATE
# Check for physical corruption of alldatabase files.
VALIDATE DATABASE;
# Check for physical and logical corruptionof a tablespace.
VALIDATE CHECK LOGICAL TABLESPACE USERS;
# Check for physical and logical corruptionof a datafile.
VALIDATE CHECK LOGICAL DATAFILE 4;
# Check for physical corruption of allarchived redo logs files.
VALIDATE ARCHIVELOG ALL;
# Check for physical and logical corruptionof the controlfile.
VALIDATE CHECK LOGICAL CURRENT CONTROLFILE;
# Check for physical and logical corruptionof a specific backupset.
VALIDATE CHECK LOGICAL BACKUPSET 3;
# Check for physical corruption of files tobe backed up.
BACKUP VALIDATE DATABASE ARCHIVELOG ALL;
# Check for physical and logical corruptionof files to be backed up.
BACKUP VALIDATE CHECK LOGICAL DATABASEARCHIVELOG ALL;
# Check for physical corruption of files tobe restored.
RESTORE VALIDATE DATABASE;
# Check for physical and logical corruptionof files to be restored.
RESTORE VALIDATE CHECK LOGICAL DATABASE;
http://blog.csdn.net/tianlesoftware/article/details/6460464
About Me
...............................................................................................................................
● 本文整理自网络
● 本文在itpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● QQ群:230161599 微信群:私聊
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2017-07-01 09:00 ~ 2017-07-31 22:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
...............................................................................................................................
拿起手机使用微信客户端扫描下边的左边图片来关注小麦苗的微信公众号:xiaomaimiaolhr,扫描右边的二维码加入小麦苗的QQ群,学习最实用的数据库技术。