在优化器进行查询转换的时候,如果将内嵌视图里推入连接谓词,视图里的结果集会更小,优化器就有可能会选择Nested Loops Join 与 Index Range Scan 的方式加快数据的显示。但如果内嵌视图中存在GROUP BY,此时会发生什么情况?在10g和11g里面,Oracle的处理方式有哪些不同?
问题分析
为了解答以上问题,首先需要对SQL的基本语法与查询转换(QueryTransformation)的概念与原理有一定了解。
Oracle优化器可以分为下面两种:
Logical Optimizer:是对用户编写的SQL使其转换成让优化器更容易理解的方式的过程。也叫查询转换(QueryTransformation)。Physical Optimizer:对经过Logical Optimizer 转换的SQL,计算成本(Cost),评估并选择最优成本的执行计划的过程。也叫查询优化(Query Optimization)。
基于预估行数或成本选择最优的执行计划的技术,即物理优化器(PhysicalOptimizer) 相关的技术介绍有很多。比如,选择索引还是选择全表扫描、选择Nested Loops Join 还是选择Hash Join 等等都属于这个范畴。使用提示(Hint)改变执行计划也属于这个范畴。但是,相对于查询转换(Query Transformation)相关技术的介绍,与其重要度相比相关技术的介绍就比较少。今天要说明的就是查询转换相关的问题。
这次的问题是内嵌视图中存在GROUP BY时,连接条件谓词无法推入到内嵌视图里。(该问题只是在Oracle 10g里的限制,Oracle 11g已经不存在此问题。)客户正好使用的是10g系统,通过此次问题的分析,可以掌握查询转换问题的基本思路与方法。
