在近期的第七届数据技术嘉年华上,云和恩墨技术专家曾令军做了“RAC性能优化实战”为主题的演讲,分享了从硬件架构、系统与参数配置、应用设计以及工作负载管理这四个层面,剖析在RAC性能优化的过程中,应当注意的问题以及可以借鉴的经验和思路。我们再次分享出来,希望对各位有所指导借鉴。
RAC硬件架构
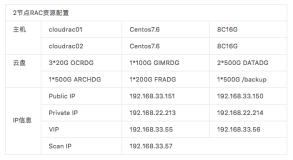
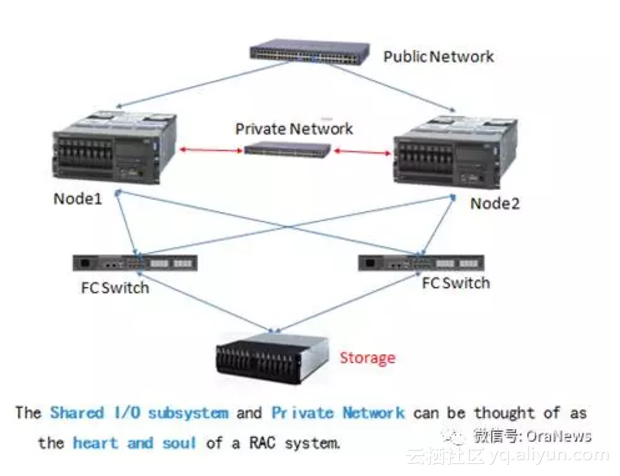
“千尺之台,始于垒土”,硬件架构是决定RAC环境运行性能最基础的部分。下面是一个比较简单的RAC架构拓扑图,一个存储、两台主机、三条网络,构成了一套RAC环境。
用户通过业务网发起一个查询请求,数据库会判断要请求的数据块在两个节点的内存(buffer cache)中是否存在,如果存在,这些数据块就通过私网复制传递到需要的节点上,如果没有,再从存储读取到内存。在这个过程中,私网负责数据块传递及锁控制方面的通信,而存储,除了要响应数据请求,还要负责保存数据和记录日志。所以,共享存储和私有网络被认为是RAC系统的核心和灵魂。
换句话说,如果这两部分组件的性能有问题,对RAC环境的影响也是最大的。
既然这两部分组件在RAC环境中如此重要,在做基础硬件选型及规划的时候,需要基于业务系统的规划要求,了解硬件环境是否能够满足业务的发展需要,把好性能优化的第一关。
在RAC环境中,存储层面最关注的指标包括I/O吞吐量、IOPS、I/O延时;而私有网络层面最关注的是带宽和网络延时。这里顺便介绍两个工具:Orion和Netperf,可以很好地满足这两部分组件的测试需求。
在规划重要系统的硬件架构时,需要考虑RAC环境的一些特殊要求,尤其是性能负载特别高的系统。以下是在RAC硬件架构层面的一些实践经验,供大家参考:
双公网、双私网、多存储链路。公网(业务网)建议每个主机使用两块网卡做网卡绑定;私网配置两块网卡,安装的时候都选上,集群就会为它们配置HAIP;存储要使用多条存储链路,并安装多路径软件。这样做的好处,一是消除单点故障,另外有些配置还能够起到负载均衡的作用。
私网建议使用万兆的带宽,使用单独的交换机万兆带宽是为了应对私网流量大的压力,减轻网络带宽出现瓶颈的问题。使用共享的交换机,一个是对于压力大的系统,带宽可能互相争用或限制,另外由于HAIP是虚拟地址,如果用VLAN,还可能可能遇到IP与网关地址冲突的问题。所以,重要系统的私网最好能使用单独交换机。
用ASM管理磁盘、磁盘组使用Normal冗余方案ASM技术在11G已经非常成熟,不但性能好,对于磁盘的管理维护也特别方便。如果有条件的话,建议使用normal的冗余方式,这样做的好处,一个是数据多一份备份,另外就是ASM有一些特性能够提升读写效率,例如11G的优先读取失败组,12C的均匀读取失败组。
磁盘太小的区间是100G到2T,同一个磁盘组的磁盘大小要相同磁盘大小相同有利于磁盘的容量管理和磁盘组中数据的rebalance性能,11G的数据库软件还不支持大于2T的磁盘。
数据文件与归档文件存放在不同的磁盘组中把不同的文件放在不同的磁盘组,可以起到I/O分流的作用,但这个设计不仅仅是出于读写性能的考虑,也是基于数据安全的考虑,如果数据和归档放在同一个磁盘组,万一这个磁盘组有问题,不但数据文件读不出来,使用备份恢复的时候,连归档日志也读不出来,那就会产生数据丢失的风险。
