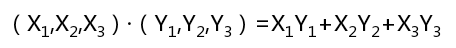这篇文章我想谈下SQL Server里一个非常重要的性能调优话题:重编译(Recompilations) 。当你执行非常简单的存储过程(使用临时表)时,就会发生。今天我想奠定SQL Server里重编译的基础,它们为什么会发生,下篇文章我会向你展示通过不同方式重写你的存储过程避免重编译。
什么是重编译?
在我谈SQL Server里重编译细节前,首先来看看下面一个很简单存储过程。
1 CREATE PROCEDURE DemonstrateTempTableRecompiles 2 AS 3 BEGIN 4 CREATE TABLE #TempTable 5 ( 6 ID INT IDENTITY(1, 1) PRIMARY KEY, 7 FirstName CHAR(4000), 8 LastName CHAR(4000) 9 ) 10 11 INSERT INTO #TempTable (FirstName, LastName) 12 SELECT TOP 1000 name, name FROM master.dbo.syscolumns 13 14 SELECT * FROM #TempTable 15 16 DROP TABLE #TempTable 17 END 18 GO
从代码里可以看出,这个存储过程并没有什么特殊。第1步我们创建临时表,然后临时表里会插入一些记录,最后用简单的SELECT语句获取插入的数据。在SQL Server里,像这样的代码你可能谢了上百次,甚至上千次。
接下来我们用SQL Server Profiler跟踪下重编译事件。点击【工具】->【SQL Server Profiler】。输入登录密码后,会弹出【跟踪属性】窗口。点击【事件选择】,勾选【显示所有事件】,然后在事件列表里勾选【Stored Procedures】下列事件:
- SP:Starting
- SP:StmtStarting
- SP:Recompile
- SP:Completed
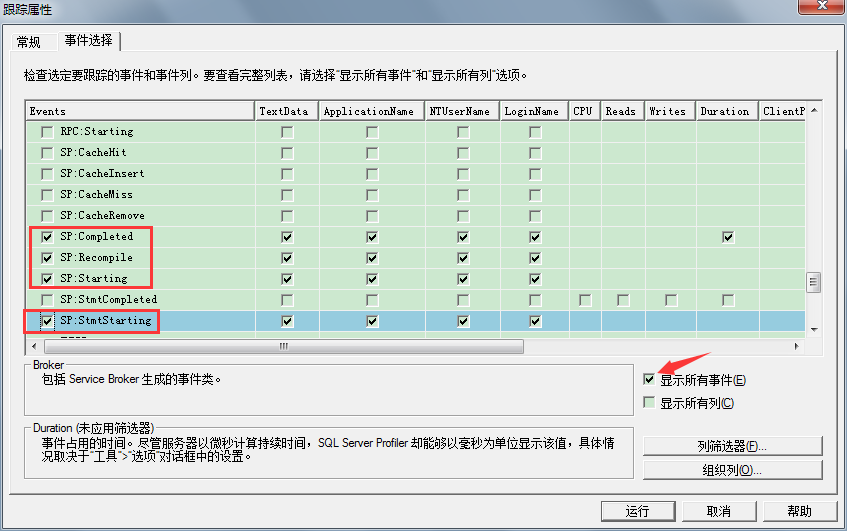
点击【运行】开始跟踪。在我们创建存储过程后,我们运行存储过程。
1 EXEC DemonstrateTempTableRecompiles

从上图可以看到,我们在执行存储过程时,发生了2次重编译。
重编译意味这SQL Server在运行执行计划时,对执行计划进行了重编译。这会带来额外的CPU开销,最后减少服务器工作的吞吐量。但现在的问题是,为什么这些重编译会发生?
SQL Server执行重编译主要是在下列2种情况发生:
- 架构改变(Scheme Shanges)
- 统计信息更新(Statistic Updates)
在刚才执行的存储过程里,因为这2个情况我们触发了重编译。我们再来看下刚才的存储过程,第1步我们建立了临时表,当我们在TempDb里建立临时表时,你就改变了你的数据库架构,因为这个原因第1个重编译发生了。
在临时表创建后,你插入了一些记录。因此SQL Server需要去更新临时表聚集索引的统计信息——聚集索引是由SQL Server通过主键(PRIMARY KEY)创建。1个简单的存储过程就引起了SQL Server里2个重编译。哇噢~~~~~
小结
重编译会给临时表带来巨大的性能负荷。另一方面,临时表有准确的统计信息帮助查询优化器生成更好性能的执行计划。因此,当你处理大量数据时,使用临时表才是正确选择。对于小量数据,重编译引起的CPU负荷,比通过统计信息获得性能提升的CPU负荷会高很多。
下篇文章,我会为你介绍表变量(Table Variables),我们会看到使用表变量如何避免重编译的副作用——还有它们带来的其它性能问题。请继续关注!
附:SQL Server 2014的童鞋可以使用下列脚本通过扩展事件(Extended Event)跟踪重编译事件。
1 CREATE EVENT SESSION [TrackRecompiles] ON SERVER 2 ADD EVENT sqlserver.sql_statement_recompile 3 ( 4 ACTION 5 ( 6 sqlserver.plan_handle, 7 sqlserver.sql_text 8 ) 9 ) 10 ADD TARGET package0.event_file(SET filename = N'c:\temp\TrackRecompiles.xel') 11 WITH 12 ( 13 MAX_MEMORY = 4096 KB, 14 EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS, 15 MAX_DISPATCH_LATENCY = 30 SECONDS, 16 MAX_EVENT_SIZE = 0 KB, 17 MEMORY_PARTITION_MODE = NONE, 18 TRACK_CAUSALITY = OFF, 19 STARTUP_STATE = OFF 20 ) 21 GO 22 23 -- Start the Event Session 24 ALTER EVENT SESSION TrackRecompiles 25 ON SERVER 26 STATE = START 27 GO