测试环境
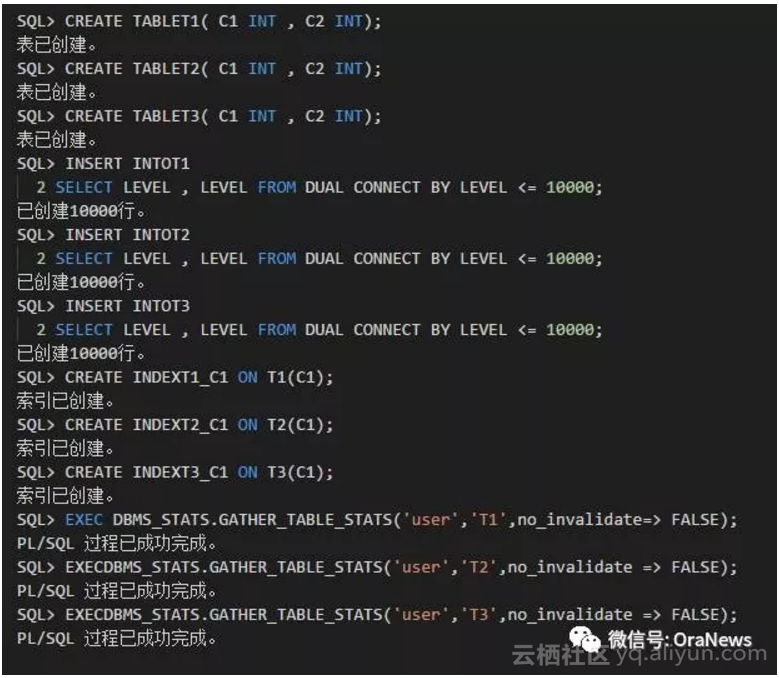
生成如下表 T1、T2、T3,并插入数据,每个表插入10,000行数据。之后,分别对3个表创建第一个字段C1列的单列索引。最后,收集统计信息。
案列1:GROUP BY 与 Join Predicate Pushing
Oracle 版本是 10.2.0.1的情况。
下面我们看一下内嵌视图里存在GROUPBY时,连接条件谓词无法推入的情况。
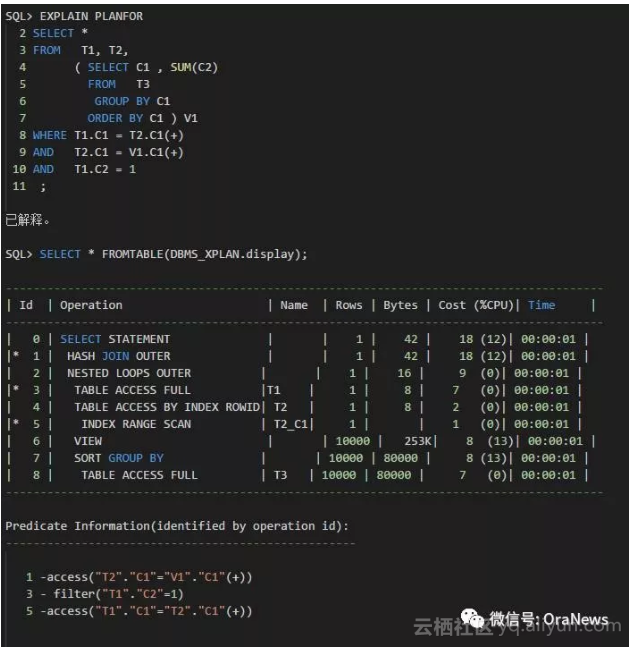
以上执行计划分析如下:
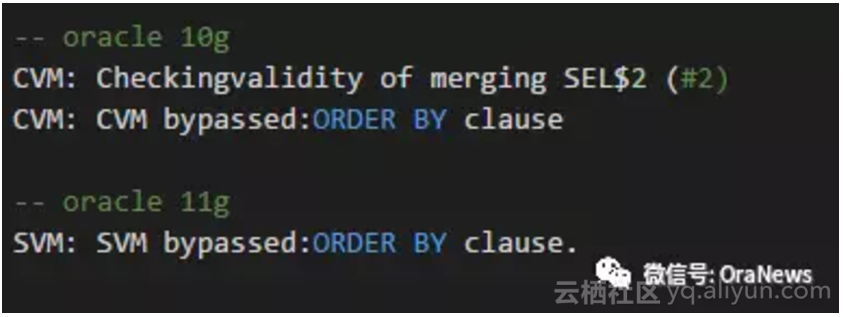
- ID:6,从这里可以看到优化器进行视图合并(View Merge)失败,这是因为内嵌视图里存在ORDER BY的缘故。
- 连接谓词"T1"."C2"=1,没有进入到内嵌视图内部,即谓词推入失败。优化器把V1视图看成完全独立的查询块(Query Block)。
- 所以,内嵌视图内部对表T3进行了Full Table Scan,以及对其结果进行Hash Join。
优化器进行视图合并失败时,首先会尝试进行连接条件谓词推入(JoinPredicate Pushing)。上面的SQL文本里可以看到,T1、T2、V1之间存在连接,且存在"T1"."C2"=1,所以满足谓词推入的条件。如果,根据条件"T1"."C2"=1能过滤出很少的结果集,那么谓词推入的效果是相当明显,进一步就可以选择Nest Loops Join ,从而可以用最少的资源得到想要的结果集。
是什么原因导致了谓词推入失败?
下面我们看下在Oracle 11g的情况。
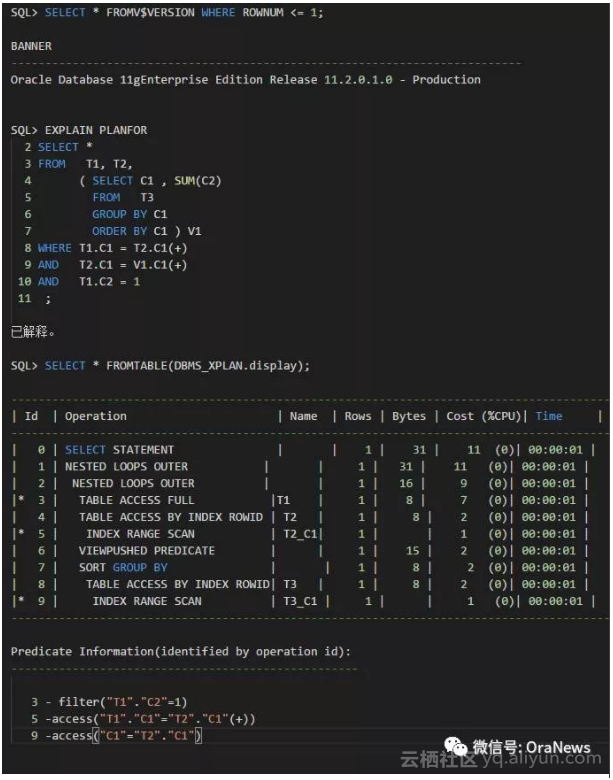
可以看到,执行计划完全改变:
- ID:6,可以看到VIEW PUSHED PREDICAT,说明优化器进行视图合并(View Merge)失败。
- 但是,从VIEW PUSHED PREDICAT字面可以理解,连接条件谓词推入成功。
- ID:9的Predicate Information 里可以看到access("C1"="T2"."C1"),这也进一步说明外面的条件已经进入到视图内部。
- 所以,因谓词推入的缘故,对表T3出现了INDEX RANGE SCAN,以及对T3的结果集的处理外部选择了NESTED LOOPS JOIN。
这个是因为Oracle 版本的升级解决了老版本优化器的一些限制的典型案例。这种新功能增加往往会带来隐含参数的增加。此处也不例外,请记住这个隐含参数_optimizer_extend_jppd_view_types。如下,可以看到这个隐含参数。
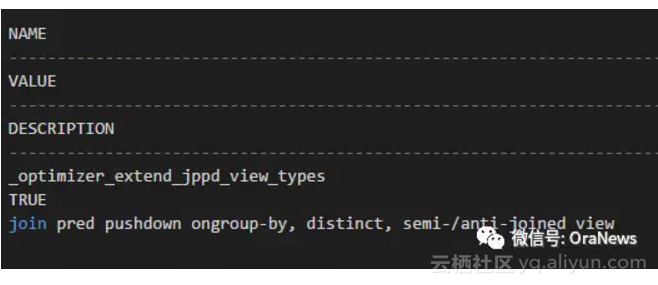
我们可以利用提示(Hint)关闭这个参数,看看会产生什么结果。
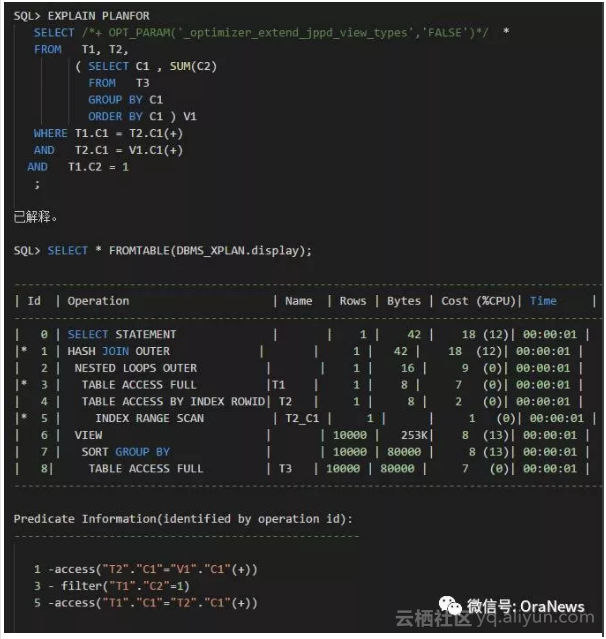
可以看到,关闭相应隐含参数的时候,执行计划回到了Oracle 10g时候的样子,即没有进行连接条件的谓词推入。
可以亲眼确认查询转换过程的方法是使用10053的事件。通过10053事件我们推测一下在Oracle10g和Oracle11g里区别是什么。
首先,可以通过Legend了解到产生了哪种查询转换。
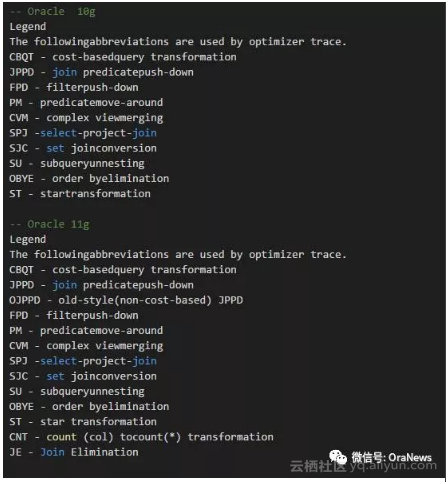
可以看到,Oracle 11g里比Oracle 10g 使用了更多的查询转换。Oracle每次的版本更新都会带来查询转换领域的不断更新。
内嵌视图的查询块(SEL$2)里存在ORDER BY语句,所以视图合并失败。这个是两个版本都相同的地方。但是,有趣的是使用的方式不同,Oracle 10g里使用了CVM(Complex ViewMerge),Oracle11g里使用的是SVM(Simple Viewer Merge),说明因版本的升级Oracle里视图合并的基准改变了。
下面的信息可以明确的看到,Oracle 10g里尝试把主查询块(SEL$1)里存在的连接谓词(Join Predicate)推入到内嵌视图的查询块(SEL$2)里,但是因为GROUP BY 语句失败了。

但是,从下面信息中可以看到,在Oracle 11g里连接谓词推入(Join Predicate Push)成功了。这时,通过CBQT(Cost Based Query Transformation)即基于代价的查询转换计算成本(Cost Based),之后判断是否使用连接谓词推入。
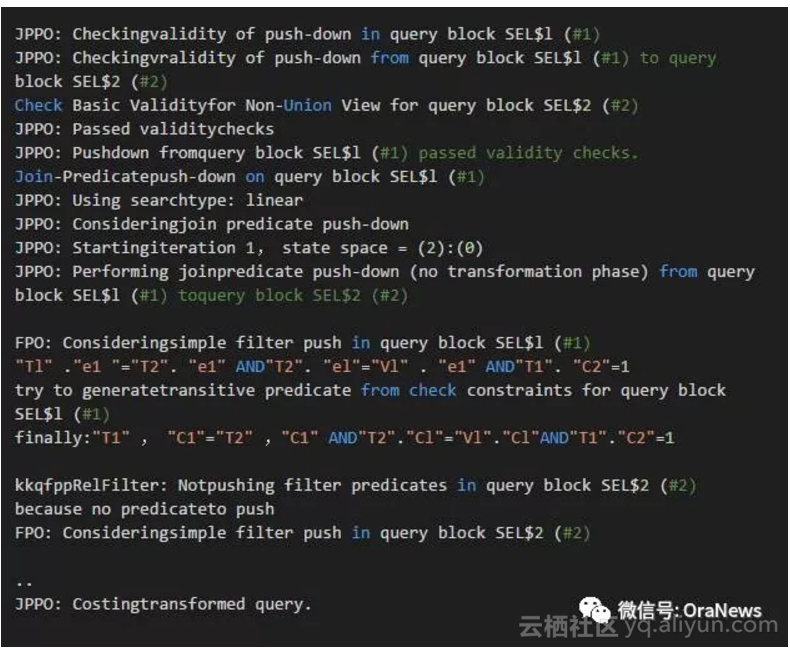
从上面的信息中可以看到,连接谓词推入成功。
这个问题虽然看起来很简单, 但是里面使用到的知识点非常得多。对查询转换没有一个基本的理解与认识,对复制SQL语句的调优,会觉得比较困难。下面请再看一个例子。
案列2:UNION ALL 与 Join Predicate Pushing
对存在UNION ALL 语句的视图进行连接谓词推入,也是一个比较常见的情况。
首先,看一个连接谓词推入成功的例子。
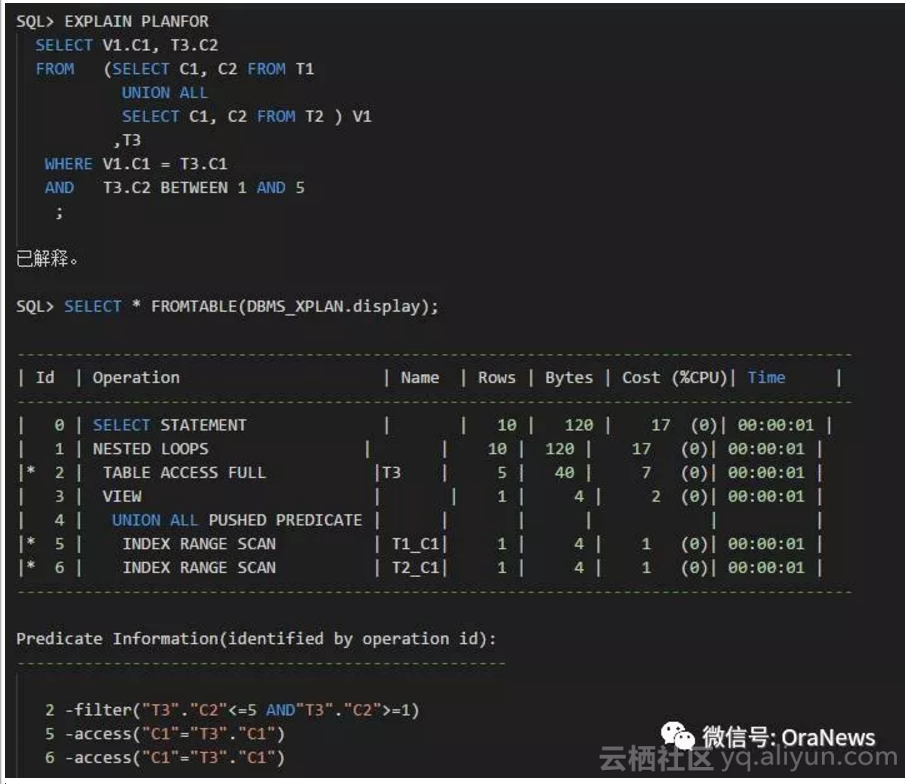
可以看到,执行计划里的信息如下:
- ID:3,可以看到包含UNION ALL 的内嵌视图优化器尝试进行视图合并(View Merge)失败。
- ID:4,可以看到从UNION ALL PUSHED PREDICATE,连接条件谓词推入成功。
- 所以,因谓词推入的成功缘故,ID:5和6出现了不是FullTable Scan的 Index RangeScan,出现了更加优越的执行计划。
也就是说,内嵌视图外面的条件"C1"="T3"."C1"推入到UNION ALL视图内部,从而产生了更加优越的执行计划。因为根据条件T3.C2 BETWEEN 1 AND 5 会对T3表产生少量的结果集。所以,后面跟着出现了 Nested Loops Join的情况,这个的前提是连接条件"C1"="T3"."C1"能够推入到视图里,并且选择了Index Range Scan的时候。
如果,使用提示 NO_PUSH_PRED ,防止连接条件谓词推入的发生会怎么样?
下面请再看一下:
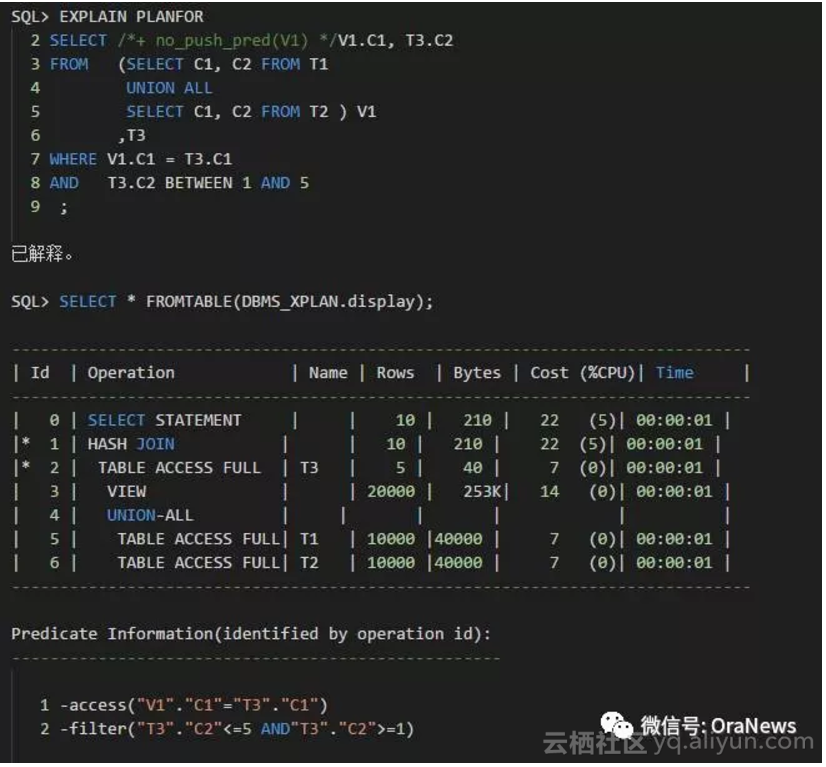
从执行计划中可以看到,没有对UNOIN ALL 视图的谓词推入。所以,在ID:5和6选择了非 IndexRange Scan的 Full TableScan。之后,外面也是选择了非NestedLoops Join的 Hash Join。
是否产生连接谓词推入,要看其成本(Cost)是多少,决定权在CBQT(Cost Based Query Transformation)。如果,优化器判断连接谓词推入的成本更高,即使能做谓词推入也不会选择谓词推入。下面我们再看一个例子。把条件换成T3.C2 BETWEEN 1 AND 100 的时候,被选择的行数会增加,有可能会判断出Nested Loops Join的成本会更高。所以,连接谓词推入有可能不会出现。
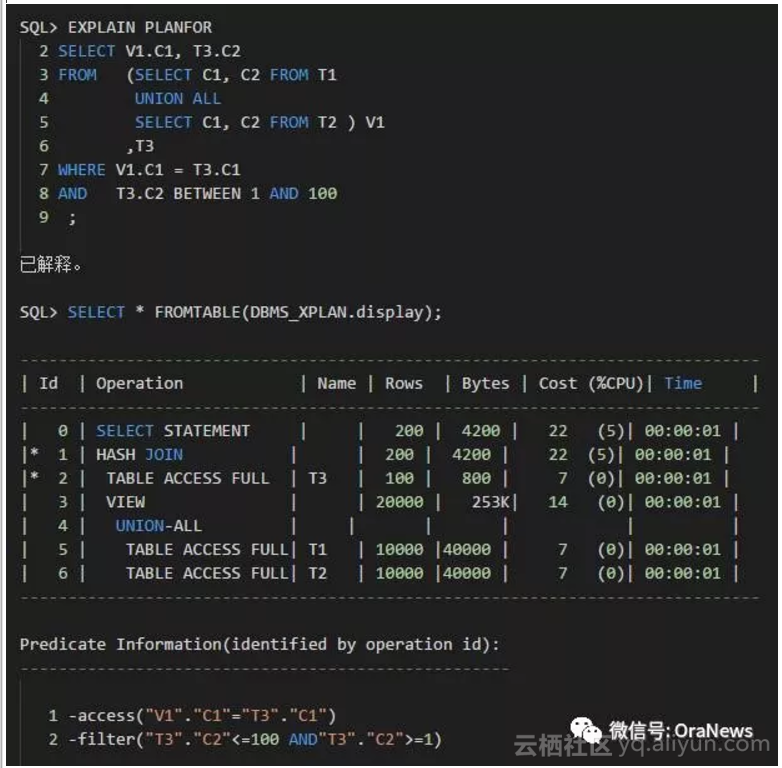
此次,还可以继续做几个有趣的测试。一般提示FIRST_ROWS是为了让执行计划产生能够快速显示头几行的执行计划而使用。所以,一般内部会倾向于选择Nested Loops Join而非Hash Join,也倾向于选择Index Range Scan 而非Table Full Scan。所以,上面的例子如果加上FIRST_ROWS提示的时候,会有很大几率选择连接谓词推入。结果也确实如下所示。
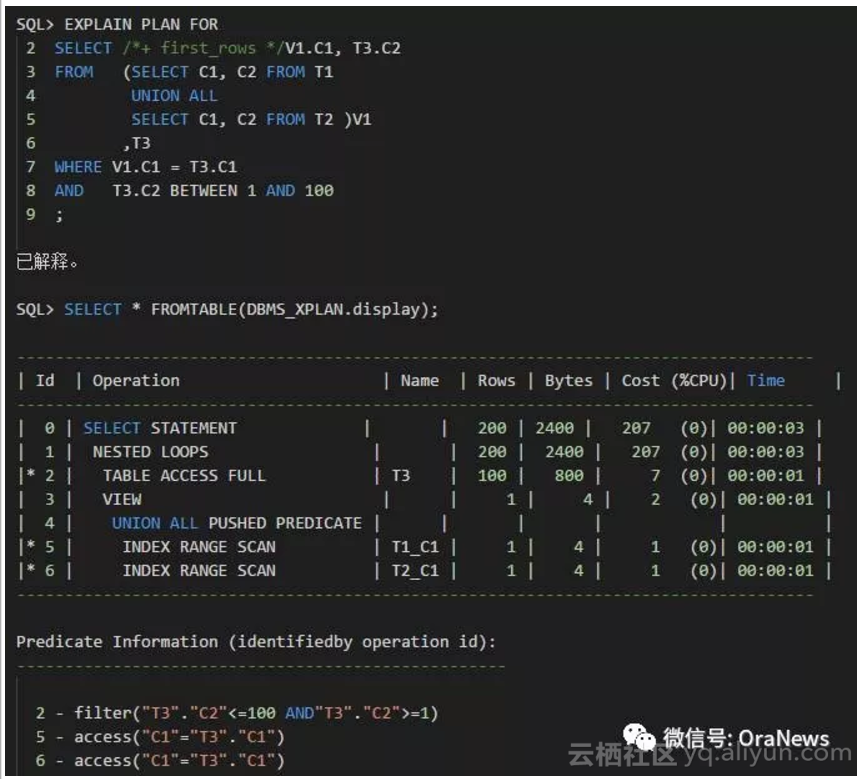
那么,如果使用提示FIRST_ROWS(1)会如何呢?
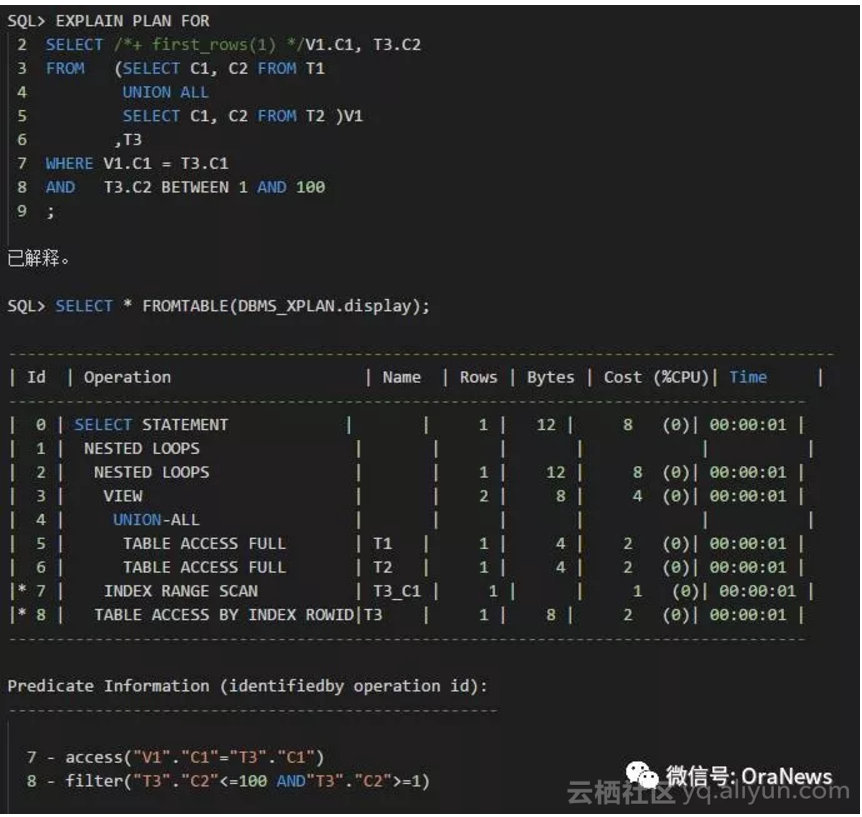
FIRST_ROWS(N)提示与FIRST_ROWS不同,是要求快速显示头N行时,产生的执行计划。与FIRST_ROWS提示不同,FIRST_ROWS(N)提示是基于成本的,而非基于规则,即计算N行成本以后选择执行计划。所以,与FIRST_ROWS相比更灵活,但也更不好预测其执行计划的结果。下面可以看到,选择了一个全新的执行计划。
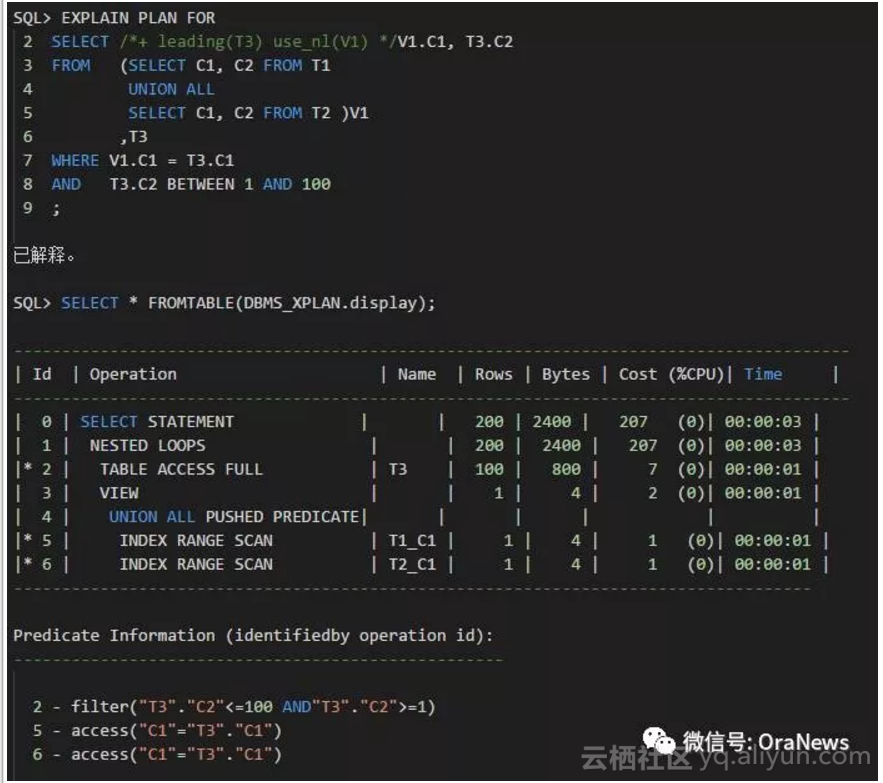
如果,正确理解了连接谓词推入的原理的话,可以使用如下提示LEADING、USE_NL得到相同的结果。选择的路线(PUSH_PRED 与 LEADING + USE_NL)不一样,但是目的地(因谓词推入而选择Index Range Scan与Nested Loops Join)是相同的。
总结
我们看了几个在查询转换(Query Transformation)中非常典型的连接谓词推入的例子。希望在实践中不断进行尝试,来加深对查询转换的理解。优化过程中,经常会问自己为什么不选择索引呢?今后,希望再加上两个问题问自己,为什么不进行谓词推入呢?为什么不进行视图合并呢?对查询转换的认识越深,对执行计划的理解也会变得越来越深,对SQL优化也会变得加更体系化。
原文发布时间为:2017-11-21
本文作者:郭成日