介绍
深度学习的原理?局部响应归一化的作用?兄弟今天不是来讨论这个的,那都是科学家和算法同学的事儿。作为一个深度学习引擎,使命只有一个——就是快速和准确的计算。那怎么才能快呢?在编程技能和算法技能没有蜕变的情况下,使用GPU是一个方便的法门。对于iOS来说,就是使用Metal,对于iOS10+iPhone6以上,那就更厉害了,可以使用Metal Performance Shaders,就是苹果写好了卷积给你用,性能不是一般的强悍。对于android,情况变得有些复杂,谷歌本来打算推他自己搞的RenderScript,可惜没成功,这玩意儿性能不行,看样子谷歌自己都不玩了,OpenCL还不错,不过这玩意儿的调优可真不是一般的麻烦,同样的运算就算是姿势偏差了一点点,那性能也是天差地别。什么姿势这么重要?比如col-major, row-major啦,说到底,就是内存的存取分配问题。
业务应用
先把实现细节摆一边,放几个实际业务的录屏大家感受下:
一般人都会问一个问题,有什么计算是必需在前端做而不能在后端做?但反过来也可以问另外一个问题——有什么计算是必需在后端做而不能在前端做?如果网络够快,那么都可以放在后端做,如果前端运算够快,那也都可以放在前端做。(别提检索数据,那是另外一回事)
扫立淘
在手机淘宝拍立淘内,我们增加了智能识别场景对端上智能进行落地。
用户将摄像头对准要识别的物体时,会实时对相机取到的帧数据进行检测,并绘制出黄色瞄点提示用户当前镜头内的主体。这样可以使取得的图片主体更加明确清晰,提高召回结果的准确率。
当搜索被触发后,端上会立刻对当前最后一帧图像进行检测并绘制识别区域。
扫商品/扫logo
业务方提供要识别的素材,可以是若干个品牌logo,也可以是若干个商品图片。我们会提供扫码页面给业务方投放到任何运营位。进入扫描页后,用户对准logo或者商品,我们会在端上进行特征提取和特征比,并将结果返回给H5页面来实现业务方要求的各种效果。
速度对比
android
图中所列数据都是在nubia Z9(15年出的一款旗舰机,CPU: qualcomm snapdragon 810, GPU:Adreno 430)手机上执行googlenet测得, low is better.
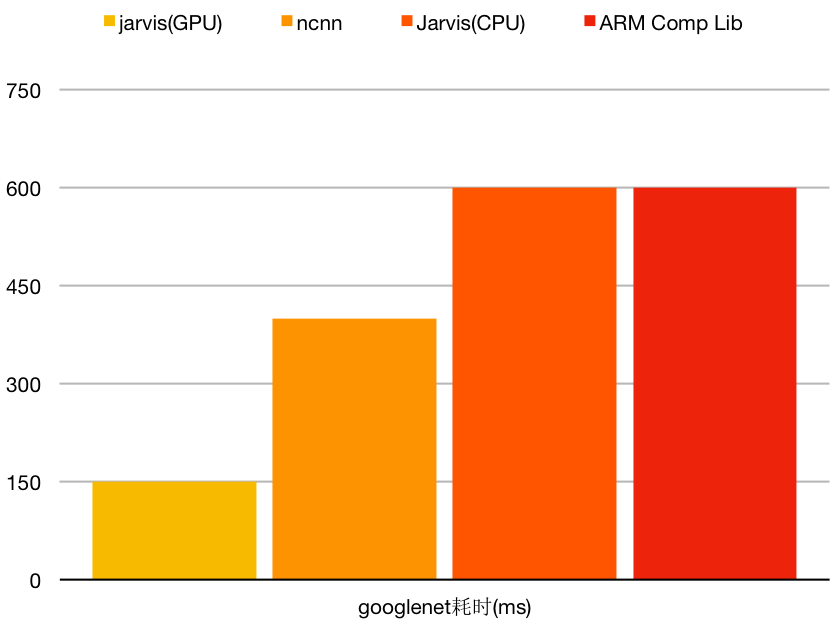
Jarvis GPU implementation的性能是ncnn的 两倍以上!
