如果你想使用Kubernetes来构建你的应用程序环境,通过OpenStack来部署Kubernetes其架构是一种推荐的方式,本文将与大家分享Kubernetes在OpenStack上的编排方式与其优化方法。
以下介绍5种针对Kubernetes的调优方式,希望对大家有所帮助。
接下来让我们从架构分析开始,了解为什么需要这样的架构存在,解决什么样的问题。接着了解优化的目的,我们深入探讨几个优化方式与选项。结合部分实际案例或测试来优化后的改善。最后探讨后续发展与计划。
架构分析
容器的存在是为了解决无状态(stateless)的服务占用系统资源的问题。针对网络应用程序来说,即能减少虚拟化所带来的消耗,成为效能优化的一大亮点。在容器之上应用程序仍需与多个容器共存,甚至互相通信。
因此Kubernetes、Mesos、Swarm等容器编排服务就成为新世代架构的宠儿。 Kubernetes概念架构如下图所示:
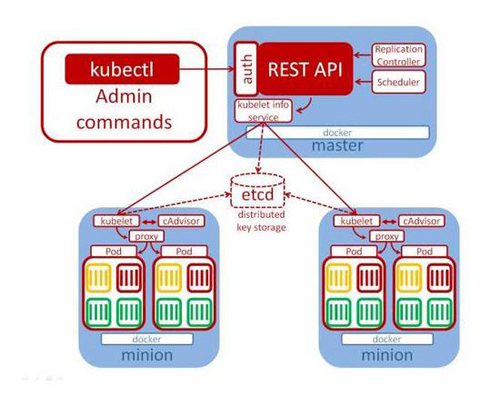
在Kubernetes架构下,提供docker容器网络与周期管理。通过COE(Container Orchestration Engine)管理的容器群,不但享受便利,也拥有快速编排应用程序架构的优势。
但通过下图(Cloud Native Landscape by Cloud Native Computing Foundation)可以认识到:Kubernetes还需要建立在一个可以良好地承载如此多样性服务的基处建设(即IaaS),而在图中最底下的基础架构(Infrastructure)你会选择那个平台?

以现今的云应用,相信多数私有云会选择以OpenStack作为基础框架,公有云也有不少案例使用OpenStack。而在选好的框架上承载相应的应用程序。
通过上面一起思考出的组合,若各位已经熟悉Magnum开源项目或是企业Kubernetes产品(例如ESContainer),其提供你在OpenStack架构上想要的Kubernetes框架的方式。
另外此架构也还有几个优点供大家参考:通过此架构可以达成Kubernetes全自动化管理,通过此架构可以提供完整多租户框架。
在这样的整体架构规划下,可以深入讨论以下几大重点:网络、运算、储存与编排。想必大家通过之前网络调优的干货(http://www.easystack.cn/en/technical_share/748/ )与NUMA相关处理器技术干货(http://www.easystack.cn/en/ technical_share/700/ )已经对自己的环境的基础架构有相当的了解,甚至已经着手进行优化。
接下来正是文章想要突显的重点,如何从编排下手让OpenStack上的Kubernetes加速?如何调优?当你已经千方百计优化了你的应用程序时,还有那些方式可以让效能更上一层楼?
