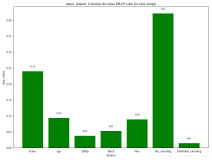
使用libsvm,首先需要将实际待分类的内容或数据(训练数据,或预测数据)进行量化,然后通过libsvm提供的功能实现分类和预测。下面介绍使用libsvm的基本步骤。
准备训练数据
数据格式:
1 |
<label1> <index1>:<value11> <index2>:<value12>... |
2 |
<label2> <index1>:<value21> <index2>:<value22>... |
3 |
<label3> <index1>:<value31> <index2>:<value32>... |
每一行,表示以已定义的类别标签,以及属于该标签的各个属性值,每个属性值以“属性索引编号:属性值”的格式。一行内容表示一个类别属性以及与该类别相关的各个属性的值。属性的值,一般可以表示为“该属性隶属于该类别的程度”,越大,表示该属性更能决定属性该类别。
上面的数据必须使用数字类型,例如类别,可以通过不同的整数来表示不同的类别。
准备的原始训练样本数据存放在文件raw_data.txt中,内容如下所示:
1 |
1 1:0.4599 2:0.8718 3:0.1987 |
2 |
2 1:0.9765 2:0.2398 3:0.3999 |
3 |
3 1:0.0988 2:0.2432 3:0.7633 |
归一化
这一步对应于libsvm的缩放操作,即将量化的数据缩放到某一范围之内。首先,需要把原始的训练数据存放到文件中作为输入,如果实际应用中不需要从文件输入,可以根据需要修改libsvm的代码,来满足需要。
上面准备的文件raw_data.txt定义了三个类别,分别为1,2,3,其中有三个属性。正常情况下,每个属性值范围可能并不一定是在0到1之间,比如实际的温度数据,销售额数据,等等。
libsvm通过使用svm_scale来实现归一化,下面是svm_scale的使用说明:
1 |
用法:svmscale [-l lower] [-u upper] [-y y_lower y_upper] [-s save_filename] [-r restore_filename] filename |
2 |
缺省值: lower = -1,upper = 1,没有对y进行缩放 |
3 |
-l:数据下限标记;lower:缩放后数据下限; |
4 |
-u:数据上限标记;upper:缩放后数据上限; |
5 |
-y:是否对目标值同时进行缩放;y_lower为下限值,y_upper为上限值;(回归需要对目标进行缩放,因此该参数可以设定为 –y -1 1 ) |
6 |
-s save_filename:表示将缩放的规则保存为文件save_filename; |
7 |
-r restore_filename:表示将缩放规则文件restore_filename载入后按此缩放; |
8 |
filename:待缩放的数据文件(要求满足前面所述的格式) |
我们输入如下参数,来执行数据的缩放操作:
1 |
-l 0 -u 1 -s src/s_rules.txt src/raw_data.txt |
数据缩放的区间为[0, 1],生成的缩放规则的文件存放到文件src/s_rules.txt中,最后面的文件src/raw_data.txt就是我们进行分类的训练数据文件。
输入上面参数执行后,可以看到归一化的数据,如下所示:
1 |
1.0 1:0.4114162014355702 2:1.0 |
2 |
2.0 1:1.0 3:0.3563584838823946 |
3 |
3.0 2:0.005379746835443016 3:1.0 |
使用Eclipse的话,控制台输出的就是上面的内容,也就是我们可以直接用来训练的训练数据,将其存为文件train.txt。执行svm_scale命令,还输出一个规则文件(src/s_rules.txt):
2 |
0.000000000000000 1.000000000000000 |
3 |
1 0.09880000000000000 0.9765000000000000 |
4 |
2 0.2398000000000000 0.8718000000000000 |
5 |
3 0.1987000000000000 0.7633000000000000 |
训练分类模型
训练分类模型的过程,就是够呢局前面归一化的样本数据,建立一个分类模型,然后根据这个分类模型就能够进行分类的预测,这也是最终的目的。
我们看一下libsvm提供的训练模型的命令:
01 |
用法: svmtrain [options] training_set_file [model_file] |
02 |
其中, options(操作参数):可用的选项即表示的涵义如下所示 |
03 |
-s svm类型:设置SVM 类型,默认值为0,可选类型有(对于回归只能选3或4): |
09 |
-t 核函数类型:设置核函数类型,默认值为2,可选类型有: |
11 |
1 -- 多项式核: (g*u'*v+ coef 0)deg ree |
12 |
2 -- RBF 核:e( u v 2) g - |
13 |
3 -- sigmoid 核:tanh(g*u'*v+ coef 0) |
14 |
-d degree:核函数中的degree设置,默认值为3; |
15 |
-g g :设置核函数中的g,默认值为1/k,其中k是指输入数据中的属性数; |
16 |
-r coef 0:设置核函数中的coef 0,默认值为0; |
17 |
-c cost:设置C- SVC、e - SVR、n - SVR中从惩罚系数C,默认值为1; |
18 |
-n n :设置n - SVC、one-class-SVM 与n - SVR 中参数n ,默认值0.5; |
19 |
-p e :设置n - SVR的损失函数中的e ,默认值为0.1; |
20 |
-m cachesize:设置cache内存大小,以MB为单位,默认值为40; |
21 |
-e e :设置终止准则中的可容忍偏差,默认值为0.001; |
22 |
-h shrinking:是否使用启发式,可选值为0 或1,默认值为1; |
