更多深度文章,请关注:https://yq.aliyun.com/cloud
Tensorflow可能是最受欢迎,增长最快的机器学习框架。在Github拥有超过70000个点赞,并得到Google的支持,不仅拥有比Linux更多的点赞,还拥有大量的资源。
如果那都不能激起你的兴趣,我不知道还会有什么可以引起你的兴趣。
如果你以前一直在关注机器学习101系列,你会注意到我们已经使用sklearn框架来实现我们的模型。然而,当我们开始勇于进入神经网络,深度学习和一些算法的内部运作时,我们将开始使用Tensorflow框架,该框架具有访问更多低级API的能力,为我们提供在模型上更细致的控制。
因此,我们将花费一些时间熟悉Tensorflow及其设计理念,以便我们在后续教程中可以开始使用它,而无需介绍。
在本教程中,我们将讨论:
总体设计理念
可视化
涵盖常见用例的示例
它与机器学习有什么关系?
在官方白皮书中,Tensorflow被描述为“用于表达机器学习算法的接口和用于执行这种算法的实现”。 它比其他框架的主要优点是在各种设备上执行代码非常容易。这与它在开源之前的发展动机有关。 Google最初开发了Tensorflow来弥合研究与生产之间的差距,希望从研究到生产都不需要对代码进行编辑。
|Tensorflow是用于表达机器学习算法的接口,以及用于执行这种算法的实现。
为了实现这一点,Tensorflow在幕后实现一个计算图; 在你的代码中,你只是定义那个图:张量的流动。
那么,什么是张量?
就像一个向量可以看作是一个数组或列表,标量(普通数字1, 2,PI),那么矩阵可以看作数组向量,张量可以认为是矩阵数组。所以张量实际上是一个n维矩阵。事实上,正如我们在编码示例中所看到的那样,这种架构在使进行机器学习时非常有意义。
流动是什么呢?
流动是张量如何在网络中传递。当张量传递时,它们的值和形状由图运算更新。
做个比喻,你可以把图形想象成一个拥有一系列工作站的汽车工厂。一个站可以装上汽车的轮子,另一个安装变速箱。然后,流程描述一个汽车骨架必须采取的路线,以便成为一个全功能的汽车。这个比喻中传递的张量是汽车原型或骨架。
安装Tensorflow
你可以使用以下命令使用pip安装Tensorflow:
pip install tensorflow或者如果你有一个GPU:
pip install tensorflow-gpu请注意,如果要安装GPU版本,则需要安装CUDA和cuDNN。
撰写本文时,Tensorflow(v1.3)支持CUDA 8和CUDNN 6。
安装Tensorflow后,你可以使用以下方法验证所有操作是否正常:
# Figure out what devices are available
from tensorflow.python.client import device_lib
def get_devices():
return [x.name for x in device_lib.list_local_devices()]
print (get_devices())['/cpu:0', '/gpu:0']有关详细信息,请参阅安装页面。
Tensorflow的原子
我们已经讨论过Tensorflow是否是张量的流动,但是我们没有详细介绍。为了更好地证明架构的正确性,我们将详细阐述这个问题。
三种类型的张量
在Tensorflow中,有三种主要的张量类型:
- tf.Variable
- tf.constant
- tf.placeholder
看一看其中的每一个,讨论它们之间的差异,以及何时使用这些,是值得的。
tf.Variable
tf.Variable张量是最直接的基本张量,并且在很多方面类似于纯Python变量,因为它的值是很好的变量。
变量在整个会话控制期间保留其值,因此在定义可学习的参数(如神经网络中的权重)或其他任何将随代码运行而改变的参数时很有用。
你可以按如下方式定义一个变量:
a = tf.Variable([1,2,3], name="a")在这里,我们创建一个具有初始状态[1,2,3]和名称a的张量变量。 请注意,Tensorflow无法继承Python变量名称,因此,如果要在图形上有一个名称(稍后将会有更多的名称),则需要指定一个名称。
还有几个选项,但这只是为了涵盖基础知识。与这里讨论的任何事情一样,你可以在文档页面上阅读更多信息。
tf.constant
tf.Constant与tf.Variable非常相似,有一个主要区别,它们是不可变的,就是值是恒定的。
tf.Variable张量的用法如下:
b = tf.constant([1,2,3], name="b")当你有一个不通过代码执行改变的值,例如表示数据的某些属性,或者在使用神经网络来存储学习速率时,就使用这个。
tf.placeholder
最后,我们解释tf.placeholder张量。 顾名思义,该张量类型用于定义您没有初始值的变量或图形节点(操作)。然后,你可以延迟设置值,直到实际使用sess.run进行计算。这在定义网络时可用作培训数据的代理。
运行操作时,需要传递占位符的实际数据。是这样做的:
c = tf.placeholder(tf.int32, shape=[1,2], name="myPlaceholder")
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
res = sess.run(c,
feed_dict={
c:[[5,6]]
})
print (res)[[5 6]]请注意,我们先通过元素类型(这里是tf.int32)的非可选参数来定义占位符,然后使用矩阵维符号定义形状。 [1,2]表示具有1行和2列的矩阵。 如果你没有研究线性代数,这可能看起来很混乱:为什么表示宽度之前的高度?并且不是[1,2] a 1乘以2的矩阵本身的值1和2?
