

从事务理论的角度来看,可以把事务分为以下几种类型
扁平事务(Flat Transactions)
带有保存点的扁平事务(Flat Transactions with Savepoints)
链事务(Chained Transactions)
嵌套事务(Nested Transactions)
分布式事务(Distributed Transactions)
扁平事务 是事务类型中最简单的一种,但是在实际生产环境中,这可能是使用最频繁的事务,在扁平事务中,所有操作都处于同一层次,其由BEGIN WORK开始,由COMMIT WORK或ROLLBACK WORK结束,其间的操作是源自的,要么都执行,要么都回滚,因此扁平事务是应用程序称为原子操作的的基本组成模块
下面显示了扁平事务的三种不同结果

给出的扁平事务的三种情况,同时也给出了一个典型的事务处理应用中,每个结果大概占用的百分比。再次提醒,扁平事务虽然简单,但是在实际环境中使用最为频繁,也正因为其简单,使用频繁,故每个数据库系统都实现了对扁平事务的支持
扁平事务的主要限制是不能提交或者回滚事务的某一部分,或分几个步骤提交。下面给出一个扁平事务不足以支持的例子。例如用户在旅行网站上进行自己的旅行度假计划,用户设想从杭州到意大利的佛罗伦萨,这两个城市没有直达的班机,需要用户预订并转呈航班,需要或者搭火车等待。用户预订旅行度假的事务为
BEGIN WORK:
S1:预订杭州到上海的高铁
S2:上海浦东国际机场坐飞机,预订到米兰的航班
S3:在米兰转火车前往佛罗伦萨,预订去佛罗伦萨的火车
但是当用户执行到S3时,发现由于飞机到达米兰的时间太晚,已经没有当天的火车,这时用户希望在米兰当地住一晚,第二天出发去佛罗伦萨。这时如果事务为扁平事务,需要回滚之前S1 S2 S3的三个操作,这个代价明显很大,因为当再次进行该事务是,S1 S2的执行计划是不变的,也就是说,如果支持有计划的回滚操作,那么不需要终止整个事务,因此就出现了带有保存点的扁平事务
带有保存点的扁平事务 除了支持扁平事务支持的操作外,允许在事务执行过程中回滚同一事务中较早的一个状态。这是因为某些事务可能在执行过程中出现的错误并不会导致所有的操作都无效,放弃整个事务不合乎要求,开销太大,保存点用来通知事务系统应该记住事务当前的状态,以便当之后发生错误时,事务能回到保存点当时的状态
对于扁平的事务来说,隐式的设置了一个保存点。然而整个事务中,只有这一个保存点,因此,回滚只能会滚到事务开始时的状态,保存点用SAVE WORK函数来建立,通知系统记录当前的处理状态。当出现问题时,保存点能用作内部的重启动点,根据应用逻辑,决定是回到最近一个保存点还是其他更早的保存点。图显示了事务中使用的保存点
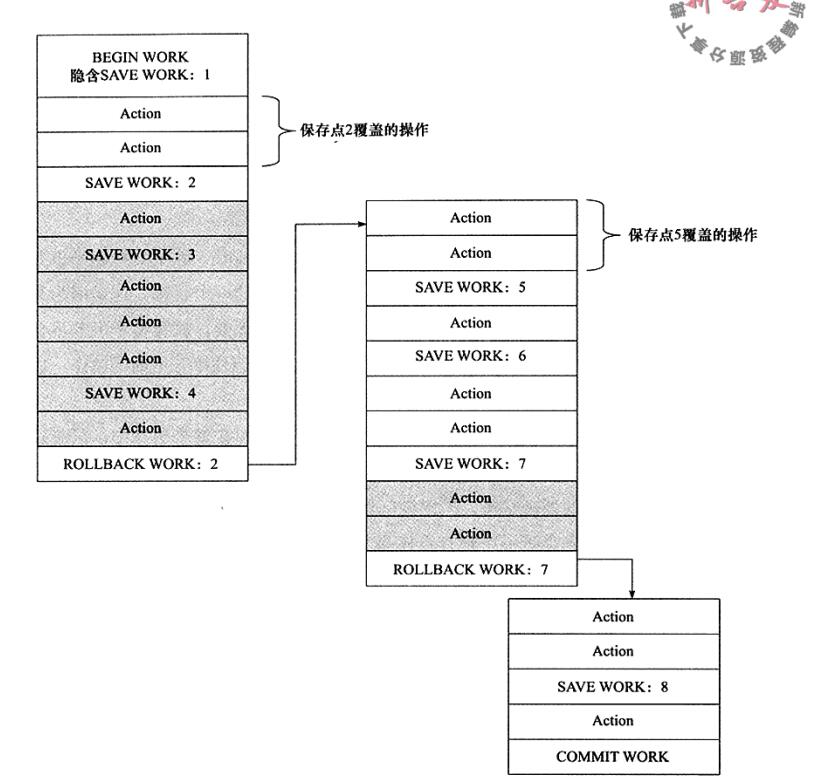