23 |
-b 概率估计:是否计算SVC或SVR的概率估计,可选值0 或1,默认0; |
24 |
-wi weight:对各类样本的惩罚系数C加权,默认值为1; |
25 |
-v n:n折交叉验证模式,随机地将数据剖分为n部分并计算交叉检验准确度和均方根误差。 |
以上这些参数设置可以按照SVM的类型和核函数所支持的参数进行任意组合,如果设置的参数在函数或SVM 类型中没有也不会产生影响,程序不会接受该参数;如果应有的参数设置不正确,参数将采用默认值。
training_set_file是要进行训练的数据集;model_file是训练结束后产生的模型文件,该参数如果不设置将采用默认的文件名,也可以设置成自己惯用的文件名。
针对上面归一化操作得到的训练数据,我们通过输入如下参数并执行svmtrain命令进行训练:
1 |
src/train.txt src/model.txt |
输入出的src/model.txt就是分类模型,模型数据的内容,如下所示:
03 |
gamma 0.3333333333333333 |
10 |
1.0 1.0 1:0.4114162014355702 2:1.0 |
11 |
-1.0 1.0 1:1.0 3:0.3563584838823946 |
12 |
-1.0 -1.0 2:0.005379746835443016 3:1.0 |
根据得出的分类模型,就可以进行分类预测了。
有关训练分类模型的优化,从参考链接中引用一段,有兴趣可以实际操作一下:
本实验中的参数-s取3,-t取2(默认)还需确定的参数是-c,-g,-p。
另外,实验中所需调整的重要参数是-c 和 –g,-c和-g的调整除了自己根据经验试之外,还可以使用gridregression.py对这两个参数进行优化。
该优化过程需要用到Python(2.5),Gnuplot(4.2),gridregression.py(该文件需要修改路径)。然后在命令行下面运行:
python.exe gridregression.py -log2c -10,10,1 -log2g -10,10,1 -log2p -10,10,1 -s 3 –t 2 -v 5 -svmtrain E:/libsvm/libsvm-2.86/windows/svm-train.exe -gnuplot E:/libsvm/libsvm-2.86/gnuplot/bin/pgnuplot.exe E:/libsvm/libsvm-2.86/windows/train.txt > gridregression_feature.parameter
以上三个路径根据实际安装情况进行修改。
-log2c是给出参数c的范围和步长
-log2g是给出参数g的范围和步长
-log2p是给出参数p的范围和步长
上面三个参数可以用默认范围和步长。
-s选择SVM类型,也是只能选3或者4
-t是选择核函数
-v 10 将训练数据分成10份做交叉验证,默认为5
为了方便将gridregression.py是存放在python.exe安装目录下,trian.txt为训练数据,参数存放在gridregression_feature.parameter中,可以自己命名。
搜索结束后可以在gridregression_feature.parameter中最后一行看到最优参数。其中,最后一行的第一个参数即为-c,第二个为-g,第三个为-p,最后一个参数为均方误差。前三个参数可以直接用于模型的训练。然后,根据搜索得到的参数,重新训练,得到模型。
验证分类模型
预测分类的命令,说明如下所示:
1 |
用法:svmpredict [options] test_file model_file output_file |
3 |
-b probability_estimates:是否需要进行概率估计预测,可选值为0 或者1,默认值为0。 |
4 |
model_file 是由svmtrain 产生的模型文件; |
6 |
output_file 是svmpredict 的输出文件,表示预测的结果值。 |
这个命令有两个主要的作用:
- 一个是在得出分类模型后,对分类模型进行验证评估,来确定分类模型的准确性。这种情况下,到输入的验证数据实际上也是已经知道分类结果的,可以通过指定的方式进行选取,最终将模型的精度优化到能够接受的程度。
- 另一个是,使用经过验证后的模型,对实际中未知的数据进行分类,得到分类结果,这也是分类预测的最终目的和结果。
这里,只有通过一组已经知道类别的数据来做验证,才能知道分类器(基于分类模型数据)的精度如何。如果分类器精度脚底,完全可以进行额外的参数寻优来调整模型。
准备验证分类器的数据(已知类标签,存为文件test.txt),如下所示:
1 |
1 1:0.0599 2:0.2718 3:0.1987 |
2 |
3 1:0.6765 2:0.1398 3:0.6999 |
3 |
2 1:0.0988 2:0.9432 3:0.7633 |
上面的数据是和训练数据属于同一类型的,即已经知道类别,通过将其作为模拟的待预测数据来验证分类模型的准确度。
输入如下参数,进行模拟预测:
1 |
src/test.txt src/model.txt src/predict.txt |
结果会输出分类预测的精度:
1 |
Accuracy = 33.33333333333333% (1/3) (classification) |
使用Eclipse的话会直接输出到控制台。然后看一下预测的结果,保存在文件src/predict.txt中,内容如下所示:
可见,模型的精度不是很高,只有一个预测与实际分类相符。我们这里只是举个例子,数据又很少。实际分类过程中,如果出现这种精度特别低的情况,需要对分类模型进行调整,达到一个满意的分类精度。
预测分类
实际上预测分类的数据是类别未知的,我们通过训练得出的分类器要做的事情就是确定待预测数据的类别。使用libsvm默认是以文件的方式输入数据,而且预测要求的数据格式必须和训练时相同,所以数据文件中第一列的类标签可以是随便给出的,分类器会处理数据,得出类别,然后输出到指定的文件中。
预测分类和前面的“验证分类模型”中的执行过程是一样的。
如果有其他需要,可以适当修改libsvm程序,使其支持你想要的输入输出方式。