这些是有效的问题,但深入的答案超出了本文的范围。 然而,告诉你它的要点,奇怪的符号形式显然有一些很整齐的记忆特性的矩阵运算,[ 1,2 ]也可以被看作是一个由两个矩阵本身。Tensorflow使用像符号这样的列表,因为它支持n维矩阵,因此非常方便,我们将在后面看到。
你可以在这里找到支持Tensorflow数据类型的完整列表。
当我们用sess.run评估c的值时,我们使用feed_dict传入实际的数据。 请注意,我们使用Python变量名称,而不是给予Tensorflow图形的名称来定位占位符。 同样的方法也扩展到多个占位符,其中每个变量名映射到相同名称的字典键。
定义形状时的通配符
有时候,当你定义时,你不知道一些,或者一个占位符的整个形状。例如,你可以在训练时使用变量批量大小,这是通配符进入的地方。
通配符基本上允许你说“我不知道”给Tensorflow,并且让它从传入张量推断形状。
-1和None有什么区别?
老实说,我试图弄清楚这个的答案,但是我没有找到任何记录的差异,而在Tensorflow的源代码中我挖掘的小部分也没有产生任何结果。 但是,我遇到了一些例子,其中一个会引发错误,而另一个则不会。
在这两个中,None似乎对我来说使用更好,所以我一直使用,如果我收到与占位符大小相关的错误,我尝试将其更改为-1,但我觉得它们应该是等价的。
为什么不只是通配符?!
具有明确的形状可以帮助调试,因为很多错误将被捕获在“编译时间”,而不是在训练的时候,这使你更快地发现错误,并且它确保错误不会默默地爬行(至少它尝试了)。
所以为了避免以后的麻烦,你应该只使用通配符来描述一些变量,如输入大小,而不是一些静态的,如网络参数大小。
基本计算实例
了解了变量如何工作,我们现在可以看看如何创建更复杂的交互。
Tensorflow中的图形包含互连操作(ops)。OP本质上是一个函数,即任何需要输入并产生某些输出的函数。正如我们之前讨论过的,Tensorflow的默认数据类型是张量,所以操作可以说是进行张量操作。
看一个非常基本的例子,乘以两个标量,可以这样做:
a = tf.Variable(3)
b = tf.Variable(4)
c = tf.multiply(a,b)
print (c)Tensor("Mul:0", shape=(), dtype=int32)print (a)
print (b)<tf.Variable 'Variable_4:0' shape=() dtype=int32_ref>
<tf.Variable 'Variable_5:0' shape=() dtype=int32_ref>请注意,当我们打印结果时,我们得到另一个Tensor,而不是实际结果。另外,请注意,变量具有shape(),这是因为标量是零维张量。最后,因为我们没有指定一个名字,所以我们得到名字'Variable_4:0'和'Variable_5:0',这意味着它们在图形0上是变量4和5。
要获得实际结果,我们必须在会话的上下文中计算值。 这可以这样做:
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) # this is important
print (sess.run(c))12你也可以使用tf.InteractiveSession,如果你使用像IDLE或者jupyter笔记本这类的,这很有用。 此外,还可以通过声明sess = tf.Session()来开始一个会话控制,然后使用sess.close()关闭它,但是我不建议这样做,因为很容易忘记关闭会话会话控制, 使用此方法作为交互式会话可能对性能会有影响,因为Tensorflow真的喜欢占用尽可能多的资源(在这方面有点像Chrome)。
我们首先创建一个向Tensorflow发出信号的会话,我们要开始进行实际的计算。 在幕后,Tensorflow做了一些事情; 它选择一个设备来执行计算(默认情况下是你的第一个CPU),并初始化计算图。 虽然你可以使用多个图,但通常建议仅使用一个,因为不通过Python(我们建立的是慢的),两个图形之间的数据无法发送。即使你有多个断开连接的部件也是如此。
