http协议的无状态性导致在需要会话的场景下寸步难行,例如一个网站为了方便用户,在一段时间内登录过改网站的浏览器客户端实现自动登录,为实现这种客户端与服务器之间的会话机制需要额外的一些标识,http头部引入的Cookies正是客户端与服务器会话机制的基础。当一个浏览器通过http协议访问某服务器时,服务器可以将指定的一些键值对发往客户端,客户端根据域名保存于本地,下次访问此域名时浏览器会连同此些键值对带到服务器端,这样就实现了服务器与客户端之间的会话机制。
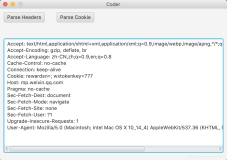
① 客户端第一次访问的报文(无cookies):
GET /web/index.jsp HTTP/1.1
Accept-Language:zh-CN
User-Agent:Mozilla/5.0(Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63Safari/537.36
HOST:localhost:8080
Connection:Keepp-Alive
② 服务器响应报文:
HTTP/1.1 200 OK
Content-Length: 3000
Content-Type:text/html;charset=utf-8
Set-Cookie:user=lilei;weight=70kg
Connection: Keep-Alive
③ 客户端第二次访问(带cookies):
GET /web/index.jsp HTTP/1.1
Accept-Language:zh-CN
User-Agent:Mozilla/5.0(Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63Safari/537.36
HOST:localhost:8080
Connection:Keepp-Alive
Cookie:user=lilei;weight=70kg
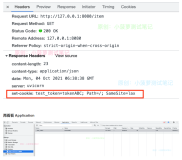
第一次访问localhost:8080/web/index.jsp时浏览器搜索本地无相关cookies,服务器接收报文后做出响应,通过http协议的Set-Cookies头部把user=lilei;weight=70kg返回浏览器,浏览器把cookies信息保存到本地,第二次访问时浏览器搜到有相关的cookies并发往服务器,服务器收到信息知道此浏览器之前是lilei用户使用,并且他的体重是70kg,服务器可根据用户信息做一些个性化处理,这就是cookies。
Cookies将信息储存在客户端,每次通信都要将这些信息附带在报文里面,这会导致带宽浪费、敏感数据安全、对复杂结构数据力不从心等等问题,每次访问都把cookies发送到服务器,当cookies较大时明显有带宽浪费问题,假如将用户名密码放到客户端显然存在安全问题,cookies对于非键值对结构的数据肯定力不从心。针对这些问题提出一种解决方案——服务器会话Session,将数据存在服务器无需客户端携带,数据安全更加可控且数据结构可以任意复杂。当然,这种Session的实现也要依靠cookies,服务器把一个唯一值JSESSIONID发往客户端,每个唯一值表示一个客户端,客户端与服务器通信时携带此唯一值,服务器根据唯一值寻找属于此客户端的所有数据。服务器会话并非本章节要讨论的重点,将在后面相关章节再深入探讨实现原理。
重新回到cookies,浏览器将cookies发往tomcat服务器后,tomcat需要将这些信息封装成对象,如下图,Cookies对象包含了若干个ServerCookie,而每个ServerCookie主要包含了name和value,即键值对。当然还包括其他参数,例如maxAge表示cookie过期时间,path表示cookie存放子路径,domain表示服务器主机名。另外还有其他参数,读者可自行查阅http协议的cookie标准,有个参数需要特别说明下,secure参数表示是否使用SSL安全协议发送cookies,避免明文被网络拦截。这些变量保存在Tomcat中的类型都为MessageBytes,即以字节数组形式存储在内存中,好处就是避免多余的转码操作影响性能。