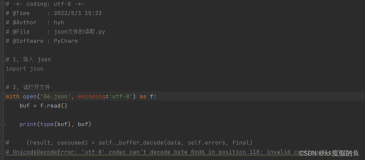
无意间翻看之间的代码,发现了一段难以理解的代码。

byte[] bs = digest.digest(origin.getBytes(Charset.forName(charsetName))) ;
for (int i = 0; i < bs.length; i++) {
int c = bs[i] & 0xFF ;
if(c < 16){
sb.append("0");
}
sb.append(Integer.toHexString(c)) ;
}
return sb.toString() ;
bs是由一段字符串经过MD5加密后,输出的byte数组。我起初难以理解为什么在接下来的循环中要将bs[i]&oxFF再复制给int类型呢?
bs[i]是8位二进制,0xFF转化成8位二进制就是11111111,那么bs[i]&0xFF不是还是bs[i]本身吗?有意思吗?
后来我又写了一个demo
package jvmProject;
public class Test {
public static void main(String[] args) {
byte[] a = new byte[10];
a[0]= -127;
System.out.println(a[0]);
int c = a[0]&0xff;
System.out.println(c);
}
}
我先打印a[0],在打印a[0]&0xff后的值,本来我想结果应该都是-127.
但是结果真的是出人意料啊!
-127
129
到底是为什么呢?&0xff反而不对了。
楼主真的是不懂啊,后来往补码那个方向想了想。
记得在学计算机原理的时候,了解到计算机内的存储都是利用二进制的补码进行存储的。
复习一下,原码反码补码这三个概念
对于正数(00000001)原码来说,首位表示符号位,反码 补码都是本身
对于负数(100000001)原码来说,反码是对原码除了符号位之外作取反运算即(111111110),补码是对反码作+1运算即(111111111)
概念就这么简单。
当将-127赋值给a[0]时候,a[0]作为一个byte类型,其计算机存储的补码是10000001(8位)。
将a[0] 作为int类型向控制台输出的时候,jvm作了一个补位的处理,因为int类型是32位所以补位后的补码就是1111111111111111111111111 10000001(32位),这个32位二进制补码表示的也是-127.
发现没有,虽然byte->int计算机背后存储的二进制补码由10000001(8位)转化成了1111111111111111111111111 10000001(32位)很显然这两个补码表示的十进制数字依然是相同的。
但是我做byte->int的转化 所有时候都只是为了保持 十进制的一致性吗?
不一定吧?好比我们拿到的文件流转成byte数组,难道我们关心的是byte数组的十进制的值是多少吗?我们关心的是其背后二进制存储的补码吧
所以大家应该能猜到为什么byte类型的数字要&0xff再赋值给int类型,其本质原因就是想保持二进制补码的一致性。
当byte要转化为int的时候,高的24位必然会补1,这样,其二进制补码其实已经不一致了,&0xff可以将高的24位置为0,低8位保持原样。这样做的目的就是为了保证二进制数据的一致性。
当然拉,保证了二进制数据性的同时,如果二进制被当作byte和int来解读,其10进制的值必然是不同的,因为符号位位置已经发生了变化。
象例2中,int c = a[0]&0xff; a[0]&0xff=1111111111111111111111111 10000001&11111111=000000000000000000000000 10000001 ,这个值算一下就是129,
所以c的输出的值就是129。有人问为什么上面的式子中a[0]不是8位而是32位,因为当系统检测到byte可能会转化成int或者说byte经过一些运算后会转化成int时,就会将byte的内存空间高位补1扩充到32位,再参与运算。
其实是从数字类型扩展到较宽的类型时,补零扩展还是补符号位扩展。
这是因为Java中只有有符号数,当byte扩展到short, int时,即正数都一样,因为为符号位是0,所以无论如何都是补零扩展;但负数补零扩展和按符号位扩展结果完全不同。
补符号数,原数值不变。
补零时,相当于把有符号数看成无符号数,比如-127 = 0x81,看成无符号数就是129, 256 + (- 127)
对于有符号数,从小扩展大时,需要用&0xff这样方式来确保是按补零扩展。
而从大向小处理,符号位自动无效,所以不用处理。
让我理解更深了,也就是说在byte向int扩展的时候,自动转型是按符号位扩展的,这样子能保证十进制的数值不会变化,而&0xff是补0扩展的,这样子能保证二进制存储的一致性,但是十进制数值已经发生变化了。也就是说按符号位扩展能保证十进制数值不变,补0扩展能保证二进制存储不会变。而正数可以说是既按符号位扩展,又是补0扩展,所以在二进制存储和十进制数值上都能保证一致。
http://www.cnblogs.com/think-in-java/p/5527389.html