接下来我们初始化变量。 为什么在开始会话时不能这样做,我不知道,但它填充了图中变量的值,所以我们可以在我们的计算中使用它们。 这是这些小烦恼之一,你必须记住每次你想要计算的东西。
你可能记得,Tensorflow真的很懒,想尽可能少做。因此,你必须明确告诉Tensorflow来初始化变量。
Tensorflow是懒的
了解更多细节可能是有用的,因为了解如何以及为什么选择Tensorflow非常重要。
Tensorflow喜欢延长计算时间。 它是这样做的,因为Python很慢,所以它想要在Python之外运行计算。 通常,我们使用诸如numpy之类的库来实现这一点,但是在Python和优化的库之间传输数据(如numpy)是非常昂贵的。
Tensorflow通过首先使用Python定义一个图而不做任何计算,然后将所有数据发送到Python之外的图形,使用高效的GPU库(CUDA)可以运行。 这样,将数据传输所花的时间保持在最低限度。
因此,Tensorflow只需要计算实际需要的图形部分。当你运行操作来发现计算所依赖的所有依赖项时,它通过网络传播回来,并且仅计算它们。它忽略了网络的其余部分。
请思考以下代码:
a = tf.Variable(3)
b=tf.Variable(4)
c = tf.multiply(a,b)
d = tf.add(a,c)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
c_value = sess.run(c)
d_value = sess.run(d)
print (c_value, d_value)12 15这里,我们有两个原始值a和b,以及两个复合值c和d。
c依赖于a和b。
d依赖于a和c。
那么当我们计算复合值时会发生什么? 如果我们从最简单的c开始,我们看到它依赖于原始值a和b,所以当计算c时,Tensorflow通过反向传播发现(这与通过神经网络的反向传播不同),获取这些原始值并将它们相乘在一起。
d的值以类似的方式计算。 Tensorflow发现d是依赖于a和c的值的加法运算,所以Tensorflow获取它们中的每一个的值。 对于值a,一切都很好,而Tensorflow可以使用原始值,但是使用值c,Tensorflow发现它本身是一个复合值,这里是依赖于a和b的乘法运算。 Tensorflow现在可以获取a和b的值,它用于计算c的值,因此可以计算d的值。
|Tensorflow递归地计算操作的依赖关系以找到其计算值。
然而,这也意味着一旦计算出值就被丢弃,因此不能用于加速未来的计算。 使用上面的例子,这意味着在计算d的值时,即使我们刚刚计算出c并且自那以后没有改变,c的值被重新计算。
下面,进一步探讨这个概念。 我们看到,当c的结果在计算后立即被丢弃,可以将结果保存到一个变量(这里是res)中,当这样做时,甚至可以在会话关闭后访问结果。
12 Tensor("Mul:0", shape=(), dtype=int32)with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
res = sess.run(c)
print (res,c)12 Tensor("Mul:0", shape=(), dtype=int32)选择设备
你可以选择使用以下模板在特定设备上计算某些操作:
with tf.device("/gpu:0"):
# do stuff with GPU
with tf.device("/cpu:0"):
# do some other stuff with CPU在验证Tensorflow正确安装时,您可以使用任何可用的设备名称字符串替换字符串“/ gpu:0”和“/ cpu:0”。
如果你安装了GPU版本,Tensorflow将自动尝试运行GPU上的图形,而无需明确定义它。
|如果一个GPU可用,它将优先于CPU。
当使用多个设备时,值得考虑的是设备之间的切换相当慢,因为所有的数据必须被复制到新设备的内存中。
分布式计算
因为一台电脑是不够的。
