最新在一个项目中要求用到微软SSAS中的数据挖掘功能,虽然以前做项目的时候也经常用到SSAS中的多维数据集 (就是CUBE),但是始终没有对SSAS中的数据挖掘功能进行过了解。所以借着项目需求这股东风最近了解了下SSAS的数据挖掘,这里先写一篇博客做一个简要的归纳。
说到数据挖掘,我们首先需要知道SSAS数据挖掘能干什么,为什么需要进行数据挖掘。我们先来看一个例子假设我们数据库中现在有一张表叫CustomersBoughtCarsSurvey,这张表记录了公司客户购买车辆的信息。
CREATE TABLE [dbo].[CustomersBoughtCarsSurvey]( [CustomerID] [int] IDENTITY(1,1) NOT NULL,--主键ID为自增int类型 [Name] [nvarchar](50) NULL,--客户姓名 [Age] [int] NULL,--客户年龄 [Sex] [char](1) NULL,--客户性别 [Nation] [nvarchar](50) NULL,--客户所在国家 [City] [nvarchar](50) NULL,--客户所在城市 [YearlySalary] [float] NULL,--客户年收入 [BoughtCar] [bit] NULL,--客户是否购买了汽车 CONSTRAINT [PK_CustomersBoughtCarsSurvey] PRIMARY KEY CLUSTERED ( [CustomerID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY]