优化项目-调优编排
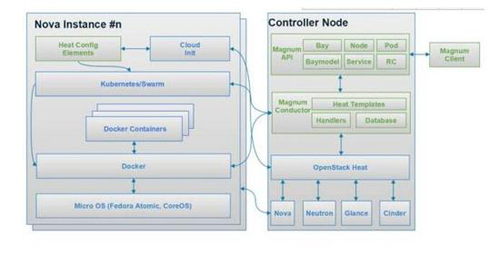
编排项目对于在OpenStack构建任何应用程序都具有重要角色,在下图(Magnum的架构图)中可以看见Heat (编排服务)对于整体流程的重要性。通过Heat脚本可以布署集群与安装任何应用程序于集群上。因此选择调优Heat绝对是值得参考的选项。
调优1:开启convergence模式
若你的OpenStack环境已经到了Mitaka或是以上版本。则建议你将convergence模式打开(若版本为Newton以上版本,预设已经是开启)。打开方式为在`/etc/heat/heat.conf`档案下加入`convergence_engine = True`的选项。
开启后对于操作不会有任何改变,使用者仍可以用原先的操作模式与脚本建立编排资源。原先已经建立的编排资源则会维持在非Convergence模式下继续运行。而新建立的编排资源则会以Convergence模式维运。
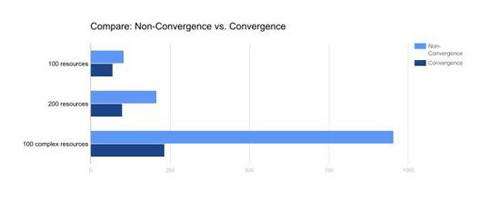
下图为比较建立100个简单的资源,200个简单的资源,与100个复杂资源时在Convergence模式或是非Convergence模式下的效能。可以观察到,越复杂的资源越需要更多的时间来完成,越容易在Convergence模式下获得大幅的改善。
尤其是针对像是Kubernetes等需要建立多台Nova Instance (虚拟机或裸机)的状况下,通过模式转换而获得的效率改善理应更显著(Kubernetes一般架构属于复杂度较高的资源,因此可以参考图中复杂度高的状况比较表)。
什么是Convergence模式?
谈到这里,应该有不少开发者对Convergence相当陌生。 Convergence比起旧架构在服务之间的差异只有新增了一个worker服务。但是实际上程序流程完全不同。如果我们如下指令建立一个Kubernetes 群集。

如果是旧有的架构指令会被转为API call,再通过RPC交由其中的一个后端Engine服务由头到尾处理整个Kubernetes资源建构。
但如下图在Convergence模式下,Kubernetes脚本抵达后端服务(Engine)时,会依照资源立刻被分成单一工作,交付给其他后端服务并行执行。
也就是说,若后端服务数量允许,所有的Kubernetes master与minion都可以并行运行在独立的后端服务,并且只需要你花费部署一台节点的时间,就可以将整个集群都建置完毕。
过程中Heat服务会在数据库中建立一张叫做Syncpoint的表,用来确认与取得操作的权限。并且存入资源相依性的连结数据以保证有资源创建流程(像是确保Cinder Volume挂载操作,必须在Nova将Kubernetes节点与Cinder Volume创建出来后才能执行)。
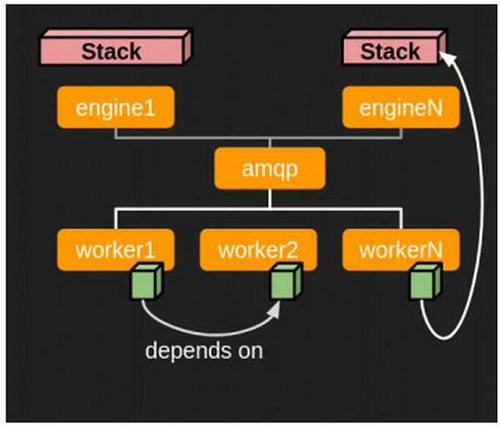
调优2:调整`num_engine_workers`
Engine worker数量调整,指的就是我们在调优1时提及的后端服务数量。通过下图架构可以看到,当API服务收到请求,并通过RPC往后方传送时,是在多个Engine worker中,由抢先接收到者,作为处理该请求的后端。
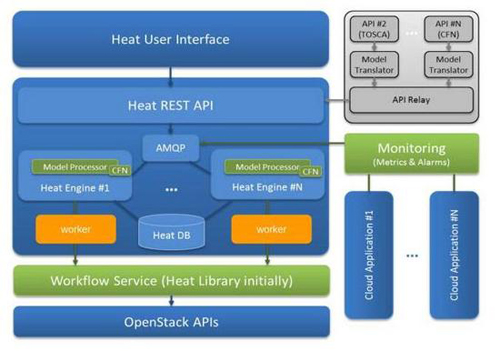
而这个调优设定可以用来决定每一个实体的Heat后端节点上要跑几个后端服务程序。如若环境(在`/etc/heat/heat.conf`文件)尚未设定此参数,预设是按照CPU数量来调整单一节点上Heat的服务程序数量。