zhe sh
CPU使用占比:
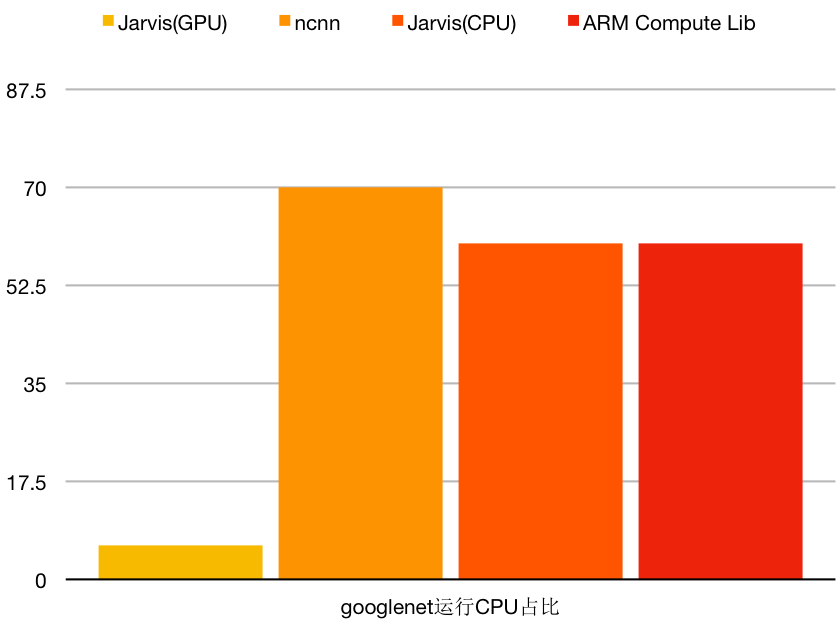
10分钟耗电:
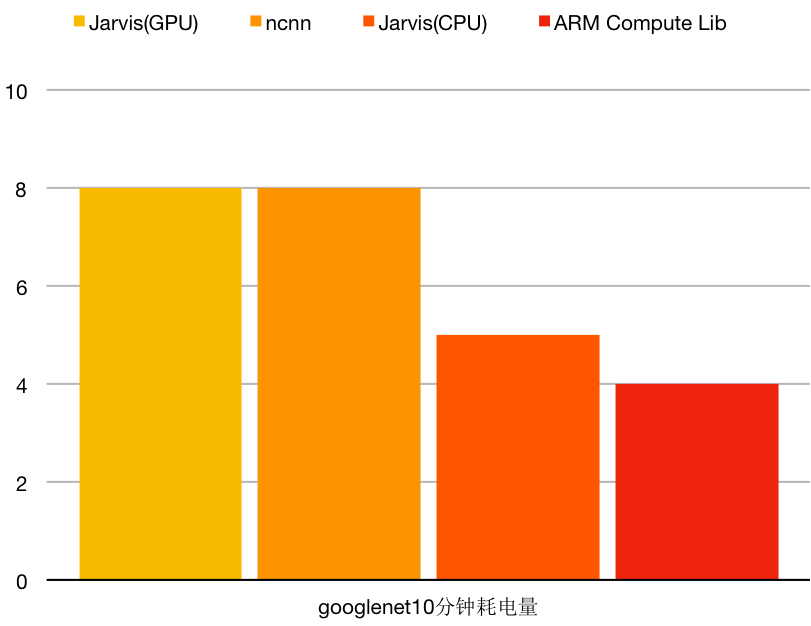
虽然Jarvis GPU的CPU占比很低,不过GPU看起来也是特别耗电的主儿。但在这同等的时间和耗电量之下,Jarvis GPU执行的googlenet次数可是ncnn的2倍以上。
Jarvis googlenet OpenCL实现分层耗时:
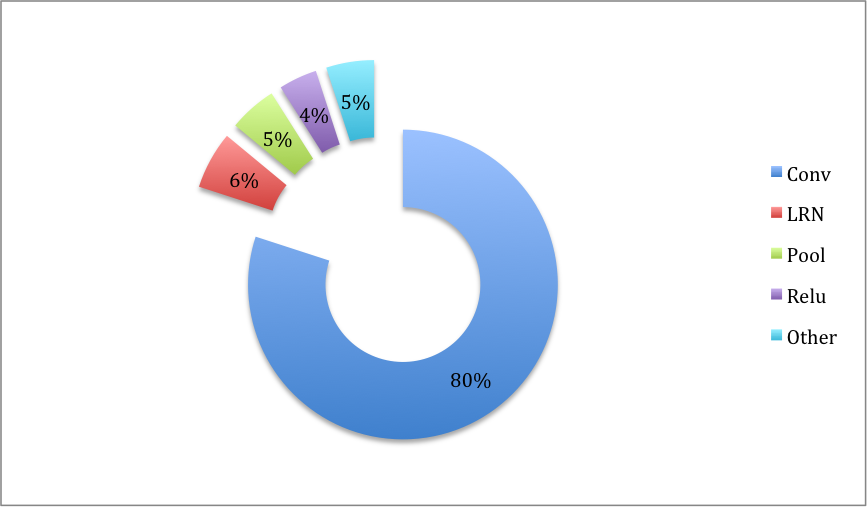
时间都是被卷积给吃了。 如果要继续优化,那就继续瞄准卷积进行射击。
另外,仅仅两层LRN就耗掉了相当一部分时间,主要是里面的幂函数太费时了
备注:
- Jarvis CPU使用Eigen OpenMP,4线程
- ARM Compute Library使用v17.06,即6月份的版本。v17.10还要更慢。ARM Compute Library的OpenCL实现在高通GPU上运行报错。就目前来说, ARM的CPU实现的表现令人失望,OpenCL的实现在MaliGPU下的表现有待验证。
- 以上这些作为对比的库都是使用他们所带示例代码的方式来构建的网络,也就是说就算他还有什么性能调优的参数,我也是不知道的
在一般的机器上,如果不使用GPU加速,googlenet在端上基本不可用,太慢。
iOS
测试机器iPhone 6s Plus
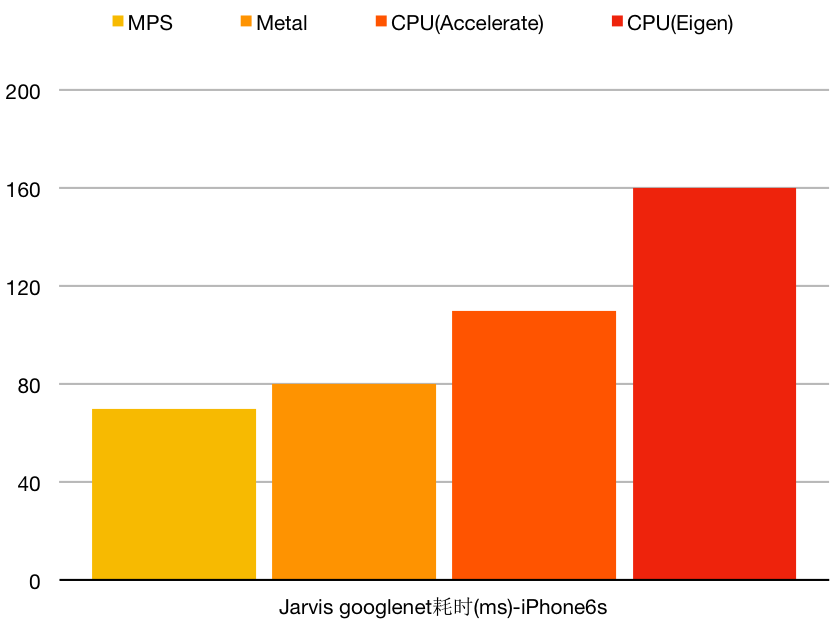
- 同样的CPU代码(使用Eigen,再往下说是neon),在不开启OpenMP即多线程的情况下,在iPhone6s上要比高通810快5倍,即使在810上开了omp也是差了3-4倍。
- 仅仅把卷积算子中的gemm从Eigen换成Accelerate Framework实现,速度就提升了一大步。再次验证了一个道理,现在外部开发怎么都玩不过系统内部的实现。
- GPU中Metal的实现,无论如何都和系统自带的MCNN实现有相当的差距。
- MPS的性能是逆天的
架构设计
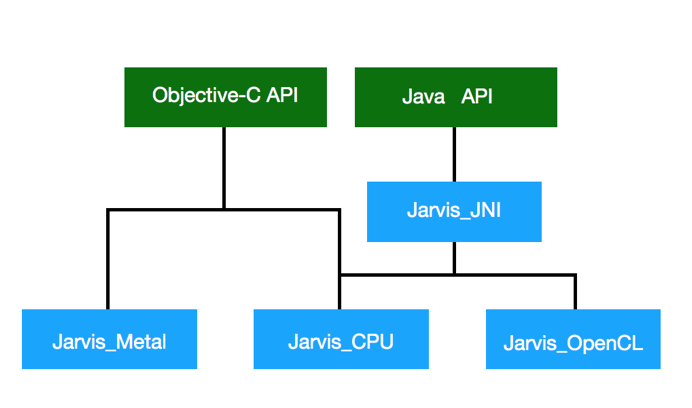
