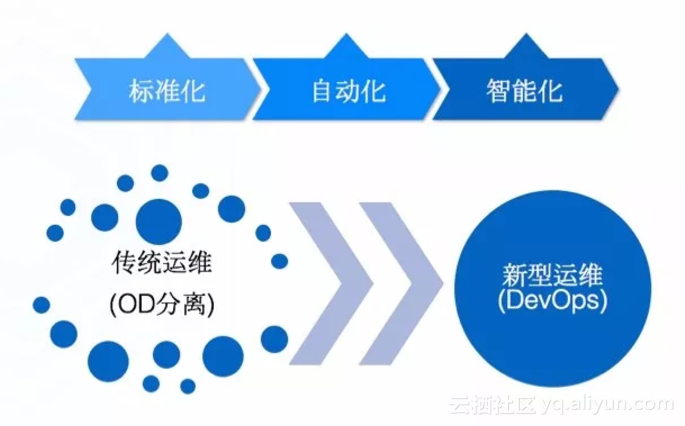
从传统运维OD分离转型到新型运维DevOps,不是简单把运维丢给开发就可以了,需要先把运维的工作工具化,实现开发可以利用工具自助完成,DevOps强依赖运维工具的支持。工具的落地也不是一蹴而就的,需要结合企业实际情况逐步建设,第一步先完成标准化,如Java类应用一套标准、PHP类应用一套标准,标准化之后才能使用工具自动化,智能化的核心是数据,自动化沉淀了数据才能做智能化,三步需要逐一实现。
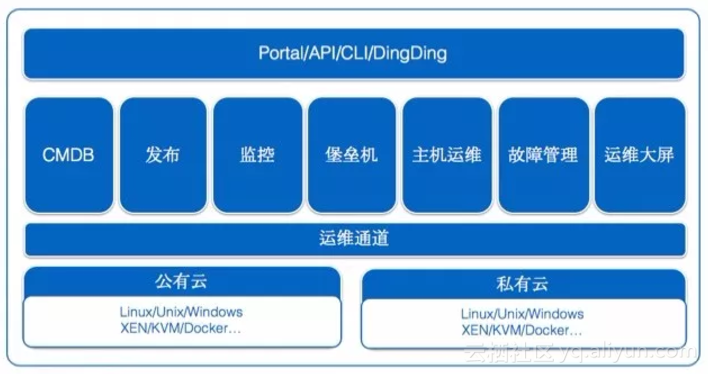
云效2.0涵盖项目协作域、研发域、测试域、运维域,为企业提供一站式研发协同服务。其中运维域由StarOps负责。StarOps定位一站式运维平台,资源、配置、部署、监控、运行,覆盖应用运维完整生命周期,具备基于混合云的应用运维无人值守解决方案以及自动化、数据化、智能化应用运维解决方案。阿里在运维领域沉淀多年的专家经验和能力全部集成于此,目标是通过平台使用户直接拥有运维专家的能力。
产品体系由八部分构成:CMDB、发布、监控、堡垒机、主机运维、故障管理、运维大屏、运维通道。不管公有云、专有云还是两者的混合云,通过运维通道屏蔽底层环境差异,实现上层应用运维统一管控。
运维通道
运维管控通道是服务器自动化运维的基础,所有操作最终都需要落地到服务器上执行,可以细分为三块:
- 命令通道:向服务器下发命令并执行,如ssh $ip $cmd
- 文件通道:把文件分发到服务器上,如scp/rsync/wget
- 数据通道:解决数据上行问题,如在脚本或命令执行完成后回调一个地址上报结果。
在服务器规模较小时,用上面提到的方法一般可以满足需求,不过随着规模的增涨,对安全、效率、稳定都会提出更严格的要求。用SSH通道时需要打通一台机器到所有服务器的认证,如果这台机器被黑客拿下向所有机器下发rm -rf,后果可想而知。
阿里自研的运维通道支持百万级规模服务器管控,支持二层/三层架构与容灾部署,1分钟可以操作50万台服务器,在内部每天有上亿次的调用,安全方面全链路加密签名、支持账号级别的命令映射,Agent经过淘宝、天猫、支付宝、阿里云等阿里生产环境业务真实验证,稳定性、安全性可以得到有效保证。运维通道与CMDB可以形成联动,实现数据的自动采集,保证CMDB数据的准确性与一致性。
CMDB是运维的元数据中心,拥有绝对权威性,一个公司只能有一份。保存的数据有两个特点:被大部分运维场景依赖、相对静态一次维护多次消费,在阿里内部实践中数据归为两大类:
CMDB
第一类:资源信息
传统资源有服务器、网络设备、IP段等,每种资源又有很多属性,如服务器的属性:SN、IP、主机名、OS、机房、机架、CPU、内存等,对于一台物理机而言SN、CPU、内存基本是永远不变的,OS可以随时重装,搬迁后机房信息也会变掉。使用云后资源类型又有OSS、RDS、SLB等,云资源的生产、销毁等管理操作也会集成进来。属性的变更应当通过外部系统或流程自动化触发,如OS信息应由装机系统维护更新、机房信息只能通过搬迁流程修改。
第二类:业务拓扑
