Ganglia是一个分布式的监控工具,用来对Grid和Cluster上面的节点进行监控,利用它提供的web界面可以看到每个节点状态,并且可以输出图形化的表示。 Ganglia 是 UC Berkeley 发起的一个开源监视项目,设计用于测量数以千计的节点。每台计算机都运行一个收集和发送度量数据(如处理器速度、内存使用量等)的名为 gmond 的守护进程。它将从操作系统和指定主机中收集。接收所有度量数据的主机可以显示这些数据并且可以将这些数据的精简表单传递到层次结构中。正因为有这种层次结构模式,才使得 Ganglia 可以实现良好的扩展。gmond 带来的系统负载非常少,这使得它成为在集群中各台计算机上运行的一段代码,而不会影响用户性能。
名词说明
Metrics : 监控电脑的运行数据,这个词中文比较难翻译,英语中有度量的意思,下文我就不翻译,直接用原词。
Node : 一台电脑,或许拥有多个CPU,中文称之为节点。
Cluster : 一组节点,中文称之为簇。通常节点之间拥有达到G比特的高带宽,簇内通过组播协议,每个节点组播自己的数据,所以每个节点拥有整个簇的状态,这种冗余设计可以提高簇的鲁棒性。一般簇内节点为相同的系统和体系结构,由同一个管理员管理。
Grid : 一组簇,中文可称之为网格。网格的用处是在一个大范围内把各异构的簇通过宽带汇聚在一起。在文献3中,还有一个概念是Planetary-scale systems,也就是全球性的网络,一般部署于主干网的根节点。并且假定,网内的带宽不充裕,而且昂贵,经常有拥塞的情况出现。这是加州伯克利的一个GRID网络:http://monitor.millennium.berkeley.edu 你可以通过选择Grid或者Cluster来查看各类数据。
Ganglia的各种组成功能
gmond(Ganglia Monitor Daemon) :数据采集器的服务程序,配置文件是/etc/gmond.conf 位于每个Node上
gmetad(Ganglia Metadata Daemon):数据混合收集器的服务程序,配置文件是/etc/gmetad.conf。它通过轮询收集gmond的数据,并聚合簇的各类信息,然后保存在本地rrdtool的数据库中,最好每个cluster都有一个gmetad,以便能构建多级网络.
Web可视化工具:这是用PHP脚本实现的将数据可视化,并画出表格。可以是任何支持PHP、SSL和XML的web服务器。一般都用Apache2web服务器
额外的高级工具
gmetric可以用来添加你需要监控的Node额外状态;gstat可以直接获得Ganglia的数据,每台需要这些功能的Node上
ganglia功能示意图
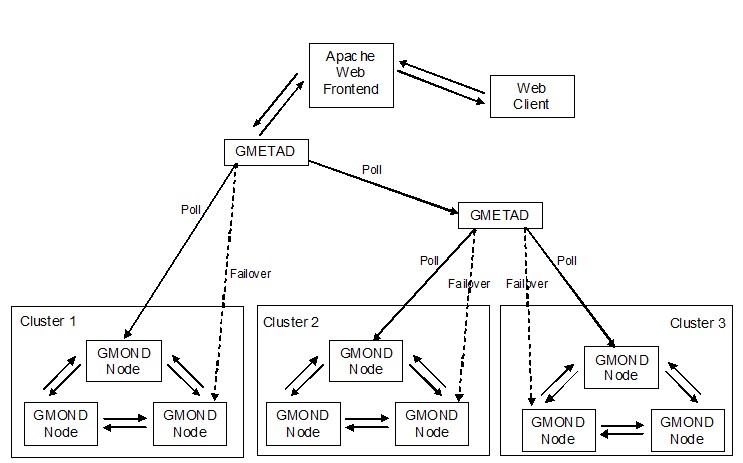
从图中可以看到,簇内通过UDP协议组播压缩的XML(XDR)数据,每个节点共享簇内所有节点的信息,当gmetad轮询簇内某个节点不成功时,也可以轮询其他节点。gmetad通过TCP协议发送簇内数据给上层gmetad节点。
gmond程序由多个线程组成:
collect and publish thread线程用于采集节点的metrics并组播出去;
listening thread线程用于监听组播端口,并把这些metrics保存于内存中的一个多级hash表;一组XML export threads线程组用于相应TCP请求,把簇内的metrics发送出去。
gmond不会保存数据,仅仅是监听保存并相应发送数据。节点间通过 heartbeat信号检测对方节点存活与否,如果一段时间内该节点没有广播metrics,我们视其宕机,而且每次启动时,会广播一个gmond启动时间,这时邻居节点收到以后就视其机器重启,会删除该节点已存的所有metrics。
gmetad周期性的向data source发送轮询包,并为每个源分配一个线程。采集的metrics,经由SAX XML进行解析,内置一个gperf的hash表,便于数据的处理,最后将处理好的数据存于RRDTools中。