- model格式:目前采用protocol.json+二进制model数据文件的方式。框架提供了工具可以将caffe2的格式转为jarvis格式。
- 为了简单的缘故,现在所有层的输入和输出channel都必需是4的倍数,大部分的网络都是如此。对于第一层输入,一些网络接受3channel,框架提供了工具将model扩展为4channel,即在后面追加0。
- 网络构建:系统会优先使用GPU的Operator,如果相应Operator无GPU实现则会降级使用CPU。 系统会负责数据在CPU和GPU之间的传递,调用方是当然不用操心这些 小事 的。
- 在安卓上, 分为了三个动态链接库,Jarvis_CPU, Jarvis_OpenCL, Jarvis_JNI。调用方可以根据需要打包相应的so。这样也使得在手机不支持opencl时不至于整个jarvis库都加载失败。
- Javis_CPU,iOS和android基本上使用了共同的代码。不过iOS还有一个accelerate库的实现,在编译时选择。
接口设计
Java:
Session session = new Session(protocol, modelPath);
Tensor input = session.input(0);
float[] input_data = new float[input.size()];
// fill input_data stuff...
input.write(input_data);
session.run();
Tensor output = session.output(0);
float[] output_data = new float[output.size()];
output.read(output_data);Objective-C
JVSSession *session = [[JVSSession alloc] initWithProtocol:protocolData
modelPath:modelPath];
[[session inputAtIndex:0] write: input_data];
[session run];未来演化