显示了如何在事务中使用保存点,灰色背景部分表示由ROLLBACK WORK而导致部分回滚,实际并没有执行操作,当用BEGIN WORK开启一个事务时,隐式地包含了一个保存点,当事务通过ROLLBACK WORK:2发出部分回滚命令时,事务会滚到保存点2,接着依次执行,并再次执行到ROLLBACK WORK:7,知道最后COMMIT WORK操作,表示事务结束,除灰色阴影部分的操作外,其余操作都已经执行,并且提交
另一个需要注意的是,保存点在事务内部是递增的,从图中可以看出,有人可能会想,返回保存点2以后,下一个保存点可以为3,因为之前的工作已经终止,然而新的保存点编号为5,这意味着ROLLBACKU 不影响保存点的计数,并且单调递增编号能保持事务执行的整个历史过程,包括在执行过程中想法的改变
此外,当事务通过ROLLBACK WORK:2命令发出部分回滚命令时,要记住事务并没有完全被回滚,只是回滚到保存点2而已,这代表当前事务是活跃的,如果想要回滚事务,还需要执行ROLLBACKUP WORK
链事务 可视为保存点模式的一种变种,带有保存点的扁平事务,当发生系统崩溃是,所有的的保存点都将消失,因为其保存点是易失的,这意味着当进行恢复时,事务需要从开始处重新执行,而不能从最近的一个保存点继续执行
链事务的思想是:在提交一个事务时,释放不需要的数据对象,将必要的处理上下文隐式地传给下一个要开始的事务,提交事务操作和开始下一个事务操作 将合并为一个原子操作,这意味着下一个事务将看到上一个事务的结果,就好像一个事务中进行的一样,如图显示了链事务的工作方式

链事务与带有保存点的扁平事务不同的是,带有保存点的扁平事务能回滚到任意正确的保存点,而链事务中的回滚仅限当前事务,即只能恢复到最近的一个保存点,对于锁的处理,两者也不相同,锁事务在执行COMMIT后即释放了当前所持有的锁,而带有保存点的扁平事务不影响迄今为止所持有的锁
嵌套事务 是一个层次结构框架,由一个顶层事务(top-level transaction)控制着各个层次的事务,顶层事务之下嵌套的事务被称为子事务,其控制每一个局部的变换,结构如下
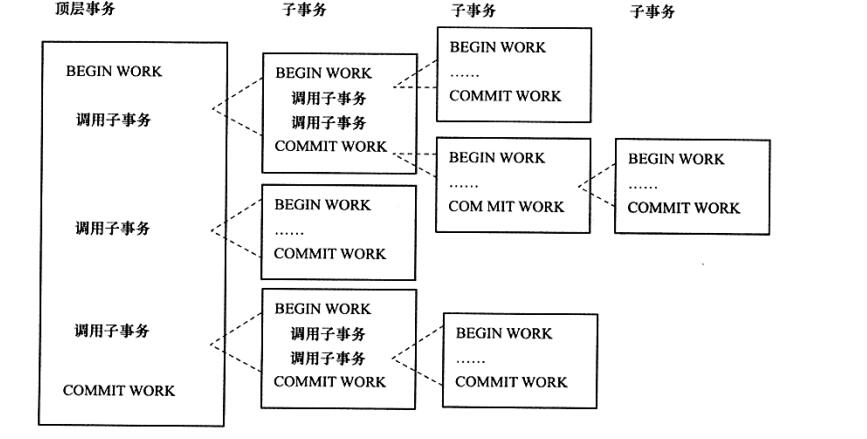
下面给出MOSS对嵌套事务的定义
1 嵌套事务是由若干事务组成的一棵树,子树既可以是嵌套事务也可以是扁平事务
2 处在叶节点的事务是扁平事务,但是每个事务从根到叶节点的距离可以说是不同的
3 位于根节点的事务称为顶层事务,其他称为自事务。事务的前驱称(predecessor)为父事务(parent),事务的下一层称为儿子事务(child)
4 子事务既可以提交也可以回滚。但是它的提交操作并不马上生效。除非其父事务已经提交。因此可以推论出,任何子事务都在顶层事务提交后才真正的提交
5 树中的任意事务回滚会引起它的所有子事务一同回滚,故子事务仅保留ACI特性而不具有D特性
