Hash函数在多个领域均有应用,而在数字签名和数据库实现时又用的最多,比如基于hash的索引,是最好的单值查找索引;
同时,在当前数据爆炸的场景下,执行相似item的查找时,在内存受限时,均可以采取LSH(local sensitive hash)进行分段处理。
具体用途很多,不赘述,下面介绍一些常用的知识:
1、hash函数本质;
2、简单的hash函数生成法;
3、hash的冲突消解;
另外:分享一个国外牛人的个人网站,有非常全面的hash算法列表:http://burtleburtle.net/bob/hash/
主要内容:
1、hash的本质
Hash函数是指把一个大范围映射到一个小范围。把大范围映射到一个小范围的目的往往是为了节省空间。在考虑使用Hash函数之前,需要明白它的几个限制:
(1). Hash的主要原理就是把大范围映射到小范围;所以,你输入的实际值的个数必须和小范围相当或者比它更小。不然冲突就会很多。
(2). 由于Hash逼近单向函数;所以,你可以用它来对数据进行加密。
(3). 不同的应用对Hash函数有着不同的要求;比如,用于加密的Hash函数主要考虑它和单项函数的差距,而用于查找的Hash函数主要考虑它映射到小范围的冲突率。
Hash函数好坏非评判标准:简单和均匀。
简单指散列函数的计算简单快速;
均匀指对于关键字集合中的任一关键字,散列函数能以等概率将其映射到表空间的任何一个位置上。也就是说,散列函数能将子集K随机均匀地分布在表的地址集{0,1,…,m-1}上,以使冲突最小化。
2、常用hash生成方法
常用的散列函数构造有6种方法,1,直接定址法; 2,数字分析法; 3 ,平方取中法;4,折叠法;5,除留余数法;6,伪随机数法
(1)平方取中法具体方法:先通过求关键字的平方值扩大相近数的差别,然后根据表长度取中间的几位数作为散列函数值。又因为一个乘积的中间几位数和乘数的每一位都相关,所以由此产生的散列地址较为均匀。
【例】将一组关键字(0100,0110,1010,1001,0111)平方后得
(0010000,0012100,1020100,1002001,0012321)
若取表长为1000,则可取中间的三位数作为散列地址集:
(100,121,201,020,123)。
相应的散列函数用C实现很简单:
int Hash(int key){ //假设key是4位整数
key*=key; key/=100; //先求平方值,后去掉末尾的两位数
return key%1000; //取中间三位数作为散列地址返回
}
(2)除余法
该方法是最为简单常用的一种方法。它是以表长m来除关键字,取其余数作为散列地址,即 h(key)=key%m
该方法的关键是选取m。选取的m应使得散列函数值尽可能与关键字的各位相关。m最好为素数。
【例】若选m是关键字的基数的幂次,则就等于是选择关键字的最后若干位数字作为地址,而与高位无关。于是高位不同而低位相同的关键字均互为同义词。
【例】若关键字是十进制整数,其基为10,则当m=100时,159,259,359,…,等均互为同义词。
(3)相乘取整法
该方法包括两个步骤:首先用关键字key乘上某个常数A(0<A<1),并抽取出key.A的小数部分;然后用m乘以该小数后取整。即:
该方法最大的优点是选取m不再像除余法那样关键。比如,完全可选择它是2的整数次幂。虽然该方法对任何A的值都适用,但对某些值效果会更好。Knuth建议选取
该函数的C代码为:
int Hash(int key){
double d=key *A; //不妨设A和m已有定义
return (int)(m*(d-(int)d));//(int)表示强制转换后面的表达式为整数
}
(4)随机数法
选择一个随机函数,取关键字的随机函数值为它的散列地址,即
h(key)=random(key)
其中random为伪随机函数,但要保证函数值是在0到m-1之间。
3、hash的冲突消解
1)冲突是如何产生的?
上文中谈到,哈希函数是指如何对关键字进行编址的规则,这里的关键字的范围很广,可视为无限集,如何保证无限集的原数据在编址的时候不会出现重复呢?规则本身无法实现这个目的。举一个例子,仍然用班级同学做比喻,现有如下同学数据
张三,李四,王五,赵刚,吴露.....
假如我们编址规则为取姓氏中姓的开头字母在字母表的相对位置作为地址,则会产生如下的哈希表
| 位置 | 字母 | 姓名 | |
| 0 | a | ||
| 1 | b | ||
| 2 | c |
| 10 | L | 李四 |
...
| 22 | W | 王五,吴露 |
| 25 | Z | 张三,赵刚 |
我们注意到,灰色背景标示的两行里面,关键字王五,吴露被编到了同一个位置,关键字张三,赵刚也被编到了同一个位置。老师再拿号来找张三,座位上有两个人,"你们俩谁是张三?"
2)如何解决冲突问题
既然不能避免冲突,那么如何解决冲突呢,显然需要附加的步骤。通过这些步骤,以制定更多的规则来管理关键字集合,通常的办法有:
a)开放地址法
开放地执法有一个公式:Hi=(H(key)+di) MOD m i=1,2,...,k(k<=m-1)
其中,m为哈希表的表长。di 是产生冲突的时候的增量序列。如果di值可能为1,2,3,...m-1,称线性探测再散列。
如果di取1,则每次冲突之后,向后移动1个位置.如果di取值可能为1,-1,2,-2,4,-4,9,-9,16,-16,...k*k,-k*k(k<=m/2)
称二次探测再散列。如果di取值可能为伪随机数列。称伪随机探测再散列。仍然以学生排号作为例子,
现有两名同学,李四,吴用。李四与吴用事先已排好序,现新来一名同学,名字叫王五,对它进行编制
| 10.. | .... | 22 | .. | .. | 25 |
| 李四.. | .... | 吴用 | .. | .. | 25 |
| 10.. | .. | 22 | 23 | 25 |
| 李四.. | 吴用 | 王五 |
| 10... | 20 | 22 | .. | 25 |
| 李四.. | 王五 | 吴用 |
| 1... | 10... | 22 | .. | 25 |
| 王五.. | 李四.. | 吴用 |
(c)伪随机探测再散列,伪随机序列为:5,3,2
b)再哈希法
当发生冲突时,使用第二个、第三个、哈希函数计算地址,直到无冲突时。缺点:计算时间增加。
比如上面第一次按照姓首字母进行哈希,如果产生冲突可以按照姓字母首字母第二位进行哈希,再冲突,第三位,直到不冲突为止
c)链地址法
将所有关键字为同义词的记录存储在同一线性链表中。如下: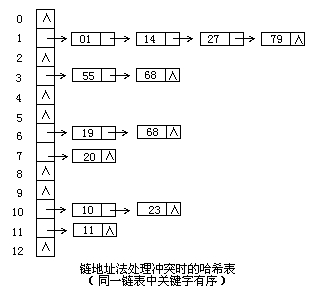
因此这种方法,可以近似的认为是筒子里面套筒子
d.建立一个公共溢出区(比较常见于实际操作中)
假设哈希函数的值域为[0,m-1],则设向量HashTable[0..m-1]为基本表,另外设立存储空间向量OverTable[0..v]用以存储发生冲突的记录。
经过以上方法,基本可以解决掉hash算法冲突的问题。
注:之所以会简单得介绍了hash,是为了更好的学习lzw算法,学习lzw算法是为了更好的研究gif文件结构,最后,我将详细的阐述一下gif文件是如何构成的,如何高效操作此种类型文件。
除了上诉的几种方法,还有许多用于散列表的方法,比如散列函数不好或装填因子过大,都会使堆积现象加剧。为了减少堆积的发生,不能像线性探查法那样探查一个顺序的地址序列(相当于顺序查找),而应使探查序列跳跃式地散列在整个散列表中。衍生出二次探查法,双重散列表法。
本文转自: http://blog.csdn.net/yumengkk/article/details/7031357
