write buff操作
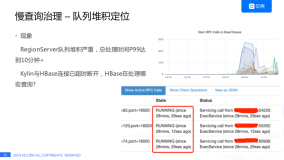
前两天在观察kafka消费数据的时候,发现HBase偶尔会报一个
org.apache.hadoop.hbase.RegionTooBusyException: org.apache.hadoop.hbase.RegionTooBusyException这种错误出来,从描述上看,是HBase写入太过频繁导致的。
首先来看我的写入操作代码:
/**
* 单条更新hbase数据
*
* @param tableName
* 表名
* @param put
* put对象
* @return 成功与否
* @throws IOException
*/
public synchronized boolean insert(String tableName, Put put) throws IOException {
Table table = getTable(tableName);
table.put(put);
table.close();
return true;
}这种方式写入单条数据,写入情况就是,没过来一条数据,就向HBase的region里面写入一条,操作太频繁。
解决方式:批量写入
首先,在hbase-site.xml配置文件中加入(也可以使用其他配置方式,如代码方式,但是不建议使用代码方式,发布时候还要重新编译,太麻烦):
<property>
<name>hbase.client.write.buffer</name>
<value>5242880</value>
</property>设置达到多少时候就行写入。
接着,修改单条写入时候的代码:
public synchronized boolean insert(String tableName, Put put) throws IOException {
HTable table = (HTable) getTable(tableName);
table.setAutoFlushTo(false);
put.setDurability(Durability.SKIP_WAL);//禁用hbase的预写日志功能
table.put(put);
return true;
}这样,如果调用这个insert方法,插入数据,虽然成功返回也不报错,但是只是在客户端做一个数据累计,等达到了我设置的5M之后,才进行一次性写入。虽然这样做减少了IO次数和网络传输次数,但是,一旦客户端出错或者HBase有问题,那么这些数据就丢失掉了,对于保证数据绝对不能丢失的这种情况,建议谨慎使用。
write buff分析
- Put操作
public void put(Put put) throws IOException {
this.getBufferedMutator().mutate(put);
if(this.autoFlush) {
this.flushCommits();
}
}观察HBase client的api,会发现,这里,如果是autoFlash,会立马执行一个操作,叫做flushCommits,在这个操作里面,会立即将数据写入数据库。
另外,在table进行关闭的时候,也会隐性的将数据写入数据库:
public void close() throws IOException {
if(!this.closed) {
this.flushCommits();
if(this.cleanupPoolOnClose) {
this.pool.shutdown();
try {
boolean e = false;
do {
e = this.pool.awaitTermination(60L, TimeUnit.SECONDS);
} while(!e);
} catch (InterruptedException var2) {
this.pool.shutdownNow();
LOG.warn("waitForTermination interrupted");
}
}
if(this.cleanupConnectionOnClose && this.connection != null) {
this.connection.close();
}
this.closed = true;
}
}
真正的写入操作,其实是发生在:
public void mutate(List<? extends Mutation> ms) throws InterruptedIOException, RetriesExhaustedWithDetailsException {
if(this.closed) {
throw new IllegalStateException("Cannot put when the BufferedMutator is closed.");
} else {
long toAddSize = 0L;
Mutation m;
for(Iterator i$ = ms.iterator(); i$.hasNext(); toAddSize += m.heapSize()) {
m = (Mutation)i$.next();
if(m instanceof Put) {
this.validatePut((Put)m);
}
}
if(this.ap.hasError()) {
this.currentWriteBufferSize.addAndGet(toAddSize);
this.writeAsyncBuffer.addAll(ms);
this.backgroundFlushCommits(true);
} else {
this.currentWriteBufferSize.addAndGet(toAddSize);
this.writeAsyncBuffer.addAll(ms);
}
while(this.currentWriteBufferSize.get() > this.writeBufferSize) {
this.backgroundFlushCommits(false);
}
}
}
当当前的数据达到我们设置的buff size的时候,才会进行一个真正的写入操作。
PS:如果想让数据立即写入,可以显示调用flushCommits或者调用close方法。