metrics的组成
Metrics数据由gmond内置的程序或gmetric程序获得,一般以XDR(外部数据表示法(External Data Representation,缩写为XDR))形式压缩保存,保存格式为:(key,value),key为4 字节,value为4-8字节。metrics的采集次数、频率和发送时间间隔均在Gmond.conf中定义,gmond维持一个采集表,每个metric都有其属性。
一个多簇异构Ganglia网络的数据流
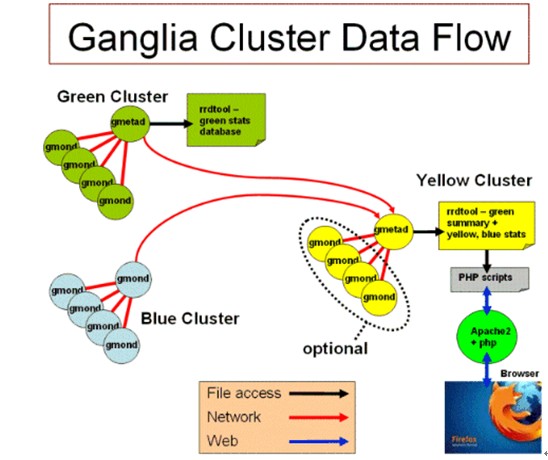
图中有四种簇:
黄色Cluster - 既有本地的Node,也提供前端显示的接口。它提供web服务器查看Ganglia的数据,其中不仅包含本地的Node(可选),也包括蓝色和绿色簇中的数据。
淡绿色Cluster - 前端web服务显示,一般没有本地节点。
蓝色Cluster - 这个簇中没有本地的数据收集器。所以这些节点将会共享所有数据(由于gmond是用多播来发送数据,所以实现共享比较容易),然后其中一个节点将数据发送给上层的数据收集器。黄色簇的gmetad服务收集并储存,如果没有保存,这些数据将会丢失。
深绿色Cluster - 这个簇中拥有本地数据收集器和仓库。绿色节点中也是共享数据,但是由一个簇头节点收集数据,并储存,在被询问时通过TCP发送给上层的黄色簇。
一般性的组网建议:
1、网络由许多深绿色节点和有本地节点的黄色簇组成
2、网络由许多蓝色节点和没有本地节点的黄色簇组成
各类簇的配置绿色簇的配置
针对gmond.conf 获得gmond默认配置
gmond -t >/etc/gmond.conf
gmond.conf修改如下:
/* This configuration is as close to 2.5.x default behavior. as possible
The values closely match ./gmond/metric.h definitions in 2.5.x */
globals {
daemonize = yes
setuid = yes
user = nobody
debug_level = 0
max_udp_msg_len = 1472
mute = no
deaf = no
host_dmax = 0 /*secs */
cleanup_threshold = 300 /*secs */
gexec = no
}
/* If a cluster attribute is specified, then all gmond hosts are wrapped inside
* of a tag. If you do not specify a cluster tag, then all will
* NOT be wrapped inside of a tag. */
cluster {
name = "green"
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
/* The host section describes attributes of the host, like the location */
host {
location = "unspecified"
}
/* Feel free to specify as many udp_send_channels as you like. Gmond
used to only support having a single channel. */
udp_send_channel {
mcast_join = green_header
port = 8649
}
/* You can specify as many udp_recv_channels as you like as well. */
udp_recv_channel {
port = 8649
family = inet4
}
...