将Redo日志放在RAID1+0磁阵上,而不是raid5和SSD盘上关于这点最近刚好遇到一个案例,这套系统提交特别频繁,log file sync等待事件很严重。由于是性能测试阶段,所以针对性地做了很多测试,redo日志放在底层做raid5的存储盘上性能是最差的,而放在raid10上是最好的。因为提交特别频繁的系统,写redo日志都是小I/O操作,对存储的iops性能要求特别高。raid5的iops性能是最差的,ssd盘iops性能虽然很高,但是它的数据块擦写的方式,存在写峰值的问题。大多数情况下log write性能都很好,当峰值一出现,就会出现很多个用户会话并发等待lgwr写操作的完成,进而产生被成倍数放大的log file sync等待。所以我们建议对于性能要求特别高的联机业务系统,redo日志要放在普通的机械磁盘的raid10磁阵上。另外,这是一个存在争议的问题,可能某些高端全闪存存储上并不存在写峰值的问题,因此如果是特别重要、压力特别大的系统,测试过程是不可或缺的。
系统与参数配置
系统与参数配置分为三个层次(从底向上):操作系统配置、Grid和RDBMS软件配置、数据库参数配置。
操作系统配置
操作系统配置层面,有如下两点建议:
- 使用推荐的操作系统版本、安装补丁程序
- 配置系统参数、网络参数、异步IO参数、VMO参数、内存大页
在安装配置操作系统时,针对不同的操作系统,建议按照官方的指引文档进行配置,以减少遇到各种性能问题或BUG的风险。
Oracle Database (RDBMS) on Unix AIX,HP-UX, Linux, Mac OS X,Solaris,Tru64 Unix Operating Systems Installation and Configuration Requirements Quick Reference (8.0.5 to 11.2) (文档 ID 169706.1)
MOS上的这个配置指引文档,列举了各种操作系统平台上,安装数据库之前要注意的配置事项,有很高的参考价值。
下面通过两个案例说明配置合适的系统参数的重要性:
vmo -p -o minperm%=5 -o maxperm%=10 -o maxclient%=10 -o strict_maxclient=1 -o strict_maxperm=1 -o lru_file_repage=0 -o v_pinshm=1这是针对AIX系统VMO参数的一个配置,在AIX系统中,内存分为计算型内存和非计算型内存两部分,对于数据库服务器来说,主要使用的是计算型内存。而对于非计算型内存,在AIX中进程调用文件进入内存,即便该进程结束释放了所占用的内存,系统也并不立即将该使用过的内存段刷新为“fre”状态,而是将其标注为文件页no-comp的方式存放于内存中,如果应用程序重复调用到该文件就可以直接从内存中读取数据。但这样非计算型内存的使用量就会越来越高,空闲页越来越少,当计算型内存需要申请更多的内存空间时,就有可能出现因为内存刷新或分配导致严重的性能问题,甚至会出现节点驱逐。因此对于数据库服务器来说,建议将maxperm%这个参数设成一个较小的值,通常为20%以下,用来限制非计算型内存的最大使用量。
RHEL6.6:IPC Send timeout/node eviction etc with high packet reassbemles failure(DOC ID 2008933.1)
这个案例是由于操作系统参数配置不合理导致的一个BUG,从标题可以看出,问题是由于大量的包重组失败引起了节点驱逐。网卡之间传递数据时,会根据MTU(Maximum Transmission Unit)的尺寸,大的UDP数据包可能被分片,并在多个帧中发送。这些零散的数据包需要在接收节点上重新组合。分片的报文需要在指定时间内完成重组,已经收到但由于空间不足(例如reassembly buffer)没有进行重组的数据分片会被直接丢弃。
LINUX环境中存在两个参数:
net.ipv4.ipfrag_low_thresh:用于IP分片汇聚的最小内存用量