现在这张表里面假如有10000行记录,其中这10000记录中[CustomerID],[Name],[Age],[Sex],[Nation],[City],[YearlySalary]这几列都是有值的,唯独列[BoughtCar]只有4000行数据有记录其余6000行都是null值,原因是在表CustomersBoughtCarsSurvey里面有4000个客户做过了市场调查,所以知道了他们是否购买了汽车,所以这4000个客户在列[BoughtCar]上是有值的,但是有6000个客户还没有做市场调查,所以有6000行数据的[BoughtCar]列都是null。现在我们要做的事情就是通过一个算法来预测这6000个客户中哪些人在未来是有可能买车的?买车的几率有多大?
那么围绕上面这个问题,我们来观察表CustomersBoughtCarsSurvey的结构,我们可以发现其实客户是否购买汽车可能取决于[Age],[Sex],[Nation],[City],[YearlySalary]这几列的值,比如年龄很小的人不大可能会买车,男性买车的可能性比女性更大(只是举个例子没有其它意思。。。),年收入高的人可能比年收入低的人更有可能买车等。那么简单来说就是我们现在需要找到一个算法,根据表CustomersBoughtCarsSurvey中每一行[Age],[Sex],[Nation],[City],[YearlySalary]这几列的值来推断列[BoughtCar]的值是1还是0,如果是1出现的概率是高还是低?如果推断出来的某个结果是1而且概率大于80%那么该客户买车的可能性就是极高的,对于公司来说应该重点关注该客户。
所以现在我们的问题就变成了我们需要一个函数逻辑,根据列[Age],[Sex],[Nation],[City],[YearlySalary]的值来推断出列[BoughtCar]的结果,用一个数学公式来表达就是
[BoughtCar]=Function([Age],[Sex],[Nation],[City],[YearlySalary])
而在SSAS中的数据挖掘模型就能够将上面这个公式付诸于实现,上面公式中的Function就是一个函数逻辑,这函数逻辑在SSAS中就是数据挖掘的九大模型算法:
- Microsoft 决策树分析算法
- Microsoft 聚类分析算法
- Microsoft Naive Bayes 算法
- Microsoft 时序算法
- Microsoft 关联规则分析算法
- Microsoft 顺序分析和聚类分析算法
- Microsoft 神经网络分析算法
- Microsoft 线性回归分析算法
- Microsoft 逻辑回归分析算法
这九大模型有位博主做了详细的介绍,我也正在学习之中,这里推荐下:大数据时代:深入浅出微软数据挖掘算法系列。
选定了上面九大模型的某一个挖掘模型,那么下一步要做的就是对挖掘模型进行数据训练,来提高挖掘模型对数据预测的准确性,通俗来说数据训练就是让上面公式中Function函数的逻辑更佳正确,能够更精准的得出公式等号左边[BoughtCar]的值。在本文的例子中我们前面说过表CustomersBoughtCarsSurvey中有4000行数据的列[BoughtCar]是有值的,这4000行数据就是参加做过市场调研的客户,我们要通过这4000行数据来做数据训练,提高数据挖掘模型算法的精度,然后来预测剩下6000行数据中列[BoughtCar]的值。
数据训练的过程大致是这样的,将训练数据分为两部分,第一部分的数据拿出来寻找规律得出一个算法,然后根据这个算法去计算另一部分数据的值,然后和真实值进行比较,得出算法的准确性如何。在我们的例子中就是将表CustomersBoughtCarsSurvey中4000行[BoughtCar]有值的数据拿出来做数据训练,将4000行中30%的数据作为第一部分数据拿来做逻辑分析得出算法,然后将得出的算法去计算4000行数据中剩下70%数据的[BoughtCar]的值,然后和真实值进行比较,得出准确率,如果准确率可以接受我们的挖掘模型就构造完成了,我们可以将表CustomersBoughtCarsSurvey中那6000行[BoughtCar]没有值的数据通过挖掘模型去得出[BoughtCar]的值。