原文 http://www.cnblogs.com/codealone/archive/2013/04/23/3037780.html
背景
上篇说到我们可以将自己的博客内随笔/文章/日记备份得到的xml 转换成CHM文档,如果我们希望将某个大牛的博客随笔全部导出,这个能不能实现呢?写在这里算是废话了,既然有了这篇博客,那么这个问题,一定是可以解决的。
资源下载
示例文档截图(路过秋天):
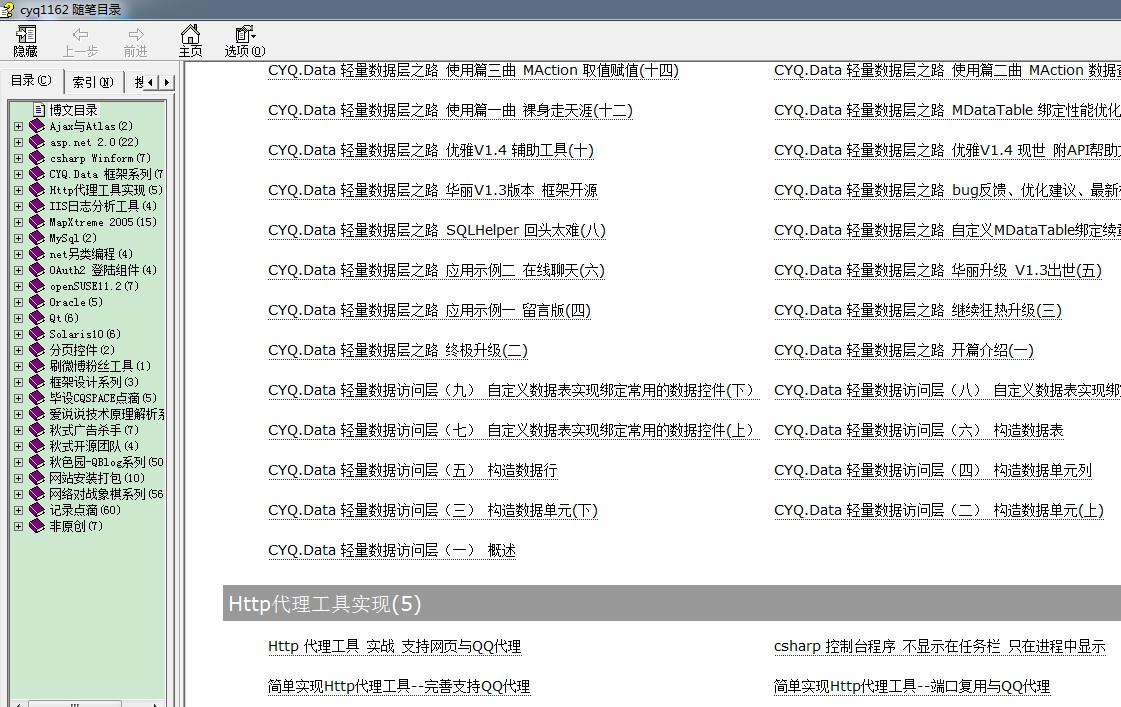
开发思路
1.根据博客园ID得到随笔类别,如地址为 http://www.cnblogs.com/cyq1162/,则博客园ID为cyq1162,请求页面http://www.cnblogs.com/cyq1162/mvc/blog/sidecolumn.aspx。请求结果如下:
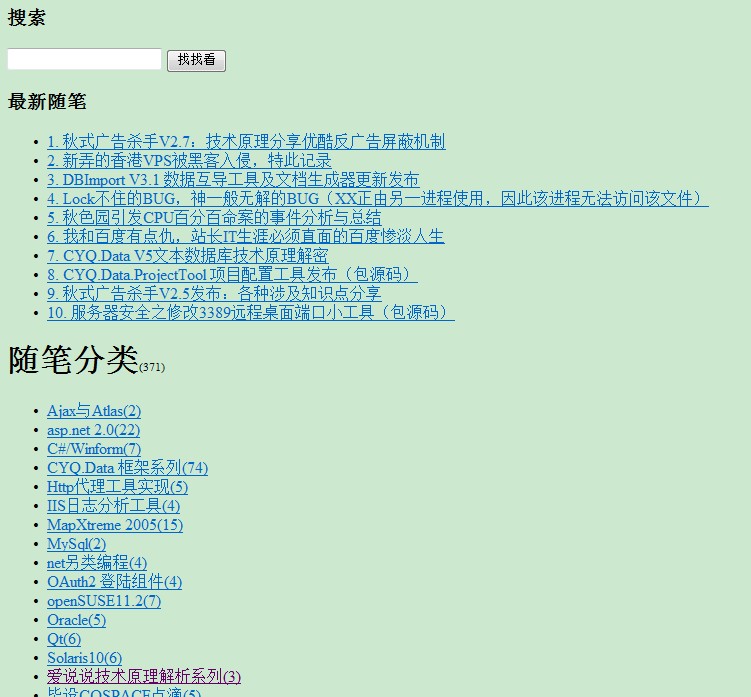
通过正则匹配到该页面的链接,以某个链接为例,http://www.cnblogs.com/cyq1162/category/268820.html,其中包含cyq1162/category,基于这样的规则,我们可以得到所有的随笔分类链接。
2.得到随笔分类链接之后,则请求该链接的内容,得到该随笔下的所有文章链接。文章链接,以某个链接为例,http://www.cnblogs.com/cyq1162/archive/2013/03/17/2964746.html,其中包含cyq1162/archive,基于这样的规则,我们可以得到所有的文章链接。
3.得到文章的链接,这样就能得到文章正文。我们要获取的有文章标题、文章正文、发布时间。这里没有去尝试获取文章作者,不好获取。前面指的需要获取的3个内容,在某个明确id的节点里。这里使用了HtmlAgilityPack进行HTML解析,感觉非常方便,可以直接根据ID得到元素,然后获取它的内容。解析代码如下:

//下载随笔内容 替换后保存本地 var contentCode = GetContent(articleUrl);//获取随笔内容 HtmlDocument htmlCode = new HtmlDocument(); htmlCode.LoadHtml(contentCode); var titleNode = htmlCode.GetElementbyId("cb_post_title_url"); var postBody = htmlCode.GetElementbyId("cnblogs_post_body"); var postDate = htmlCode.GetElementbyId("post-date"); //var topics = htmlCode.GetElementbyId("topics"); var localHtml = template .Replace("{channelTitle}", titleNode.InnerText)//博文标题 .Replace("{preContent}", DownImage(postBody.InnerHtml))//博文内容 .Replace("{channelHref}", titleNode.GetAttributeValue("href", "#"))//博文地址 .Replace("{channelLink}", userId + ".cnblogs.com")//博客地址 .Replace("{channelAuthor}", userId);//博文作者
4.下一步则是编译CHM了,这里就不重复介绍了。
其中参考啊汉的博文 《一键构造你的博客目录》 构造了随笔目录。
代码逻辑就这么多,比较简单,希望大伙喜欢。如果设置首页不显示随笔分类的话,是无法采集的,若是博客引用了自定义样式,需要手动添加该样式在。有其他的问题,可以向我反馈,也可以自己下载代码调试看看。