但是注意到,若你的电脑为HPC时建议将数量调高,因为你拥有较为强大的网络、运算、与储存资源,可以尝试由1:1.5(cpu:num_engine_workers)开始测试效能,在往上调整,直到你的Kubernetes集群的布署效能达到顶峰。
相对地,若你的CPU数量过多,其他部分的资源并未规划为高效能状况(可能发生在用来提供运算的节点上),建议尝试1.25:1(cpu:num_engine_workers)开始测试效能,并往下调整(num_engine_workers数量),直到你的环境取得更好的整体效能。
注意到单一节点上的编排服务程序数量,并不等于多节点上的整合。因此调整到适当的数量,也等同于提供其他程序(RPC、数据库、其他服务程序)更多资源的使用空间。
尤其是像布署Kubernetes环境,将会同时调用Cinder管理储存, Neutron管理网络Nova管理虚机或裸机。因此资源分配更应该微调以获取更好的整体效能。
调优3:开启高速缓存
多数的OpenStack服务都具有一定数量的缓存机制,若内存空间允许建议挑选部分服务(比如编排服务)开启缓存机制,开启方式为将缓存设定写入heat.conf内。
至于写入选项可参考网站:https:// docs .openstack.org/developer/oslo.cache/opts.html 。若无特别想设定的参数,可以直接在[cache]下新增enabled=True即可。
至于为什么在此特别提及此设定,因为当你要布署或是扩展你的Kubernetes集群时,在资源编排上都会是以资源群组为单位,比如说要再扩展出新的50台Kubernetes minion节点。
在资源编排时,这50台属于同一Kubernetes丛集的minion节点将会被视为同一个资源群集,并在编排时一同处理。因此若能将高速缓存开启,在这案例上就可以直接节省49次等同于98%的部分操作。
目前在编排服务内,以下几个主要环节已经设有快取机制,包含Stack信息数据,Resource信息数据,Constraint数据(通过呼叫其他项目CLI以认证部分参数。例如当K8S master参数有Floating ip时,Constraint就会通过Neutron CLI找寻Floating ip数据作为参数认证依据)等。
调优4:允许OpenStack直接操作Kubernetes
在实际使用Kubernetes时,许多时候需要临时或一次性变更多个 Kubernetes集群,或是对单一个大型的Kubernetes集群进行多次操作或复杂操作,其实也可以纳入OpenStack管理范围作一次性操作,进而完成所有任务。
在编排服务中有能安装与管理应用程序的能力,在提供镜像时,只需要在里面多加入kubelet hook就可以了。后续只需通过更改编排脚本即可进行操作。
对于不知道hook是什么的读者,可以理解基本上它就是一个在os-collect-config协助将文件(例如yaml文件)转入Kubernetes节点上之后,通过节点上kubelet指令执行操作。流程如下图所示:
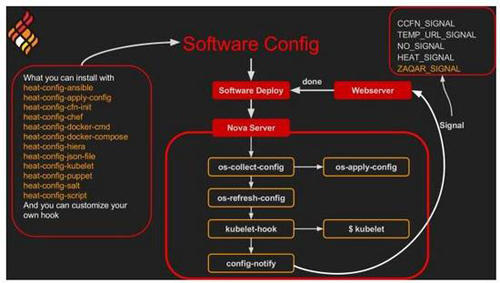
当你计划开发Kubernetes自动化管理时,除了将kubelet hook加入镜像内,也要注意到kubelet执行后,必须要能够发送消息给Heat或Zaqar等等(看你在编排脚本撰写时的设定),因此请务必打开部分防火墙设定(像是80或8080等等)允许消息发送。