如果准确率太低无法接受,那说明4000行数据去做数据训练还是不够,需要公司市场调研部去调研更多客户准备更多[BoughtCar]列有值的数据去做数据训练,或者从九大模型中选择其它的挖掘模型看预测的准确率是否能够提高。这个过程可以用下面这张图来表示。

了解了数据训练的概念之后,我们来看看怎么在SSAS中怎么建立数据挖掘结构和挖掘模型,在SSAS中数据挖掘结构是挖掘模型的容器,挖掘结构定义了挖掘模型要用到哪些数据列,一个挖掘结构可以包含多个挖掘模型。下图演示了如何在SSAS中建立挖掘结构。

建立挖掘结构的时候可以顺便建立一个挖掘模型,下图中我们在建立挖掘结构的同时建了一个决策树算法的挖掘模型。

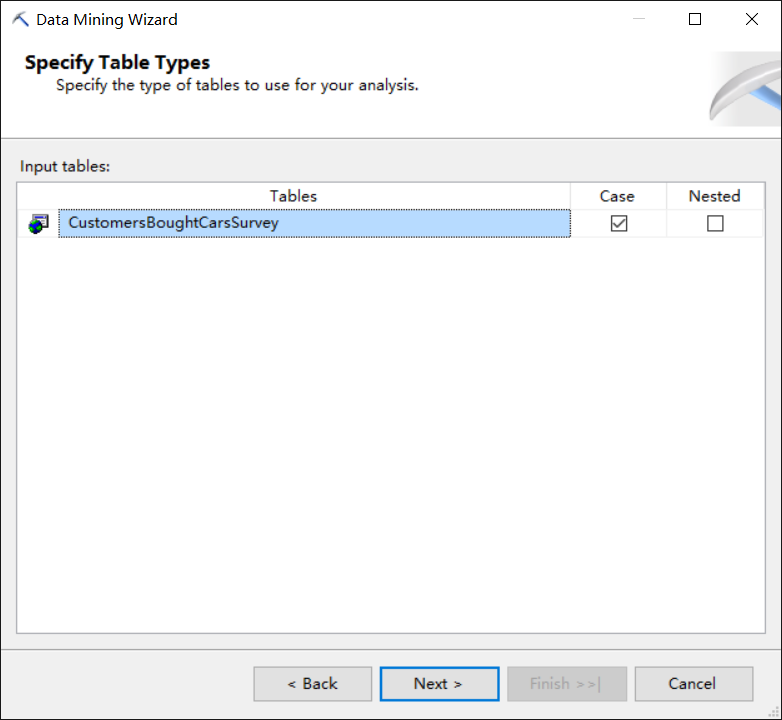
然后我们要选择的是挖掘结构要用到哪些表,一个挖掘结构要选择一张事例表(下图中case列),如果一张事例表的列无法满足挖掘结构的需求,还可以选择若干个和事例表相关联的表作为嵌套表(下图中Nested列)。本例中我们就只选择了一张事例表CustomersBoughtCarsSurvey。
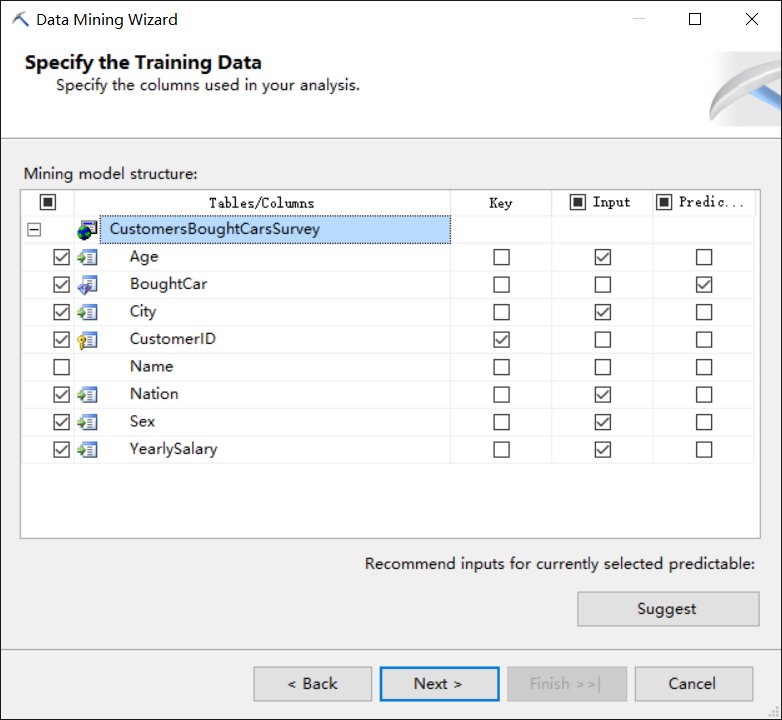
接着我们要为刚才选择的决策树模型定义输入列和预测列,在挖掘模型中至少要选择一列作为键值列,键值列唯一标示挖掘模型中的一行数据就像数据库表中的主键一样,本例中我们的键值列是CustomerID(下图中Key列)。然后输入列相当于就是我们前面提到公式中函数Function的参数,所以我们选择了[Age],[Sex],[Nation],[City],[YearlySalary]作为输入列(下图中Input列),预测列就是我们上面公式中等号左边的返回值,所以我们选择了列BoughtCar作为预测列(下图中Predictable列)。当然一个列既可以是输入列,也可以是预测列,这样的情况就相当于是一个数据需要传入一个函数进行数据加工后作为返回值,所以这种情况数据既是输入列又是预测列。
