占领了虚拟货币芯片80%以上的市场后,比特大陆开始拿着高性能计算芯片设计的“锤子“探索新的”钉子“,而深度学习计算芯片无疑是其中最大的一颗。
随着大数据发展、深度学习算法和计算技术的突破,人工智能掀起了新的时代浪潮。同时,全球科技巨头如Google, Facebook, Microsoft,国内BAT都在抢占布局AI市场。而芯片和算法,被视为是人工智能产业的重要技术支撑。
近日,北京比特大陆科技有限公司(以下简称“比特大陆”/BITMAIN)推出了人工智能品牌SOPHON(算丰),并重磅发布了面向人工智能应用的专用定制芯片SOPHON BM1680,深度学习加速卡SC1和SC1+以及智能视频分析服务器SS1。同时,笔者注意到,“算丰”的官网SOPHON.AI已正式上线,比特大陆的芯片、加速卡和处理器都已经进入量产阶段,11月8日在官网全球发售。
“人工智能驱动了又一个星球级的计算体量。”比特大陆联合创始人、CEO詹克团在发布会上表示。
比特大陆发布的三款产品标志着其正式进军AI芯片领域。作为今年人工智能领域的重要赛道之一,尽管“人工智能芯片”相比于语音识别等技术,在消费级市场并没有得到大众的特别关注,但是作为人工智能的基础硬件设施,其已经成为诸多公司抢夺人工智能市场、占据风口的一大战略制胜点。
国内,相关初创公司战况愈烈:上个月,主打“嵌入式”的地平线机器人获得来自英特尔的战投,预计年底前将完成A轮融资;同月晚些时候,深鉴科技宣布已完成约4000万美金的A+轮融资,将加大对安防和相关研发投入;今年8月,寒武纪完成一亿美元A轮融资,成为人工智能芯片领域的首个独角兽。而英特尔等国际大公司也在陆续进入这个炙手可热的领域:英特尔陆续收购Altera、Mobileye等多家公司,拿下相关技术;芯片大厂英伟达则凭借在GPU上的优势走在了人工智能芯片的前列,前几个月,黄仁勋在GTC技术大会上还发布了一款针对深度学习而打造的芯片Tesla V100;微软则把重心放在FPGA人工智能芯片上,目前已经被用在Bing搜索的支持上。
入场人工智能领域,是比特大陆的重要一步。而这家全球最大的数字货币芯片及硬件公司入局人工智能领域也无疑对这个赛道产生了不可置疑的巨大影响。
拿着锤子找钉子,现在是进军人工智能行业的最佳时机
在第三次的人工智能浪潮中,作为让人工智能技术更快、更好运行的基础硬件设施,人工智能芯片必然是未来智能化时代的重要底层技术。也因此,虽然人工智能芯片相比于其他人工智能技术和应用显得低调得多,但它的布局依旧是众多厂商眼中不能错过的“机遇”。
比特大陆显然也看好这一机会,而多年来在芯片应用领域多积累的专业经验,也让其在切入这一新领域的过程中深入且高效:汇聚了世界各地对AI怀抱无限激情的工作者,比特大陆的研发团队中有全球芯片设计领域的一流专家,有深度学习算法领域的顶级高手,有计算机视觉领域的超级大师,这个团队亟待在具有强大竞争对手的AI领域开辟出一片前所未有的天地。
数字货币芯片出身的比特大陆成立于2013年,詹克团称在比特币、莱特币这些主要的虚拟数字货币市场上,比特大陆的占有率已经超过80%,甚至可能超过90%。比特大陆用全定制的芯片设计方法去设计高速低功耗的芯片。在今年16纳米节点上,其芯片出货量已经超过10亿只,而其商业模式非常简单,最核心就是卖比特币等虚拟货币的挖矿机。除了研发和销售矿机,比特大陆还在建设和部署大型的数据中心。
“在比特币上小有成就之后,我们感觉自己手里好像拿着一把锤子,到处看哪里都是钉子”,就在找钉子的过程中,我们发现深度学习是非常适合用锤子对付的钉子,所以我们开始做这个深度学习计算芯片。
比特大陆很早就意识到,不断提升的计算量在计算机体系结构上面要做一定的创新,传统的CPU显然不合适。因此,从各种产业和论文都可以看到,其实深度学习用在Cloud端高性能芯片的体系结构,都已经慢慢往Tensor架构靠拢。
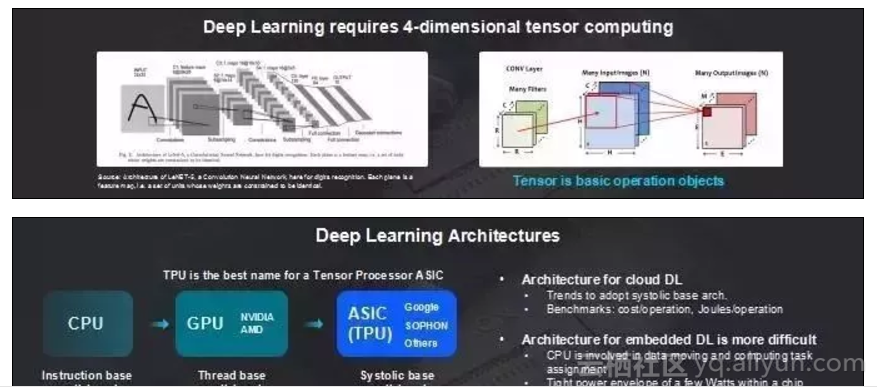
从Cloud端看Deep Learning计算非常简单,一个是性价比和能耗比。对于Deep Learning来说,确实在这两个方面会表现的相当好,因此对于云端的Deep Learning计算,我认为谷歌提出“TPU”张量计算处理器,Tensor这个名字是很合适的。
“但Deep Learning计算还有另外一种芯片应用,就是终端,我个人认为这是更加困难的,做这种架构由于不得不受限于单芯片的功耗,不能太大,一般来说这种芯片很难超过10瓦,所以设计这种的体系结构是非常有挑战的一件事情。”詹克团称。
“在数字货币领域经过战争般的洗礼,进而奠定我们的优势,我们会跑的快一点。”
“我们从2013年就开始做,如果一定要说我们有什么优势,那就是我们可能会跑得比较快一点,毕竟我们的公司的市场管理、研发管理、财务,还有很多东西我们已经在虚拟货币市场上经过战争般的洗礼,虚拟货币这个市场又是发展非常快速的市场,所以相对来说比特大陆可能会动作会更快一点点。”在发布会上,詹克团如此描述入主人工智能芯片领域的优势。
据了解,比特大陆基于自研的数字货币芯片,研发和量产了高性能、高密度的服务器系统矿机,且在全球多个地区建立数据中心,并基于此搭建云计算服务及大规模并行计算资源调度服务平台。
成立四年多来,比特大陆的产品已销往全球100多个国家,且在海外多个国家设置销售和客服团队,提供24小时支持服务,覆盖中文、英语、俄语、韩语等。对标谷歌TPU,面向全球交付采用改进型“Systolic脉动陈列”技术的AI芯片
随着数据量级的迅速增大,深度学习在硬件执行上一直面临瓶颈。
大概3年前,CPU还是人们在应用机器学习算法时最常用的硬件芯片。CPU基于其构造,70%的晶体管都被用来构建Cache,还有一部分用来控制单元,计算单元少,适合运算复杂逻辑复杂的算法,对程序员来说非常友好。但是,随着数据量和运算量的迅速增加,CPU执行机器学习的缺点也逐渐暴露。CPU为了满足通用性,很大一部分的芯片面积用于复杂的控制流,牺牲了运算效率,并且,CPU也不支持张量计算。
这时候,GPU进入了机器学习研究者的视野。GPU晶体管大部分构建计算单元,运算复杂度低,适合大规模并行计算。以图像渲染为目的的GPU支持SIMD架构,这一点对机器学习算法非常有效。因此GPU的SIMT架构虽然能遮盖内存访问实现高吞吐量,但是能效比(即执行完单位运算需要的能量)并不好。但是,目前能效比正在成为越来越重要的指标。对于移动应用,能效比不好意味着电池很快就会被用完,影响人工智能的普及;对于云端数据中心应用,能效比不好则意味着数据中心需要在散热投入许多钱,而目前散热已经成为数据中心最大的开销之一。
在去年的谷歌 I/O 开发者大会上,谷歌宣布发布了一款新的定制化硬件——张量处理器(Tensor Processing Unit/TPU),这一新想法的提出令业内人士激动不已,但谷歌迟迟没有公布细节。直到今年4月份,Google发表论文,详解了神经网络推断专用芯片TPU的架构,还展示了一些性能数据,比如说:在推断任务中,TPU平均比英伟达的Tesla K80 GPU或英特尔至强E5-2699 v3 CPU速度快15至30倍左右。
TPU作为一种人工智能技术专用处理器,在种类上归属于ASIC(Application Specific Integrated Circuit,为专门目的而设计的集成电路)。相比人工智能技术常见的另外几种处理器CPU(中央处理器)、GPU(图像处理器)、FPGA(阵列可编程逻辑门阵列),ASIC天生就是为了应用场景而生,不会有冗余,功耗低、计算性能高、计算效率高,所以在性能表现和工作效率上都更加突出。
以下是Google硬件工程师 Norm Jouppi 在Google云计算博客上透露的部分性能信息:
1、在神经网络层面的操作上,处理速度比当下GPU和CPU快15到30倍;
2、在能效比方面,比GPU和CPU高30到80倍;
3、在代码上也更加简单,100到1500行代码即可以驱动神经网络;
这要归功于ASIC本身的特点:处理器的计算部分专门为目标数据设计,不需要考虑兼容多种情况,控制配套结构非常简单,间接提升了能效比;可以在硬件层面对软件层面提前进行优化,优化到位的情况下可以极大减少API接口的工作量。
在谷歌的TPU处理器中,最大的创新点之一就是采用了Systolic(脉动式)数据流。在矩阵乘法和卷积运算中,许多数据是可以复用的,同一个数据需要和许多不同的权重相乘并累加以获得最后结果。因此,在不同的时刻,数据输入中往往只有一两个新数据需要从外面取,其他的数据只是上一个时刻数据的移位。在这种情况下,把内存的数据全部Flush再去去新的数据无疑是非常低效的。根据这个计算特性,TPU加入了脉动式数据流的支持,每个时钟周期数据移位,并取回一个新数据。这样做可以最大化数据复用,并减小内存访问次数,在降低内存带宽压力的同时也减小了内存访问的能量消耗。
Systolic事实上并不是一个太新的东西,在1982年,H. T. Kung首次在论文中提出了这一设计,对于为什么要设计这样的架构,作者给出了三个理由:要真正理解脉动阵列,首先要问的就是发明者的初衷。这正好也是1982年H. T. Kung论文的题目。对于为什么要设计这样的架构,作者给出了三个理由:
对于为什么要设计这样的架构,作者给出了三个理由:
1. Simple and regular design:简单和规则是脉动阵列的一个重要原则。
2. Concurrency and communication:并行性和通信的重要。
3. Balancing computation with I/O:平衡运算和I/O,这是脉动阵列最重要的设计目标。
总结来说,正如一位知乎大v唐杉所说:脉动架构是一种很特殊的设计,结构简单,实现成本低。
脉动架构有几个特征:
1. 由多个同构的PE构成,可以是一维或二维,串行、阵列或树的结构(现在我们看到的更多的是阵列形式);
2. PE功能相对简单,系统通过实现大量PE并行来提高运算的效率;
3. PE只能向相邻的PE发送数据(在一些二维结构中,也可能有对角线方向的数据通道)。数据采用流水线的方式向“下游”流动,直到流出最后的PE。
值得一提的是,和谷歌TPU的内核一样,SOPHON BM1680内部的加速器内核也采用了脉动阵列(Systolic)架构技术。Systolic在处理Deep Learning运算上有得天独厚的优势,用硬件实现多维的数据搬运和计算任务的调度,就可以获得非常高的性能,适合用在云端做加速。

据了解,SOPHON BM1680可适用于CNN、RNN和DNN等多网络的预测和训练,这也是继谷歌发布TPU之后,又一款专门用于张量计算加速的专用芯片(ASIC)。
最后,比特大陆也给出了SOPHON的迭代时间线:第二代芯片BM1682下个月发布,也是采用16纳米工艺,功耗差不多还是30瓦,计算能力大概是3T。第三代芯片会在明年的9月份发布,采用12纳米工艺,功耗30瓦,计算能力到6T。

《三体》中的超级机器人SOPHON:服务器+软件全栈+应用API的全套解决方案
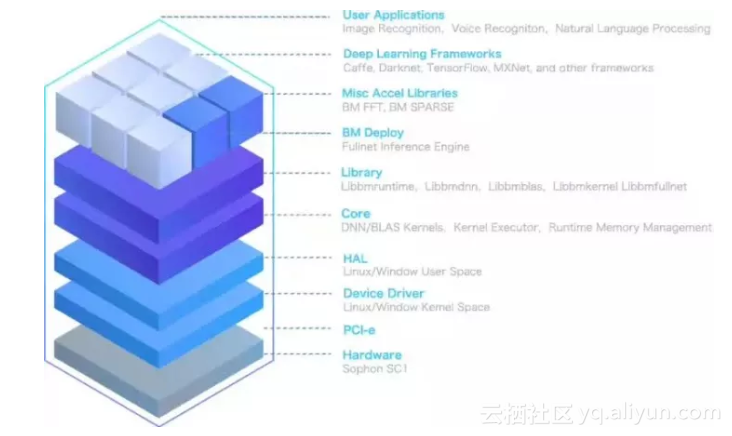
SOPHON的名字来自刘慈欣的小说《三体》。在《三体》中,SOPHON是被三体人制造出来锁死地球科技的强人工智能体。比特大陆对SOPHON的厚望也如此,除了作为芯片提供方,SOPHON致力于拥有软硬件全栈开发的能力,和各个层次的工具链能力。从硬件、驱动、指令集、线性代数加速核心数学库,RUNTIME库,BM Deploy的Inference部署工具,FFT加速库,针对SOPHON芯片优化的深度学习框架(Caffe,Darknet, Tensorflow,MXNet等),以真正实现软件、硬件的协同设计和一体化的优化,实现深度学习应用在硬件上的最佳优化性能。
从SOPHON官网的参数介绍中可以了解到,BM1680现已支持Caffe Model和Darknet Model的编译和优化,适用于Alexnet,GoogLeNet,VGG,ResNet,YOLO,YOLO2等网络。
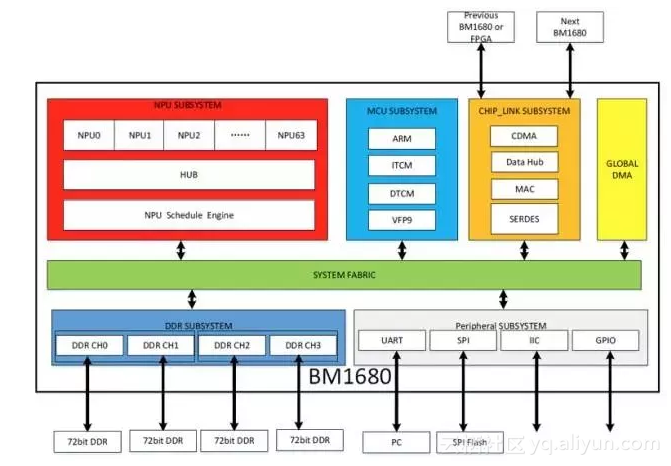
BM1680芯片架构图(摘自BM1680 DATASHEET文档)
基于BM1680芯片,比特大陆还推出了两款新产品:深度学习加速卡SOPHON SC1和智能视频分析服务器SOPHON SS1,并同步发布SOPHON.AI官网。会上,比特大陆通过该服务器成功演示了机非人结构化demo,人体/人脸检测Demo,这两者广泛应用于安防视频监控、公安、交通、金融等领域。

SC1和SC1+的架构类似,都是PCIE的总线连入系统
据介绍,SOPHON SS1提供了一整套针对视频和图像识别技术的深度学习解决方案。系统核心组件是两张SOPHON SC1(或SC1+)深度学习加速卡,通过PCIE接口实现与应用系统的连接。SS1的应用系统基于X86 CPU打造,以供启动、存储管理及深度学习SDK协调之用。SS1的整个系统被浓缩进一个4机架单位(4U)机箱中,集电源、冷却、网络、多系统互联及文件系统于一体,客户可以在此基础上实现快速的二次开发或系统集成,最大程度上方便了用户对深度学习系统的利用。
“比特大陆在深度学习、AI领域的使命,或者说目标,和我们在数字货币上面做的事情一样,通过一点一点的、一代又一代的芯片,一代又一代的产品不断迭代,把产品做到极致,做到最好,服务好需要用到深度学习加速服务的用户和应用。”詹克团称。
比特大陆“千呼万唤始出来”的人工智能芯片终于面世于众,其在人工智能领域激起的新波澜已然不容置疑。然而,在此次发布的第一代产品基础上,未来的产品迭代和相关生态建设可能是更加值得市场关注的问题。
原文发布时间为:2017-11-14