net.ipv4.ipfrag_high_thresh:用于IP分片汇聚的最大内存用量
这两个参数指定的内存空间,用于网络包的分片和重组,这部分内存空间一旦用尽,分片处理程序将丢弃网络包的分片,出现包重组失败的问题。在redhat6.6之前的版本中,这两个参数为最小值6M、最大值8M。而在redhat6.6版本中,这两个参数被改成了最小值3M、最大值4M,当私网流量较大时,很可能引起包重组失败率过高,而导致数据库层面的IPC通信超时。超时持续300秒,就会触发节点驱逐,这也是一个较为严重的问题。
操作系统作为RAC运行的基础软件环境,不管是操作系统版本还是操作系统的参数配置,对于数据库来说,都是至关重要的。因此,在做操作系统的使用规划和安装配置时,一方面要遵循官方的指导建议;另一方面也要广泛查阅相关的资料文档,避免遇到这些影响系统稳定运行的潜在风险。
操作系统配置
数据库软件配置层面,有如下三点建议:
升级数据库到稳定版本稳定的版本通常是小版本号比较高的版本,例如10.2.0.4、10.2.0.5、11.2.0.4
Grid和Rdbms软件保持相同的PSU版本grid软件的PSU可以比Rdbms软件更高,但建议让他们保持相同的版本上运行
保持PSU更新到较新的版本,并打one off patch通常oracle每个季度会发布一个PSU版本,这些PSU中包含了对于数据库稳定性或安全性影响较大的问题的修复补丁,打上这些PSU,就可以避免遇到这些问题。所以,对于特别重要的系统,要制定PSU的更新策略,另外,还需要关注PSU上最新的one off patch的更新信息。同样,通过一个案例来说明数据库软件及补丁更新的重要性。
11gR2/Aix - Dedicated Server Processes Have Large USLA Heap Segment Compared To Older Versions (文档 ID 1260095.1)
这个案例是在11.2.0.3上的一个BUG,在专有连接模式下出现的进程消耗内存量过多的问题。在专有连接模式下,数据库会为每个用户连接分配一个用户服务进程,正常情况这个进程初始的内存消耗量为3.5M左右,但遇到这个BUG时,每个进程初始的内存消耗量为10M左右。这样就会造成数据库服务器出现内存消耗过高的问题,而主机内存不足时,就会引发一系列的问题。解决这个问题办法就是打补丁或者升级数据库版本。这个例子也说明,有时候我们收到用户系统变慢的通知,在数据库中并不能发现什么性能问题,问题的真正原因很可能是由于主机层面的资源限制引起。
谈到PSU升级和打补丁的问题,不得不提到两个坑,希望能够给大家提供参考,少走一些弯路:
jar命令解压问题:
PSU的补丁包是.zip文件,在解压这些文件时,通常使用unzip命令。而在AIX环境中,unzip并不是默认配置在path路径中的,有时候为了偷懒,可能会想到做jar命令来进行解压。unzip和jar命令解压最大的区别在于文件的权限,使用unzip解压出来的文件与zip包中文件原有的权限是一致的,而使用jar命令解压出来的文件取决于环境变量umask的设置。所以默认情况下,jar命令解压出来的文件权限就是660,这意味着PSU补丁包中所有文件的可执行文件全部丢失。当打完PSU启动集群时,就会遇到集群无法启动的现象。
online patch的问题:
在很多online patch的Readme文件中,通常会有一个说明:该patch是可以在线应用的,但强烈建议在可停机维护的时间,将它打成普通的补丁模式(如果是online patch,在opatch lsinventory的结果列表中,会有“online”字样的标记)。在我们打补丁的时候往往会忽略这个说明,因为以前并没有遇到过如果没有这样做,会出现什么情况。而在前段时间处理的一个案例,就恰好命中了这个问题。现象是在变更时间段,数据库重启后,应用一连上来,即使这时并没有什么业务发生,服务器的CPU使用率接近100%。看上去是一个非常严重的性能问题,但后来在排查的过程中,无意中发现补丁列表中有一个online patch,把它回滚掉,然后再以普通的模式apply,CPU使用率又恢复正常。
数据库参数配置
在RAC环境中,有三个数据库参数是需要注意的:
parallel_force_local--建议设置为true,用于控制需要开并行守护进程的会话只能在该会话当前所在实例上开启并行守护进程。因为并行进程所操作的数据很可能非常接近,如果在多个实例同时运行,很可能产生大量的私网间的数据块传递和实例间资源争用。
gcs_server_processes--用于控制LMS进程的数量。在某些特殊环境中,RAC两个节点的CPU数量可能不一致,而CPU核数,决定了LMS进程初始化的数量,lms数量不一样在高负载时会产生严重的性能问题,在此种情况下,需要手工设置gcs_server_processes参数,使RAC数据库所有节点的lms进程数相同。
DRM(dynamic remastering)特性--建议关闭。在RAC环境中,数据块资源有一个主节点,为了提升本地节点的命中率,DRM特性可以动态调整数据块资源的主节点,哪个节点上对该资源请求的次数最多,就让它做了该数据块的主节点。但在调整主节点的过程中,有可能出现超时,使系统性能不稳定、严重的时候使数据库挂起。
read、deferred_segment_creation、delayed failed logins、undo_autot
另外,单实例数据库的参数优化在RAC环境同样适用。这里例举一些参数或特性:
parallel_max_server 、 adaptive_cursor_sharing、cardinality feedback、
serial direct pathune 、audit_trail 、adaptive_log_file_sync很多特性都是11G的新特性,但是遇到问题的也往往是这些新功能、自适应或自动调整功能。以密码延迟验证为例,做一个说明。密码延迟验证是为了防止密码暴力破解所做的一个应对措施,先看两个趋势图:
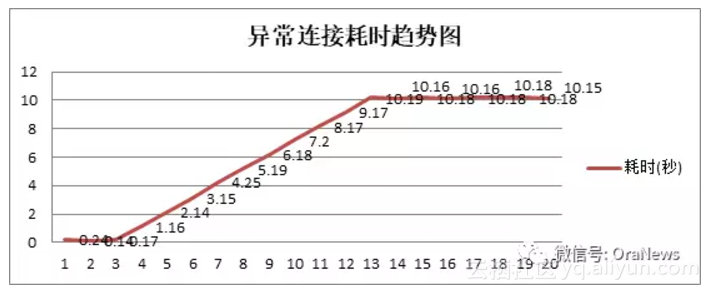
单个连接密码错误时数据库响应时间的变化:
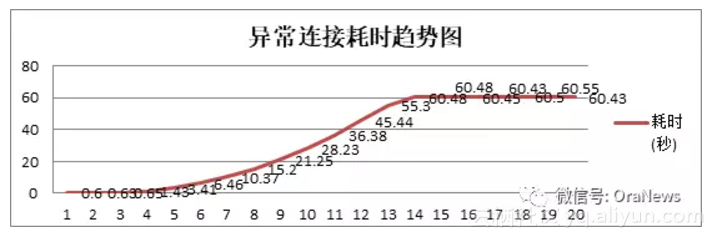
并发连接密码错误时数据库响应时间的变化
从上图可以看出,密码延时验证的功能,是当连续出现(超过三次)错误密码连接请求的时候,有规律地将密码验证返回的时间变长。
问题在于,由于这个响应时间变慢,如果错误密码请求发起的过于频繁,那么在数据库中就会出现两个问题:
- 数据库连接数快速累积,直到超出process最大数量,影响所有用户建立新连接;
- 数据库中出现大量的library cache lock等待事件,影响本用户的登录,即使密码是正确的。
应用设计
应用设计的问题在单实例数据库中会引发性能问题,而在RAC环境中,设计上的小问题造成的影响有可能会非常严重。
局部插入操作
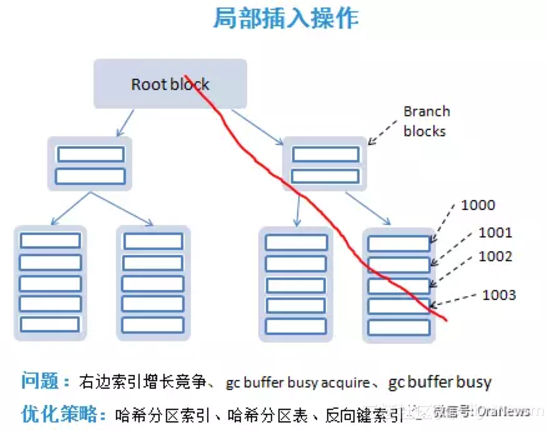
在非常多的应用系统中,会存在这样的设计:业务表中存在一个主键,例如id号,没有真正的业务含义,使用sequence插入序列值。主键是有索引的、序列是有序增长的。每次表中有数据插入时,序列都会产生一个最大值,并在索引的最右边的叶子块增加一行记录。同时,整个索引的最大值变化了,索引中分支块、根块都会同步更新。如果在RAC的两个节点中,发生在表上的插入会话并行量增多,最右边块的竞争就会急剧增加。由于要更新索引块中的数据,用户会话需要不断获取和释放全局缓存锁,而导致严重的gc buffer busy acquire和gc buffer busy等待事件。由于热点块总是发生在索引树的最右边,也把这个问题称为:右边索引增长竞争。