Tensorflow允许分布式计算。 我想像这对我们大多数人来说是不相关的,所以请随便跳过这个部分,但是,如果你相信你可能会使用多台电脑来解决问题,这一节可能对你有所帮助。
Tensorflow的分布式模型可以分为以下两个部分:
服务器
集群
这些类似于服务器/客户端模型。 当服务器包含主副本时,集群包含一组作业,每个作业都有一组任务是实际的计算。
管理具有一个作业的群集的服务器和两个共享两个任务之间的负载的工作人员可以如下创建:
cluster = tf.train.ClusterSpec({"my_job": ["worker1.ip:2222", "worker2.ip:2222"]})
server = tf.train.Server(cluster, job_name="my_job", task_index=1)
a = tf.Variable(5)
with tf.device("/job:my_job/task:0"):
b = tf.multiply(a, 10)
with tf.device("/job:my_job/task:1"):
c = tf.add(b, a)
with tf.Session("grpc://localhost:2222") as sess:
res = sess.run(c)
print(res)可以像这样创建相应的worker-client:
# Get task number from command line
import sys
task_number = int(sys.argv[1])
import tensorflow as tf
cluster = tf.train.ClusterSpec({"my_job": ["worker1.ip:2222", "worker2.ip:2222"]})
server = tf.train.Server(cluster, job_name="my_job", task_index=task_number)
print("Worker #{}".format(task_number))
server.start()
server.join()如果将客户端代码保存到文件中,可以通过键入终端来启动工作人员:
python filename.py 1这将启动两个监听my_job作业的任务0和任务1的工作人员。 一旦服务器启动,它会将任务发送给将返回到服务器的答案的工作人员。
要更深入地了解Tensorflow的分布式计算,请参阅文档。
保存变量(模型)
在计算完这些困难的参数后,不得不扔掉它们,这并不有趣。
幸运的是,使用保存对象,在Tensorflow中保存一个模型非常简单,如下例所示:
a = tf.Variable(5)
b = tf.Variable(4, name="my_variable")
# set the value of a to 3
op = tf.assign(a, 3)
# create saver object
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
sess.run(op)
print ("a:", sess.run(a))
print ("my_variable:", sess.run(b))
# use saver object to save variables
# within the context of the current session
saver.save(sess, "/tmp/my_model.ckpt")a: 3
my_variable: 4加载变量(模型)
与保存模型一样,从文件加载模型也很简单。
注意:如果你指定了Tensorflow名称,则必须在加载程序中使用相同的名称,因为它的优先级高于Python名称。如果你尚未指定Tensorflow名称,则使用Python名称保存变量。
# Only necessary if you use IDLE or a jupyter notebook
tf.reset_default_graph()