Heat的自动化软件布署与设定,通过同一个用来设定K8S的脚本即可设定相关资源。如果你想要将软件布署加入你的K8S脚本中,可以参考以下脚本片段。
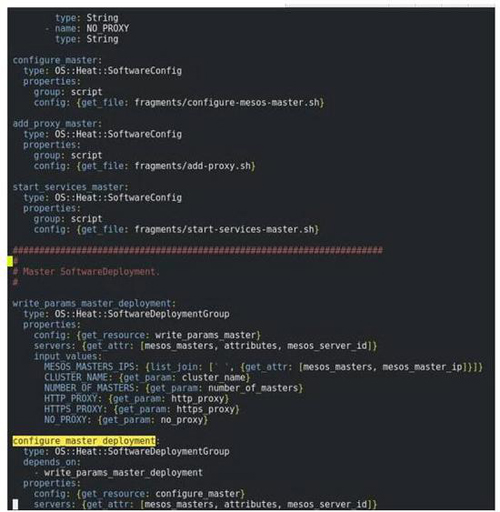
当中`configure_master_deployment`就是可以将单一布署脚本应用于多个节点上的`OS::Heat::SoftwareDeploymentGroup`资源。
其工作会将`OS::Heat::SoftwareConfig`中设定的脚本与脚本形态(Ansible, script, Puppet, Kubelet, etc.)通过K8S节点(你的OS::Nova::Server资源)中的os -collect-config将脚本信息拉进节点中(此为随时监听动作,可以调整监听区间,预设为30秒),再通过Kubelet hook呼叫Kubelet指令,执行脚本。
任何执行结果或是错误状况。都会通过消息回传给Heat服务。另外有关于详细kubelet hook信息可以参考:https : // github . com / openstack / heat-agents / tree / master / heat - config - kubelet 。
在编排脚本上加入:
...即可以操作kubelet ,你也可以将cofig部分换成yaml文件输入。至于在编排脚本上完整的使用方式,可以参考https : // github . com / openstack / heat - templates / blob / master / hot / software - config / example - templates / example - kubele - template . yaml
调优5 :调优镜像
对于Kubernetes的优势之一即将服务都转进容器内执行,然而目前许多大型环境遗忘了应该建制 Kubernetes 的镜像优化。目前有几家知名的欧洲大型研究机构,就在对他们 OpenStack 云上的 Kubernetes ,进行这项优化。
优化方向有2:
1. 替代原先使用的镜像,将更适合容器的小型镜像作为整体建置选择。
2.将上面提及编排时所需要的hooks加入映像档。在此提供相关的 Dockerfile 作为参考。
总结
通过将上面5项调优(调优1:开启convergence模式;调优2:调整`num_engine_workers`;调优3:开启高速缓存;调优4:允许OpenStack直接操作Kubernetes;调优5:调优镜像)应用到你的K8S环境中,在执行布署或扩展(或缩编)时,会产生明显的效能改善。
当K8S布署下去后,实体网络调整变得非常困难。若你选择运用OpenStack编排管理,在任何环境中改变节点信息,包含网络,群集实体配置,储存等等就会变成更为简单的操作。
你也可以通过专门负责资源管理的编排服务,强化资源布署效能。因为你绝对不可能将你的运营中的容器化应用程序布署在只有一个单一节点的K8S,你更不希望因为任何人员操作时修改遗漏,导致整个群集停止服务。通过编排就变成是个较为符合自动化目标的选项。
除了上面5项建议外,也鼓励你将你的问题、想法、解法、或是其他任何帮助发到社区上或是联系我们,由社区作为源头,我们有能力直接改变源头以继续强化Kubernetes与OpenStack的整合与优化,我们努力将源头技术优化了,不久一定产生更多的优化选项。最后受惠的,相信就是你正在运营的环境。
本文作者:佚名
来源:51CTO