然后我们要选择需要用多少数据来做算法分析,就相当于在前面数据训练部分中提到的需要拿一部分数据得出挖掘模型的算法,前面我们提到了在4000行[BoughtCar]列有值的数据中的30%来得出挖掘模型算法,所以下图中我们配置了测试数据比例为30%(30%也是默认值)。

最后我们为定义的挖掘结构和挖掘模型起一个名字,整个定义过就结束了。

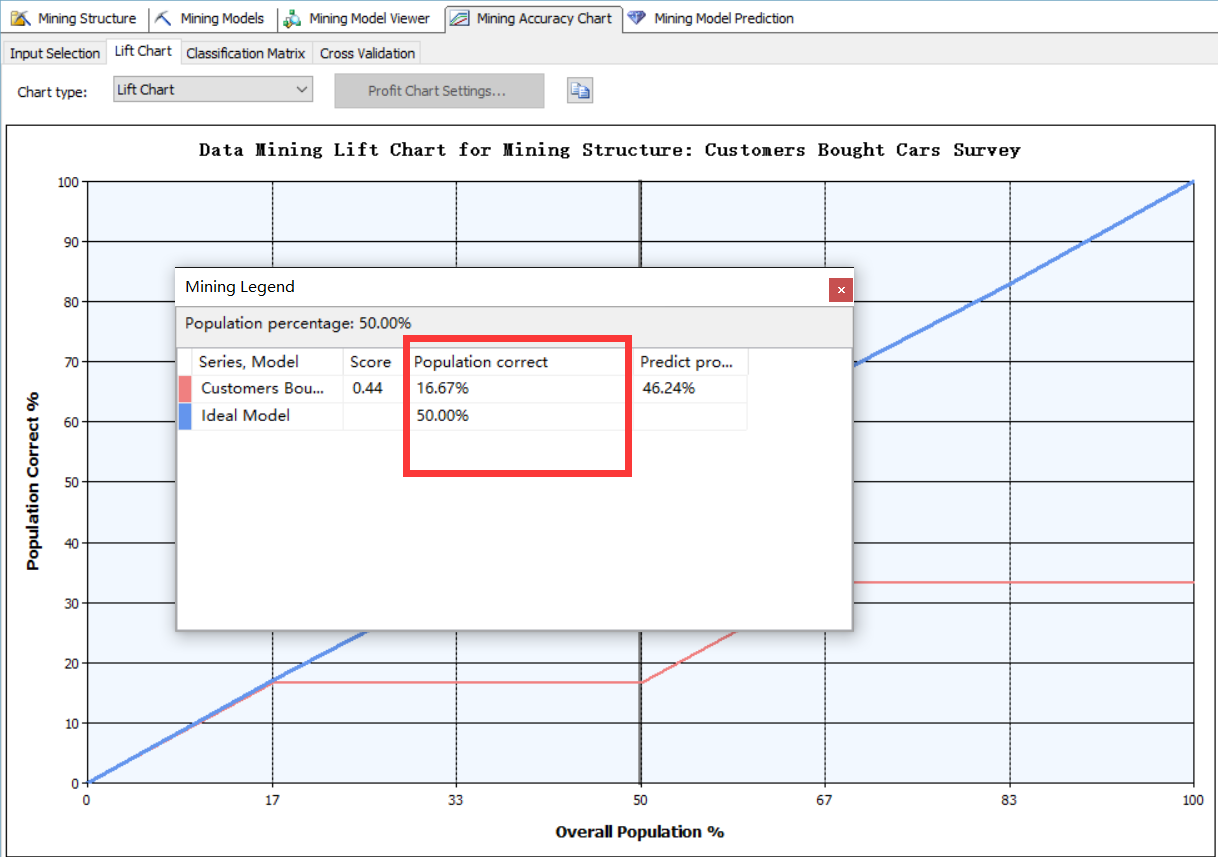
建立好挖掘结构后我们可以将其部署到SSAS服务器上,然后查看当前挖掘模型的算法的准确率,下图中我们本例建立的挖掘模型的准确率只有16.67%非常低,一个重要的原因就是我们用于数据训练的数据量太少了。增加数据训练的数据量后这个数字会有明显改善。
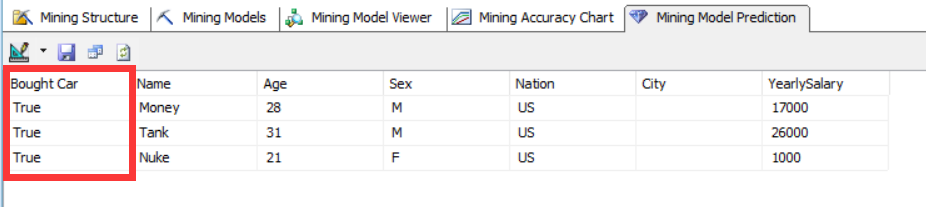
最后我们可以在建立的挖掘模型上调用DMX语句做数据预测,下图中我们使用图形化设计器来构造数据预测查询,左边的结构是挖掘模型列,右边的表结构表示的是我们要预测的数据行(相当于是我们本文前面提到的6000行[BoughtCar]列无值的数据行)。中间的连线表示的是挖掘模型的输入列和预测数据结构列的映射关系,通过这个映射关系可以将预测数据的数据列传入挖掘模型的输入列得出预测列的值,我们可以手动编辑这个映射关系。
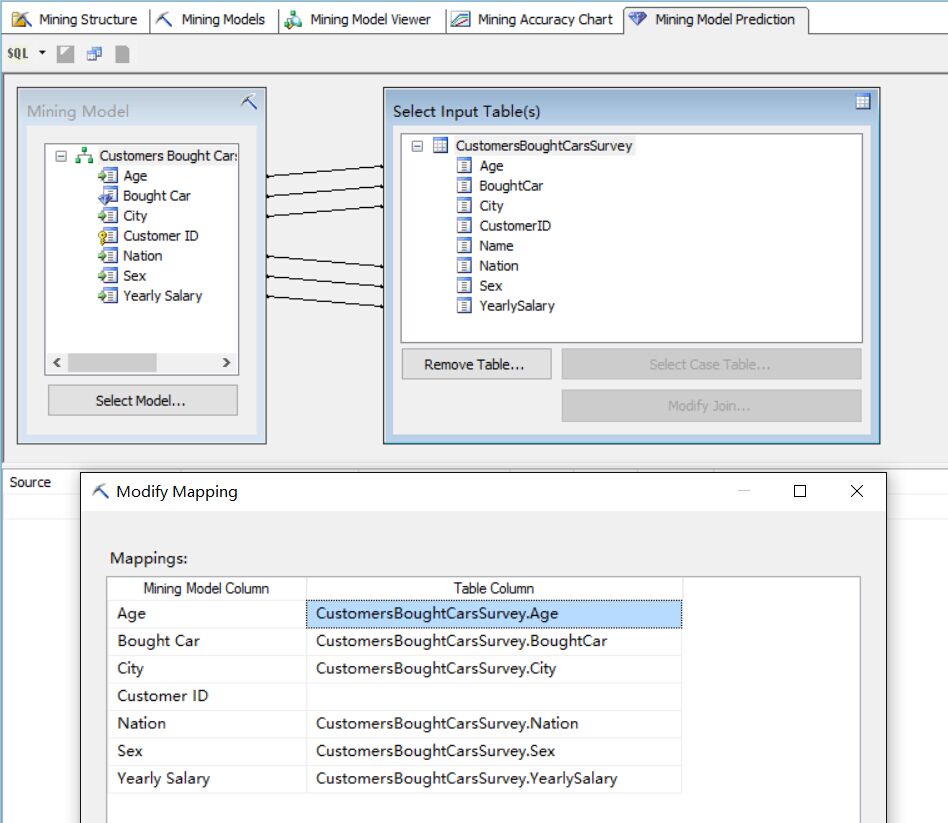
当然我们也可以不使用设计器自己手动写DMX语句做查询
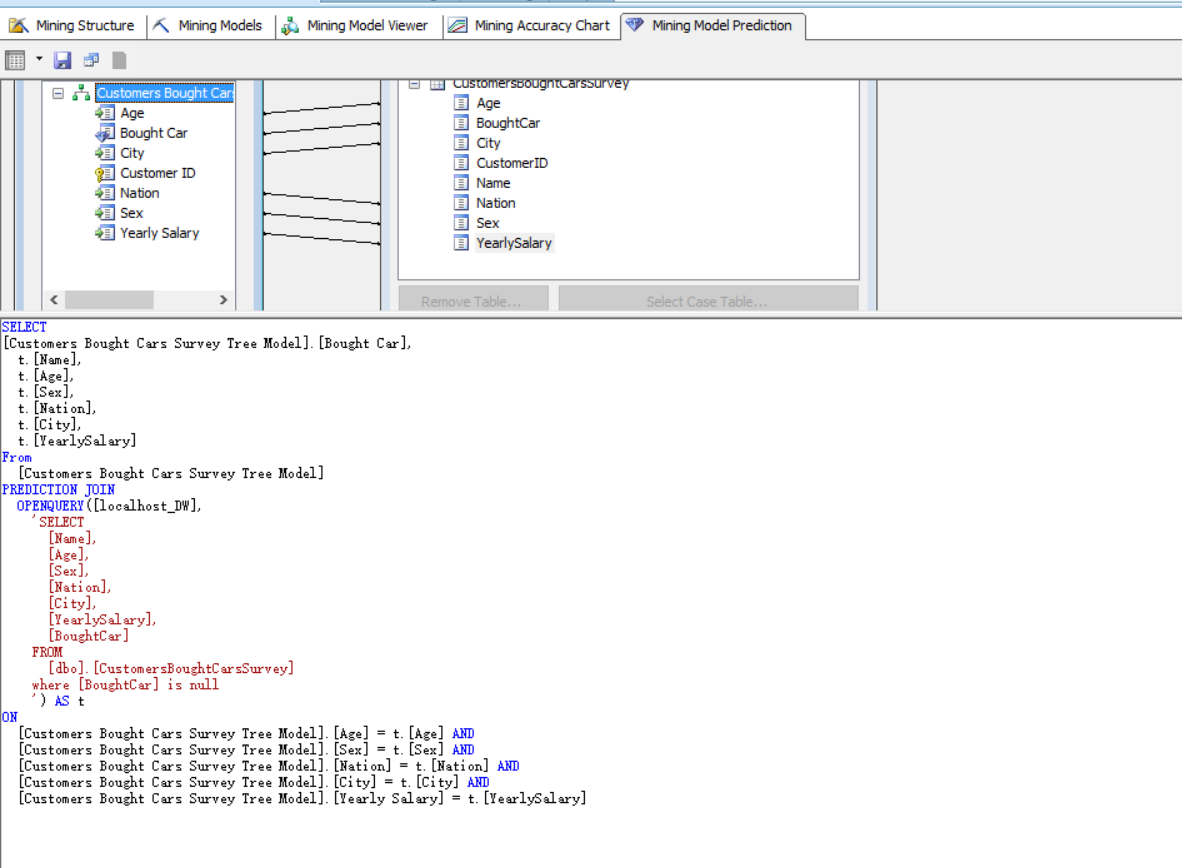
最后我们可以通过查询得到三行列[Bought Car]值本来为null的数据行,通过挖掘模型计算出来预测值: