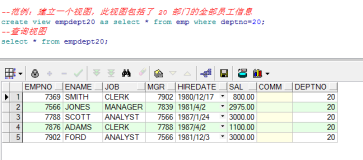
原文整理自网络:
Oracle支持两种类型的聚簇:
索引聚簇和哈希聚簇
1. 什么是聚簇
聚簇是根据码值找到数据的物理存储位置,从而达到快速检索数据的目的。聚簇索引的顺序就是数据的物理存储顺序,叶节点就是数据节点。非聚簇索引的顺序与数据物理排列顺序无关,叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。一个表最多只能有一个聚簇索引。
2. 使用 Oracle 聚簇索引
聚簇是一种存储表的方法,这些表密切相关并经常一起连接进磁盘的同一区域。例如,表 BOOKSHELF 和BOOKSHELF_AUTHOR 数据行可以一起插入到称为簇(Cluster)的单个区域中,而不是将两个表放在磁盘上的不同扇区上。簇键(Cluster Key)可以是一列或多列,通过这些列可以将这些表在查询中连接起来(例如,BOOKSHELF表和BOOKSHELF_AUTHOR表中的 Title列)。为了将表聚集在一起,必须拥有这些将要聚集在一起的表。
下面是create cluster命令的基本格式:
create cluster (column datatype [, column datatype]。..) [other options];
cluster的名字遵循表命名约定,column datatype是将作为簇键使用的名字和数据类型。column的名字可以与将要放进该簇中的表的一个列名相同,或者为其他有效名字。下面是一个例子:
create cluster BOOKandAUTHOR (Col1 VARCHAR2(100));
这样就建立了一个没有任何内容的簇(象给表分配了一块空间一样)。COL1的使用对于簇键是不相干的,不会再使用它。但是,它的定义应该与要增加的表的主键相符。接下来,建立包含在该簇中的表:
create table BOOKSHELF
(Title VARCHAR2(100) primary key,
Publisher VARCHAR2(20),
CategoryName VARCHAR2(20),
Rating VARCHAR2(2),
constraint CATFK foreign key (CategoryName) references CATEGORY(CategoryName)
)
cluster BOOKandAUTHOR(Title);
在向BOOKSHELF表中插入数据行之前,必须建立一个聚簇索引:
create index BOOKandAUTHORndx on cluster BOOKandAUTHOR;
在上面的create table语句中,簇BOOKandAUTHOR(Title)子句放在表的列清单的闭括号的后面。BOOKandAUTHOR是前面建立的聚簇的名字。Title是将存储到聚簇Col1中的该表的列。create cluster语句中可能会有多个簇键,并且在created table语句中可能有多个列存储在这些键中。请注意,没有任何语句明确说明Title列进入到Col1中。这种匹配仅仅是通过位置做到的,即Col1和Title都是在它们各自的簇语句中提到的第一个对象。多个列和簇键是第一个与第一个匹配,第二个与第二个匹配,第三个与第三个匹配,等等。现在,添加第二个表到聚簇中:
create table BOOKSHELF_AUTHOR
(Title VARCHAR2(100),
AuthorName VARCHAR2(50),
constraint TitleFK Foreign key (Title) references BOOKSHELF(Title),
constraint AuthorNameFK Foreign key (AuthorName) references AUTHOR(AuthorName)
)
cluster BOOKandAUTHOR (Title);
当这两个表被聚在一起时,每个唯一的Title在簇中实际只存储一次。对于每个Title,都从这两个表中附加列。来自这两个表的数据实际上存放在一个位置上,就好像簇是一个包含两个表中的所有数据的大表一样。
3. 散列聚簇
对于散列聚簇,它只有一个表。它通过散列算法求出存储行的物理存储位置,从而快速检索数据。创建散列聚簇时要指定码列的数据类型,数据行的大小及不同码值的个数。如果码值不是平均分布的,就可能有许多行存储到溢出块上,从而会降低查询该表的SQL语句的性能。
散列聚簇被用在总是通过主键查询数据的情况,例如要从表 T 查询数据并且查询语句总是是这样:
select * from T where id = :x;
这时散列聚簇是一个好的选择,因为不需要索引。Oracle 将通过散列算法得到值 :x 所对应的物理地址,从而直接取到数据。不用进行索引扫描,只通过散列值进行一次表访问。
散列聚簇语法示例:
CREATE CLUSTER personnel
( department_number NUMBER )
SIZE 512 HASHKEYS 500
STORAGE (INITIAL 100K NEXT 50K);
CREATE CLUSTER personnel
( home_area_code NUMBER,
home_prefix NUMBER )
HASHKEYS 20
HASH IS MOD(home_area_code + home_prefix, 101);
CREATE CLUSTER personnel
(deptno NUMBER)
SIZE 512 SINGLE TABLE HASHKEYS 500;
Oracle数据库支持两种类型的聚簇,分别是索引聚簇和哈希聚簇,本文将针对这两种类型聚簇的使用进行详细的介绍。
索引聚簇的使用:
◆对经常在连接语句中访问的表建立聚簇。
◆假如表只是偶尔被连接或者它们的公共列经常被修改,则不要聚簇表。(修改记录的聚簇键值比在非聚簇的表中修改此值要花费更多的时间,因为Oracle必须将修改的记录移植到其他的块中以维护聚簇)。
◆假如经常需要在一个表上进行完全搜索,则不要聚簇这个表(对一个聚簇表进行完全搜索比在非聚簇表上进行完全搜索的时间长,Oracle可能要读更多的块,因为表是被一起存储的。)
◆假如经常从一个父表和相应的子表中查询记录,则考虑给1对多(1:*)关系创建聚簇表。(子表记录存储在与父表记录相同的数据块中,因此当检索它们时可以同时在内存中,因此需要Oracle完成较少的I/O)。
◆假如经常查询同一个父表中的多个子记录,则考虑单独将子表聚簇。(这样提高了从相同的父表查询子表记录的性能,而且也没有降低对父表进行完全搜索的性能)。
◆假如从所有有相同聚簇键值的表查询的数据超过一个或两个Oracle块,则不要聚簇表。(要访问在一个聚簇表中的记录,Oracle读取所有包含那个记录值的全部数据块,如果记录占据了多个数据块,则访问一个记录需要读的次数比一个非聚簇的表中访问相同的记录读的次数要多)。
哈希聚簇的使用:
◆当经常使用有相同列的包含相等条件的查询子句访问表时,考虑使用哈希聚簇来存储表。使用这些列作为聚簇键。
◆如果可以确定存放具有给定聚簇键值的所有记录所需的空间(包括现在的和将来的),则将此表以哈希聚簇存储。
◆如果空间不够,并且不能为将要插入的新记录分配额外的空间,那么不要使用哈希聚簇。
◆如果偶尔创建一个新的、很大的哈希聚簇来保存这样的表是不切实际的,那么不要用哈希聚簇存储经常增长的表。
◆如果经常需要进行全表搜索,并且必须要为表的预期增长中的哈希聚簇分配足够的空间,则不要将此表以哈希聚簇存储。(这样的完全检索必须要读分配给哈希聚簇的全部块,即使有些块可能只包含很少的记录。单独地存储表将减少由完全的表检索读取的块的数量。)
◆如果你的应用程序经常修改聚簇键的值,则不要将表以哈希聚簇方式存储。
◆不论这个表是否经常与其他表连接,只要进行哈希对于基于以前的指南的表合适,那么在哈希聚簇中存储一个表则是有用的。
使用索引聚簇指南
l 考虑对经常在连接语句中访问的表建立聚簇。
l 如果表只是偶尔被连接或者它们的公共列经常被修改,则不要聚簇表。(修改记录的聚簇键值比在非聚簇的表中修改此值要花费更多的时间,因为Oracle必须将修改的记录移植到其他的块中以维护聚簇)。
l 如果经常需要在一个表上进行完全搜索,则不要聚簇这个表(对一个聚簇表进行完全搜索比在非聚簇表上进行完全搜索的时间长,Oracle可能要读更多的块,因为表是被一起存储的。)
l 如果经常从一个父表和相应的子表中查询记录,则考虑给1对多(1:*)关系创建聚簇表。(子表记录存储在与父表记录相同的数据块中,因此当检索它们时可以同时在内存中,因此需要Oracle完成较少的I/O)。
l 如果经常查询同一个父表中的多个子记录,则考虑单独将子表聚簇。(这样提高了从相同的父表查询子表记录的性能,而且也没有降低对父表进行完全搜索的性能)。
l 如果从所有有相同聚簇键值的表查询的数据超过一个或两个Oracle块,则不要聚簇表。(要访问在一个聚簇表中的记录,Oracle读取所有包含那个记录值的全部数据块,如果记录占据了多个数据块,则访问一个记录需要读的次数比一个非聚簇的表中访问相同的记录读的次数要多)。
使用哈希聚簇指南
l 当经常使用有相同列的包含相等条件的查询子句访问表时,考虑使用哈希聚簇来存储表。使用这些列作为聚簇键。
l 如果可以确定存放具有给定聚簇键值的所有记录所需的空间(包括现在的和将来的),则将此表以哈希聚簇存储。
l 如果空间不够,并且不能为将要插入的新记录分配额外的空间,那么不要使用哈希聚簇。
l 如果偶尔创建一个新的、很大的哈希聚簇来保存这样的表是不切实际的,那么不要用哈希聚簇存储经常增长的表。
l 如果经常需要进行全表搜索,并且必须要为表的预期增长中的哈希聚簇分配足够的空间,则不要将此表以哈希聚簇存储。(这样的完全检索必须要读分配给哈希聚簇的全部块,即使有些块可能只包含很少的记录。单独地存储表将减少由完全的表检索读取的块的数量。)
l 如果你的应用程序经常修改聚簇键的值,则不要将表以哈希聚簇方式存储。
l 不管这个表是否经常与其他表连接,只要进行哈希对于基于以前的指南的表是合适的,那么在哈希聚簇中存储一个表可能是有用的。

![[Oracle]索引](https://ucc.alicdn.com/pic/developer-ecology/3mfxe2r26qbaq_c50f50e14c2447959ba0c272c4967106.jpeg?x-oss-process=image/resize,h_160,m_lfit)