也叫产品线,体现的是业务组织方式,例:BU/事业部->业务架构域->产品->应用,可以一级也可以多级,根据业务规模灵活调整。应用也有非常多的属性,像状态、等级、owner、开发负责人、运维负责人、代码库、开发语言等。多级时最上级一般与组织架构对应,增加子节点需要上一级审批。
CMDB保存着完整的资源与业务拓扑信息,通过资源与业务的关系,可以清晰了解各个业务使用的资源信息,资源属性信息再开放到其它系统消费,当拥有完善的基础信息后,基于场景的运维将会非常方便,例:
- 把服务器监控项配置在产品或应用上,新增服务器将默认拥有监控。
- 通过业务拓扑中的应用开发负责人判断谁有权限进行发布。
- 服务器默认为运维负责人授权,其它人登录需要运维审批。
发布
互联网时代产品迭代速度直接决定产品竞争力,最近有机会接触一些传统企业,运维几乎都是贴身为开发服务,发布按开发写好的文档一步一步操作,只是作为操作工毫无价值与成就感可言。
几年前在支付宝的时候发布也很痛苦,发布窗口提前几个月规划好,基本一个月一次,发布日当天一大早到公司,确认系统owner到位后开始发布,每个应用做完beta发布都要群里吼声,由owner确认后才能继续发,最怕发到一半出意外回滚,因为应用之间有先后依赖回滚就是整个链路,从早发到晚是常态,真心体力活。
从一月一次到一周一次,再到现在几乎开发随时想发就发(核心系统还是要控制发布节奏),发布系统与业务系统一起持续完善优化才有的今天,随时可以发使得业务需求可以快速上线,线上缺陷能够得到及时修复,有效提升交付效率。
发布模式有很多,如蓝绿发布、滚动发布、灰度发布等,这里不再对名词做解释,采用哪种模式与公司实际情况有直接关系,但不管哪种模式背后解决的问题都是不要出故障,即使有也要将影响控制在最小。
目前大部分发布工具解决的是把应用包发到线上的问题,不要出故障基本靠人为登机器查日志或者看监控。不过人工检查难免会遗漏,或者有时候过于自信觉得改动小肯定不会有问题,最终可能还是产生了故障。所以我们目前正在做无人值守发布。当一台机器发布完成后自动关联分析监控数据,包括基础监控(cpu/mem/load)、应用监控(jvm)、中间件监控、业务监控,如果检测到明显异常则直接拦截停止发布,在监控项足够完善、数据足够准确情况下无人值守发布完全可以做到人工零介入,提交代码自动测试、自动发布,相信这一天很快就会到来。
阿里的发布系统在内部能够支撑日均10万发布量,可灵活定义发布流程满足个性化部署需求, java、nodejs、python、php等多种技术栈的自动化发布我们都能够支持,通过无人值守、发布自愈等智能化发布部署能力保证代码变更安全,有效降低线上故障。
监控
监控作为线上运行的“眼睛”,能帮助业务快速发现问题、定位问题、分析问题、解决问题,为线上系统可用率提供有力保障,通过利用率数据的分析,帮助业务精准控制运维成本。
支付宝在2010年监控采用的开源软件nagios+cacti,随着业务的不断扩张服务器越来越多,监控项调度延迟越来越严重,调高检测频率、换最高配物理机、把多台nagios组成集群、对nagios深度调优等还是无法支撑业务的发展,加上开源软件对应用以及业务监控的缺失,所以最后不得不走上自研的道路。