# make a dummy variable
# the value is arbitrary, here just zero
# but the shape must the the same as in the saved model
a = tf.Variable(0)
c = tf.Variable(0, name="my_variable")
saver = tf.train.Saver()
with tf.Session() as sess:
# use saver object to load variables from the saved model
saver.restore(sess, "/tmp/my_model.ckpt")
print ("a:", sess.run(a))
print ("my_variable:", sess.run(c))INFO:tensorflow:Restoring parameters from /tmp/my_model.ckpt
a: 3
my_variable: 4可视化图形
在将模型视为代码时,很容易失去大局,随着时间的推移,可能难以看出模型的性能演变。这就是可视化的来源。
Tensorflow提供了一些可以从创建图形中进行大量工作的工具。
可视化工具可分为两个部分:tensorboard和summary writer。tensorboard就是你将看到的可视化,而summary writer是将模型和变量转换成tensorboard可以渲染的东西。
没有任何工作,summary writer可以给你一个模型的图形表示,并且只有很少的工作,你可以得到更详细的摘要,如损失的演变,以及模型学习的准确性。
首先考虑Tensorflow支持的最简单的可视化形式:可视化图形。
为了达到这个目的,我们只需创建一个summary writer,给它一个保存摘要的路径,并将其指向我们想要保存的图形。 这可以在一行代码中完成:
fw = tf.summary.FileWriter("/tmp/summary", sess.graph)在一个例子中,这成为:
a = tf.Variable(5, name="a")
b = tf.Variable(10, name="b")
c = tf.multiply(a,b, name="result")
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print (sess.run(c))
fw = tf.summary.FileWriter("/tmp/summary", sess.graph)使用下面的命令运行tensorboard,并打开URL,我们得到一个简单的图形概述。
tensorboard --logdir=/tmp/summary
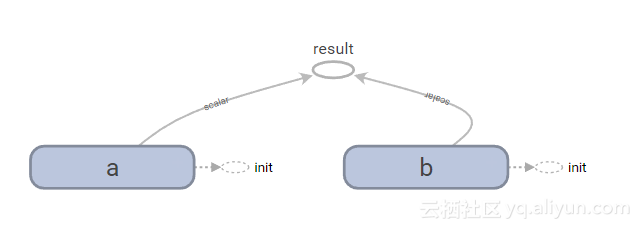
命名和范围
有时在使用大型模型时,图形可视化可能变得复杂。 为了帮助这一点,我们可以使用tf.name_scope定义范围来添加另一个抽象级别,实际上我们可以在范围内定义范围,如下面的示例所示:
with tf.name_scope('primitives') as scope:
a = tf.Variable(5, name='a')
b = tf.Variable(10, name='b')
with tf.name_scope('fancy_pants_procedure') as scope:
# this procedure has no significant interpretation
# and was purely made to illustrate why you might want
# to work at a higher level of abstraction
c = tf.multiply(a,b)
with tf.name_scope('very_mean_reduction') as scope:
d = tf.reduce_mean([a,b,c])
e = tf.add(c,d)
with tf.name_scope('not_so_fancy_procedure') as scope:
# this procedure suffers from imposter syndrome
d = tf.add(a,b)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print (sess.run(c))
print (sess.run(e))
fw = tf.summary.FileWriter("/tmp/summary", sess.graph)注意,作用域名称必须是一个单词。
在tensorboard中打开这个总结可得到:
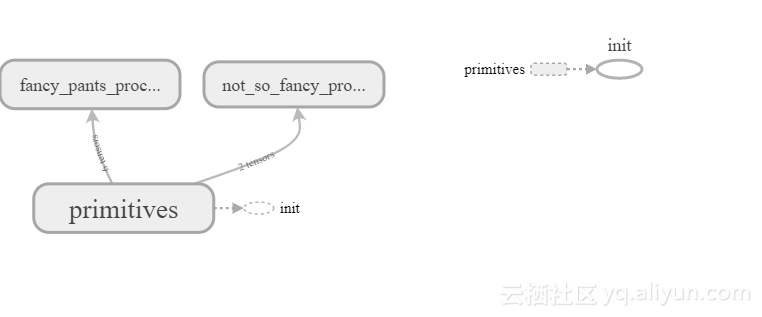
我们可以扩展范围,以查看构成范围的各个操作。
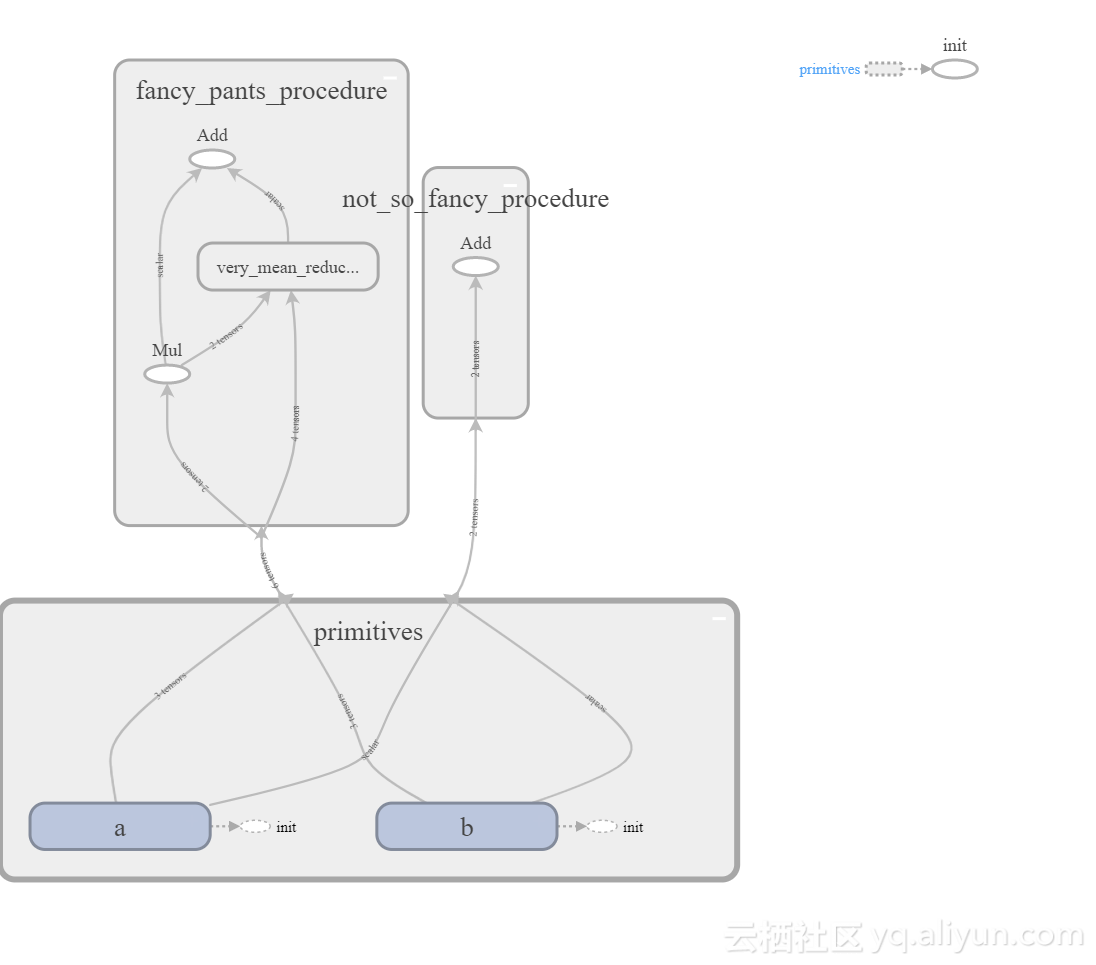
如果我们进一步扩展very_mean_reduction,我们可以看到reduce和mean是reduce_mean函数的一部分。 我们甚至可以扩大它们,看看它们是如何实施的。
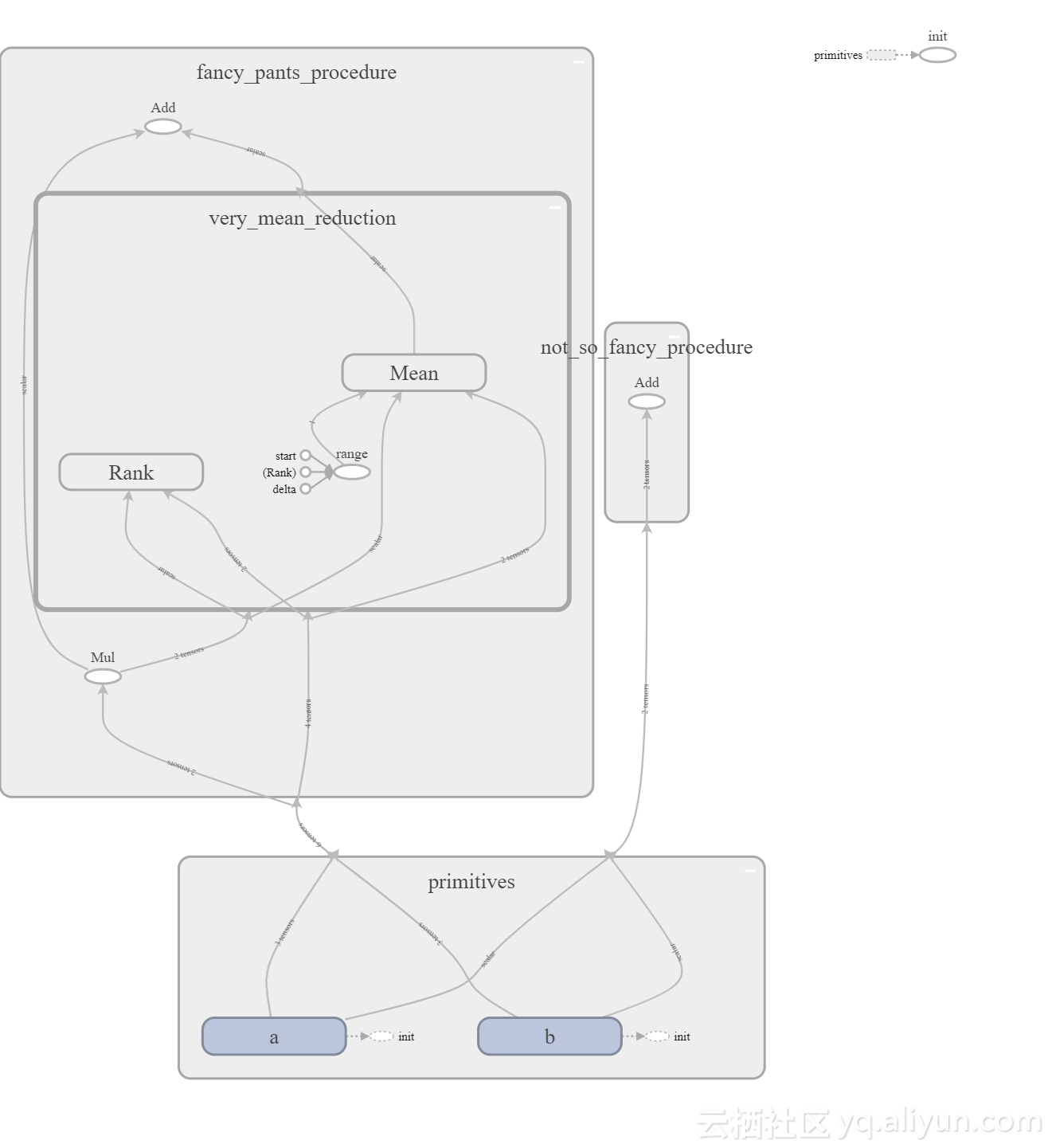
可视化变化的数据
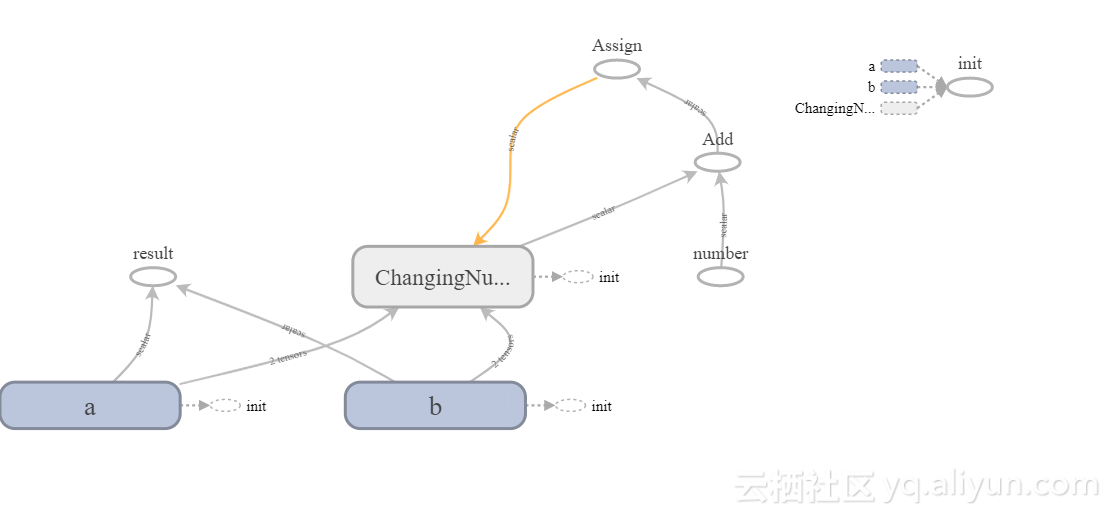
虽然只是可视化图表非常酷,当学习参数时,能够可视化某些变量随时间变化将是有用的。
可变化数据的最简单方法是添加标量摘要。下面是一个实现此操作并记录c变化的示例。
import random
a = tf.Variable(5, name="a")
b = tf.Variable(10, name="b")
# set the intial value of c to be the product of a and b
# in order to write a summary of c, c must be a variable
init_value = tf.multiply(a,b, name="result")
c = tf.Variable(init_value, name="ChangingNumber")
# update the value of c by incrementing it by a placeholder number
number = tf.placeholder(tf.int32, shape=[], name="number")
c_update = tf.assign(c, tf.add(c,number))
# create a summary to track to progress of c
tf.summary.scalar("ChangingNumber", c)
# in case we want to track multiple summaries
# merge all summaries into a single operation
summary_op = tf.summary.merge_all()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# initialize our summary file writer
fw = tf.summary.FileWriter("/tmp/summary", sess.graph)
# do 'training' operation
for step in range(1000):
# set placeholder number somewhere between 0 and 100
num = int(random.random()*100)
sess.run(c_update, feed_dict={number:num})
# compute summary
summary = sess.run(summary_op)
# add merged summaries to filewriter,
# so they are saved to disk
fw.add_summary(summary, step)那么发生了什么?