针对这个问题的优化策略有三种:
- 将索引建成哈希分区索引。通过哈希分区,一个索引会产生多个索引树,竞争被分散到多个索引分区的最右边。
- 将该数据表改造成哈希分区表,索引为本地分区索引
- 将索引建成反向键索引。列的值被反向存储在索引块中,索引的插入值被分散到不同的叶块上。
同时,要注意上述优化策略带来的负面影响,例如反向键索引不支持范围查询。
大量的truncate和drop
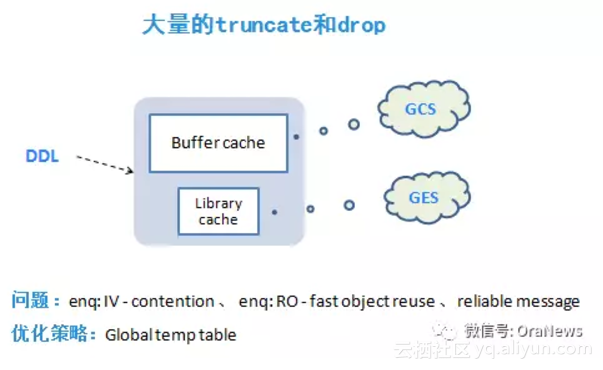
在某些业务系统中会有这样的设计,为了临时存放某些计算结果或查询结果,创建一个中间表,用完之后又把它truncate或drop掉。但开发设计人员没有意识到,这种创建和删除表的DDL操作,在RAC环境中,会触发多种等待队列,包括所有实例内存缓冲区的对象队列扫描(GCS)、触发检查点事件的等待、所有关联对象释放解析锁的等待(GES)。而在多数情况下,这些应用场景都是可以被oracle的全局临时表替代的,只是开发人员不具备这方面的知识。由于全局临时表基于会话独立,且会话结束后,数据即被丢弃,因此不再需要额外的DDL操作,从根本上避免了这类问题。
Sequence缓存
在RAC环境中,序列的值被缓存在所有实例中,序列缓存的默认值是20,对于繁忙的系统来说,这个缓存值是不够的,当产生序列请求等待的时候,在数据库中往往会出现row cache lock等待事件。同样的道理,当应用设计人员将序列的属性改成“order、nocache”时,被频繁访问的序列会产生很大的性能影响。每次访问序列都要更新seq$表,如果很多会话同时要求访问序列,那么行缓存锁等待就会变得非常严重。
因此,对于sequence的使用要注意:
- 如果序列的并发访问量较高,且业务层面没有不跳号、不断号的需求,则可以为该序列设置一个较大的缓存值,例如1000以上。
- 如果序列一定要order、nocache,则可以考虑是否根据业务逻辑将这个序列拆分为多个序列,减少竞争。
当然还有很多的应用设计问题会造成RAC性能缓慢,例如:应用系统提交过于频繁、系统中存在大事务长事务、存在大表的全表扫描、过多的并行操作、索引设计不合理等等,在此不一一说明。
工作负载管理
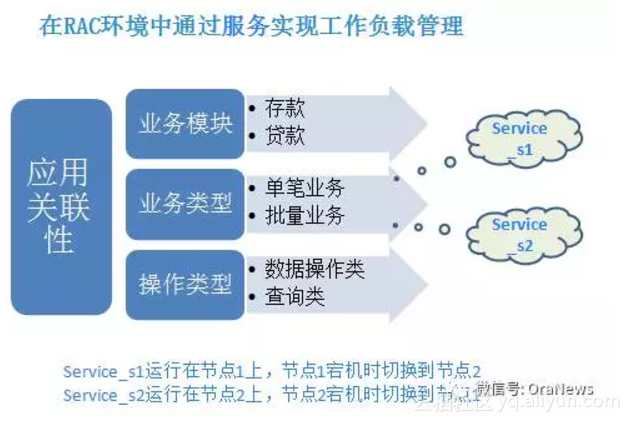
分析应用关联性,实现业务分割,在RAC性能优化中也是一种觉见的手段,而且往往是非常有效的手段。借助于数据库的服务管理,应用程序的工作负载可以被关联、分配。上图中以银行业务的垂直分割为例,希望能为大家提供思路上的参考。早期的银行核心业务系统,集合了存款业务和贷款业务,而这两种业务的耦合度非常低,它们使用不同的业务表,完全具备分割的基础。那么,我们可以在数据库层面创建两个服务,service1用于存款业务的连接配置,service2用于贷款业务的连接配置。在服务的创建过程中,指定TAP的参数配置,例如service1以节点1为主用节点,以节点2为备用节点。正常情况下,service1只在节点1上运行,当节点1发生故障的时候,该服务会自动切换到节点2继续接收用户请求。在完成业务分割,最大限度地减少实例间数据传递和争用的同时,又充分利用了RAC环境的高可用性。
构建一套性能优越的ORACLE RAC数据库是一门艺术,而在RAC环境中遇到性能问题,不断地调整优化,更需要多方面的专业知识和精心设计。
原文发布时间为:2017-11-29
本文作者:曾令军