虽然所有的深度学习框架都在尽力提高自己的性能,但要与硬件厂商的实现相比那还是有相当大的差距。那硬件厂商的SDK有多快?我不是针对谁,但上面所有的这些库在高通骁龙的SNPE和华为的Mate10深度学习引擎面前都是渣。所以,Jarvis——对于任意一款深度学习框架来说都是如此——的存在价值就是不管一款手机是否带有厂商自己的深度学习引擎,也不管这个深度学习引擎的API有多么奇葩,都使用简单统一的接口将之抹平,让天下的手机没有难搞的深度学习。
还是说几个眼前的点吧:
- 首先要提高CPU实现的性能,毕竟CPU是兜底的。首先就是去掉Eigen,又大又慢。然后就是借鉴了, NNPACK,ncnn, xNN, 嗯嗯。不过使用neon的优化还是有很多的潜力可挖,大有可为。
- 其次要提高OpenCL实现在非高通GPU上的性能,现在这个版本的性能优化是针对Adreno GPU做的,优化完成后发现在Mali GPU上性能降了一大截,接下来要再次针对Mali优化,最终的目的是要做到针对不同的GPU有不同的性能调优参数。好多工作。
- 尝试同时使用CPU和GPU,这个方案的难点在于数据在CPU和GPU之间的来回传递本身也需要耗费时间。一个方案是使用CPU/GPU共享内存,对于Metal来说,使用了共享内存写入一端的数据即对另外一端可见。对于OpenCL来说,虽说不用再拷贝内存,不过依然要使用Map/Unmap来同步内存。
- 二值网络的应用及实现优化,现在使用float32,使用float16/Int8会不会好一点?参考iDST的BNN
- 稀疏化网络的应用及实现优化,现在算法团队已经可以在精度损失非常小的情况将网络稀疏化到80%以上,对于这种网络,有没有更优的计算方案?参考支付宝的xNN
这是一份表格视图:
耗时对照表,单位是ms,low is better。
| Jarvis(GPU) | Jarivs(CPU) | Caffe2 | ncnn | mdl | |
|---|---|---|---|---|---|
| Samsung S8 | 30 | 80 | 110 | 120 | 150 |
| Huawei P10 | - | 110 | 160 | 140 | 180 |
| iPad pro | 23 | 56 | 140 | 65 | - |
| iPhone 6sp | 35 | 58 | 160 | 80 | - |