在Moss的理论中,实际的工作是交由叶子节点完成,即只有叶子节点的事务才能才能访问数据库、发送信息、获取其他类型的资源。而高层的事务仅负责逻辑控制。决定合适调用相关的子事务。即使一个系统不支持嵌套事务,用户也可以通过保存点技术来模拟嵌套事务,如图
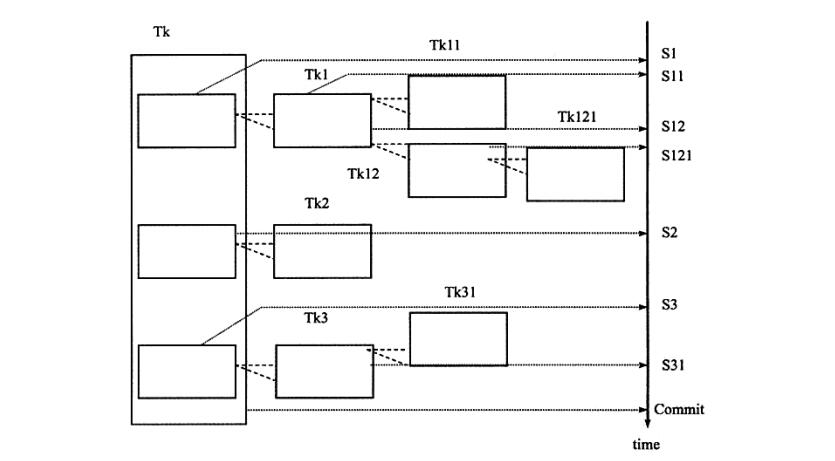
如图可以发现,在恢复时采用保存点技术比嵌套查询有更大的灵活性。例如在完成Tk3这事务时,可以会滚到保存点S2的状态。而在嵌套查询的层次结构中,这是不被允许的
但是用保存点技术来模拟嵌套事务在锁的持有方面还是与嵌套查询有些区别。当通过保存点技术来模拟嵌套事务时,用户无法选择哪些锁需要被子事务集成,哪些需要被父事务保留,这就是说,无论有多少个保存点,所有被锁住的队形都可以被得到和访问。而在嵌套查询中,不同的子事务在数据库对象上持有的锁是不同观点。例如一个父事务P1 其持有对象X和Y的排他锁,现在要开始调用子事务P11 ,那么父事务P1 可以不传递锁,也可以传递所有的锁,也可以只传递一个排他锁,如果子事务P11 中还持有对象Z的排他锁,那么通过反向继承(counter-inherited)父事务P1 将持有3个对象X Y Z的排他锁。如果这时再次调用一个子事务P12 ,那么它可以传递哪里已经持有的锁
然而,如果系统支持嵌套事务中并行地执行的各个子事务,在这种情况下,采用保存点的扁平事务来模拟嵌套事务就不切实际了。这从另一个方面反映出,想要实现事务间的并行性,需要真正支持的嵌套事务
分布式事务 通常是一个分布式环境下运行的扁平事务,因此需要根据数据所在位置访问网络中的不同节点
假如一个用户在ATM机上进行银行的转账操作,例如持卡人从招商银行存储卡转账10 000 元到工商银行的存储卡。这种情况下,可以将ATM机视为节点A,招商银行的后台数据库视为节点B,工商银行的后台数据库视为C,这个转账的操作可分解为以下的步骤
节点A发出转账命令
节点B执行存储卡中的余额减去10 000
节点C执行存储卡终端的余额增加10 000
节点A通知用户操作完成或者节点A通知用户操作失败
这里需要使用到分布式事务,因为节点A不能通过一台数据库就完成任务,其需要访问网络中两个节点的数据库,而在每个节点的数据库执行的实务操作有都是扁平的,对于分布式事务,其同样需要满足ACID特性,要么都发生,要么都失败。对于上述例子,如果2 3 步中任何一个操作失败,都会导致整个分布式事务回滚,若非这样,结果非常可怕
对于InnoDB存储引擎来说,其支持扁平事务,带保存点的事务,链事务,分布式事务。对于嵌套事务,其原生不支持。因此对有并发事务需求的用户来说,MySQL数据库或InnoDB存储引擎就显得无能为力,然而用户仍可以通过带保存点的事务来模拟串行的嵌套事务












|
|
|||