阿里的监控规模早已达到千万量级的监控项,PB级的监控数据,亿级的报警通知,基于数据挖掘、机器学习等技术的智能化监控将会越来越重要。监控系统是一整套海量日志实时分析解决方案,以日志、REST 接口、Shell 脚本等作为数据采集来源,提供设备、应用、业务等各种视角的监控能力,利用文件传输、流式计算、分布式文件存储、数据可视化、数据建模等技术,提供实时、智能、可定制、多视角、全方位的监控体系。主要优势:
- 全方位实时监控:提供设备、应用、业务等各种视角的监控能力,关键指标秒级、普通指标分钟级,高可靠、高时效、低延迟。
- 灵活的报警规则:可根据业务特征、时间段、重要程度等维度设置报警规则,实现不误报、不漏报。
- 管理简单:分钟级万台设备的监控部署能力,故障自动恢复,集群可伸缩。
- 自定义便捷配置:丰富的自定义产品配置功能,便捷、高效的完成产品配置、报警配置。
- 可视化:丰富的可视化 Dashboard,帮助您定制个性化的监控大盘。
- 低资源占用:在完成大量监控数据可靠传输的同时,保证对宿主机的CPU、内存等资源极低占用率。
主机运维
服务器单机操作、批量操作、系统配置的管理,我们把服务器日常运维操作全部集中在此,功能包括:
- WEB终端:独创WEB终端可嵌入任何Portal,多种安全加密机制实现免SSH一键登录服务器,提升日常运维效率。
- 文件分发:月均10亿次分发量,服务稳定性99.9999%;具备断点续传、动态压缩、智能IO流控等超强能力;同时在容器镜像层级预热,超大文件分发,窄带、跨洋、远距离传输方面具备世界级竞争力。
- 定时任务:最小粒度支持秒级且支持随机,避免同一时间集中执行影响业务。支持按集群配置定时任务,新扩容服务器默认自动添加。
- 插件平台:统一管控服务器的通用运维脚本及Agent,支持自动安装、自动升级、进程守护。
堡垒机
堡垒机是进入生产环境的第一道屏障,阿里自主研发的专业级堡垒机系统,实现了集中访问控制、多因子验证、边界管控、操作实时记录、过程录屏、容灾容错、高危审计、命令阻断等功能,实现对人员操作过程的全面跟踪、控制、记录、回放;符合安全审计,合规,政审,认证等要求,广泛应用于阿里集团各业务生产管理(含阿里云、蚂蚁金服)。产品特点:
1. 专业级堡垒机,满足访问集中管控,运维操作命令记录、过程录屏,高危命令识别与拦截阻断等,满足对于生产网用户操作行为监测与审计需求。
2. 软件部署简单灵活,无硬件依赖,达5000人同时在线高承载,超强合规保障,符合美国上市企业SOX404审计要求和ISO27001信息安全认证要求。
IT变更与事件管理,与运维平台天然打通,监控异常事件可一键转工单跟进,主要功能:
- 事件:支撑客户、内部反馈线上业务异常,技术支持跟踪、处理、解决的流程支持和管理。
- 故障:线上故障进行记录、通报,并记录review内容及改进措施。
- 问题:故障Action或需要长期解决的问题跟踪,可以与评审流程联动。
综合CMDB、监控等数据,为企业提供定制可视化大屏服务,以大屏的方式在指挥中心展示业务运行状态,辅助指挥决策,大屏也是运维自动化效果展示的最佳窗口。
点击文末“阅读原文”,可了解更多“云效”信息。在日常工作中,你有哪些工具或方法,可减少重复劳动、提升效率?欢迎在留言区一起交流~
原文发布时间为:2017-12-13
本文作者:宋意