对于mcast_join这个参数,green_header是簇头节点的主机名,你可以指定ip。
然后重启gmond服务。
簇头节点中/etc/gmetad.conf需要添加下面一行:
data_source "green" localhost
蓝色簇的配置
蓝色簇的配置与绿色簇类似,你只需要把簇的名字和簇头的名字设定好,然后重启所有节点的gmond服务。
黄色簇的配置
大部分配置与绿色簇类似,在/etc/gmetad.conf中需要加入以下几行:
data_source "yellow" localhost
data_source "blue" blue_header
data_source "green" green_header
这样gmetad就会:
1、联系本地gmond,获取所有黄色节点的状态数据。
2、联系blue_header节点的gmond,获取所有蓝色节点的状态数据。这些数据将会保存在本地的rrdtool数据库中。
3、联系green_header节点,获取在gmetad收集的rrdtools的整合数据。注意这些数据并不会保存在黄色簇中的rrdtools中,所以如果前端web服务器刷新时,会重新向green_header请求更新的的数据。
此外,在/etc/gmetad.conf ,也可以加入Grid的名称: gridname "Rainbow"
现在Ganglia的网页会显示一个叫Rainbow的网络,其中有三个簇:yellow,green和blue。
一些高级话题gmetric的使用
你可以添加固件:
gmetric --name firmware --value `lsattr -El sys0 -a modelname -F value` --type "string"
添加磁盘的数目:
gmetric --name number_of_disks --value `lspv | wc -l` --type int32
添加对某项数据的监控(其中name是现实的名字,value是由myget程序获取的,获取的数字类型是由type决定):
gmetric --name tpm --value `/usr/local/bin/myget` --type double
上面统计都只是一次,如果你需要长久的显示,最好是把上面的语句每60秒执行一次。然后,过几分钟以后,这些数据就会在网页上显示出来了。
对于gmetric的更多了解,你可以看http://ganglia.wiki.sourceforge.net/ganglia_readme 。
这里有一些自定义的gmetric脚本可以参考:http://ganglia.sourceforge.net/gmetric/
使用gstat获取数据,gstat可以通过命令直接显示数据,如:
[root@rac1 ~]# gstat
CLUSTER INFORMATION
Name: my_hadoop
Hosts: 3
Gexec Hosts: 0
Dead Hosts: 0
Localtime: Tue Feb 14 20:40:05 2012
There are no hosts running gexec at this time
[root@rac1 ~]#
你也可以通过加参数获取更多的信息:
[root@rac1 ~]# gstat --all --single_line
CLUSTER INFORMATION
Name: my_hadoop
Hosts: 3
Gexec Hosts: 0
Dead Hosts: 0
Localtime: Tue Feb 14 20:39:43 2012
CLUSTER HOSTS
Hostname LOAD CPU Gexec
CPUs (Procs/Total) [ 1, 5, 15min] [ User, Nice, System, Idle, Wio]
rac2 1 ( 0/ 481) [ 0.04, 0.14, 0.11] [ 2.3, 0.0, 0.4, 97.3, 0.1] OFF
rac3 1 ( 0/ 406) [ 0.07, 0.04, 0.01] [ 0.2, 0.0, 0.4, 99.4, 0.0] OFF
rac1 1 ( 0/ 777) [ 0.09, 0.43, 0.42] [ 2.7, 0.0, 0.9, 96.3, 0.0] OFF
 ganglia_1.JPG
ganglia_1.JPG