如果我们从实际逻辑开始,我们看到c的值,变化的变量,由a和b(50)的乘积开始。
然后,我们运行1000次更新操作,将c值增加0到100之间随机选择的量。
这样,如果我们计算C的值随着时间的推移,我们会看到它随时间线性增加。
因此,让我们看看我们如何创建c的摘要。
在会议之前,我们首先告诉Tensorflow,我们实际上想要一个c的总结。
tf.summary.scalar("ChangingNumber", c)在这种情况下,我们使用标量摘要,因为,c是一个标量。 但是,Tensorflow支持一系列不同的摘要,包括:
直方图(接受张量数组)
文本
音频
图片
如果你需要总结可能用于提供网络的丰富数据,则最后三项将非常有用。
接下来,我们将所有摘要添加到summary op以简化计算。
summary_op = tf.summary.merge_all()严格来说,这不是必需的,因为我们只记录一个值的总结,但是在一个更现实的例子中,通常会有多个摘要,这使得这非常有用。你也可以使用tf.summary.merge来合并特定的摘要,如下所示:
summary = tf.summary.merge([summ1, summ2, summ3])如果加上范围,这将是非常强大的。
接下来,我们开始执行实际摘要写入的会话。 我们必须告诉Tensorflow什么和什么时候写; 每当一个变量变化,即使它是有用的,它也不会自动写一个摘要条目。
因此,每当我们想要一个新的条目的摘要,我们必须运行摘要操作。 这允许你灵活地多长时间,或以什么精度记录您的进度。 例如,你可以选择仅记录每千次迭代的进度,以加快计算速度,并免费IO呼叫。
这里我们只需要在每次迭代中记录下面的代码行:
summary = sess.run(summary_op)现在我们总结tensorboard用途,但是我们还没有将它写入磁盘。 为此,我们需要将摘要添加到FileWriter:
fw.add_summary(summary, step)这里,第二个参数步骤表示摘要的位置索引,或者它的图形中的x值。 这可以是你想要的任何数字,而训练网络时,你通常只能使用迭代号。 通过手动指定索引号,当创建图形时,摘要写入程序可以灵活地进行向后移动,跳过值,甚至为相同索引计算两个或多个值。
这就是我们所需要的。如果我们现在打开tensorboard,我们将看到生成的图形,以及摘要中的图形。
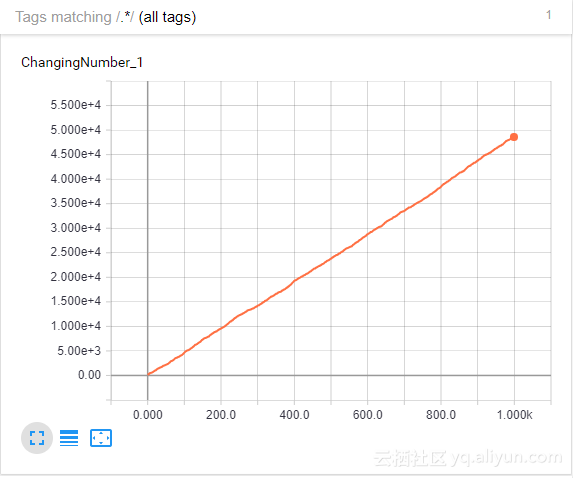
正如所预测的,总结图的趋势确实与正斜率呈线性关系。
几乎实际的例子
虽然迄今为止的小例子都很好地演示了个人的想法,但它们却很难展示它们是如何组合在一起的。
为了说明这一点,我们现在将使用我们对Tensorflow了解的一切(几乎所有的东西),使我们至少可以假装有些实用; 我们将构建一个非常简单的神经网络来对经典MNIST数据(http://yann.lecun.com/exdb/mnist/)集中的数字进行分类。 如果你没有完全掌握神经网络的速度,你可以在回到此之前阅读本简介(即将推出)。
神经网络的构建和训练可以分为几个阶段:
- 导入数据。
- 构建模型架构。
- 定义一个损失函数进行优化,并有一种优化方法。
- 实际培训模式。
- 评估模型。
但是,在我们开始创建模型之前,我们必须先准备Tensorflow:
import tensorflow as tf tf.reset_default_graph() # again, this is not needed if run as a script接下来,我们导入数据。
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
Extracting MNIST_data/train-images-idx3-ubyte.gz Extracting MNIST_data/train-labels-idx1-ubyte.gz Extracting MNIST_data/t10k-images-idx3-ubyte.gz Extracting MNIST_data/t10k-labels-idx1-ubyte.gz由于mnist是一个众所周知的数据集,我们可以使用内置的数据提取器来获取数据周围的精美包装。
现在,现在是定义要使用的实际模型的时候了。 对于这个任务,我们将使用具有两个隐藏层的前馈网络,分别具有500和100个参数。
使用范围的概念将图分割成块,我们可以像这样实现模型:
# input with tf.name_scope('input') as scope: x = tf.placeholder(tf.float32, [None, 28*28], name="input") # a placeholder to hold the correct answer during training labels = tf.placeholder(tf.float32, [None, 10], name="label") # the probability of a neuron being kept during dropout keep_prob = tf.placeholder(tf.float32, name="keep_prob") with tf.name_scope('model') as scope: with tf.name_scope('fc1') as scope: # fc1 stands for 1st fully connected layer # 1st layer goes from 784 neurons (input) to 500 in the first hidden layer w1 = tf.Variable(tf.truncated_normal([28*28, 500], stddev=0.1), name="weights") b1 = tf.Variable(tf.constant(0.1, shape=[500]), name="biases") with tf.name_scope('softmax_activation') as scope: # softmax activation a1 = tf.nn.softmax(tf.matmul(x, w1) + b1) with tf.name_scope('dropout') as scope: # dropout drop1 = tf.nn.dropout(a1, keep_prob) with tf.name_scope('fc2') as scope: # takes the first hidden layer of 500 neurons to 100 (second hidden layer) w2 = tf.Variable(tf.truncated_normal([500, 100], stddev=0.1), name="weights") b2 = tf.Variable(tf.constant(0.1, shape=[100]), name="biases") with tf.name_scope('relu_activation') as scope: # relu activation, and dropout for second hidden layer a2 = tf.nn.relu(tf.matmul(drop1, w2) + b2) with tf.name_scope('dropout') as scope: drop2 = tf.nn.dropout(a2, keep_prob) with tf.name_scope('fc3') as scope: # takes the second hidden layer of 100 neurons to 10 (which is the output) w3 = tf.Variable(tf.truncated_normal([100, 10], stddev=0.1), name="weights") b3 = tf.Variable(tf.constant(0.1, shape=[10]), name="biases") with tf.name_scope('logits') as scope: # final layer doesn't have dropout logits = tf.matmul(drop2, w3) + b3对于训练,我们,我们将使用交叉熵损失函数和ADAM 优化器,学习率为0.001。 按照上面的例子,我们继续使用范围来组织图。
我们还为准确性和平均损失添加了两个摘要,并创建了一个合并的摘要操作,以简化后续步骤。
最后,一旦我们添加了保护对象,所以我们不会在训练后失去模型,我们有这个:
with tf.name_scope('train') as scope: with tf.name_scope('loss') as scope: # loss function cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits) # use adam optimizer for training with a learning rate of 0.001 train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy) with tf.name_scope('evaluation') as scope: # evaluation correct_prediction = tf.equal(tf.argmax(logits,1), tf.argmax(labels,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # create a summarizer that summarizes loss and accuracy tf.summary.scalar("Accuracy", accuracy) # add average loss summary over entire batch tf.summary.scalar("Loss", tf.reduce_mean(cross_entropy)) # merge summaries summary_op = tf.summary.merge_all() # create saver object saver = tf.train.Saver()现在是开始训练网络的时候了。 使用前面讨论的技术,我们每100个步骤写出一个总结,一共20000个步骤。
在每一步,我们通过运行train_step操作,通过一系列100个示例来训练网络,该操作将根据学习速率更新网络的权重。
最后,一旦学习完成,我们打印出测试精度,并保存模型。
with tf.Session() as sess: # initialize variables tf.global_variables_initializer().run() # initialize summarizer filewriter fw = tf.summary.FileWriter("/tmp/nn/summary", sess.graph) # train the network for step in range(20000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, labels: batch_ys, keep_prob:0.2}) if step%1000 == 0: acc = sess.run(accuracy, feed_dict={ x: batch_xs, labels: batch_ys, keep_prob:1}) print("mid train accuracy:", acc, "at step:", step) if step%100 == 0: # compute summary using test data every 100 steps summary = sess.run(summary_op, feed_dict={ x: mnist.test.images, labels: mnist.test.labels, keep_prob:1}) # add merged summaries to filewriter, # so they are saved to disk fw.add_summary(summary, step) print ("Final Test Accuracy:", sess.run(accuracy, feed_dict={ x: mnist.test.images, labels: mnist.test.labels, keep_prob:1})) # save trained model saver.save(sess, "/tmp/nn/my_nn.ckpt")
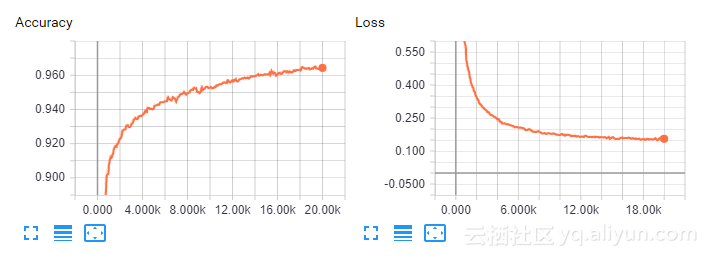
mid train accuracy: 0.1 at step: 0 mid train accuracy: 0.91 at step: 1000 mid train accuracy: 0.89 at step: 2000 mid train accuracy: 0.91 at step: 3000 [...] mid train accuracy: 0.97 at step: 17000 mid train accuracy: 0.98 at step: 18000 mid train accuracy: 0.97 at step: 19000 Final Test Accuracy: 0.961396%的准确度是好吗?
不,这确实有点糟糕,但是这个网络的重点不是最好的网络。 相反,它的重点是演示如何使用Tensorflow来构建一个网络,并为很少的工作获得大量的可视化效果。
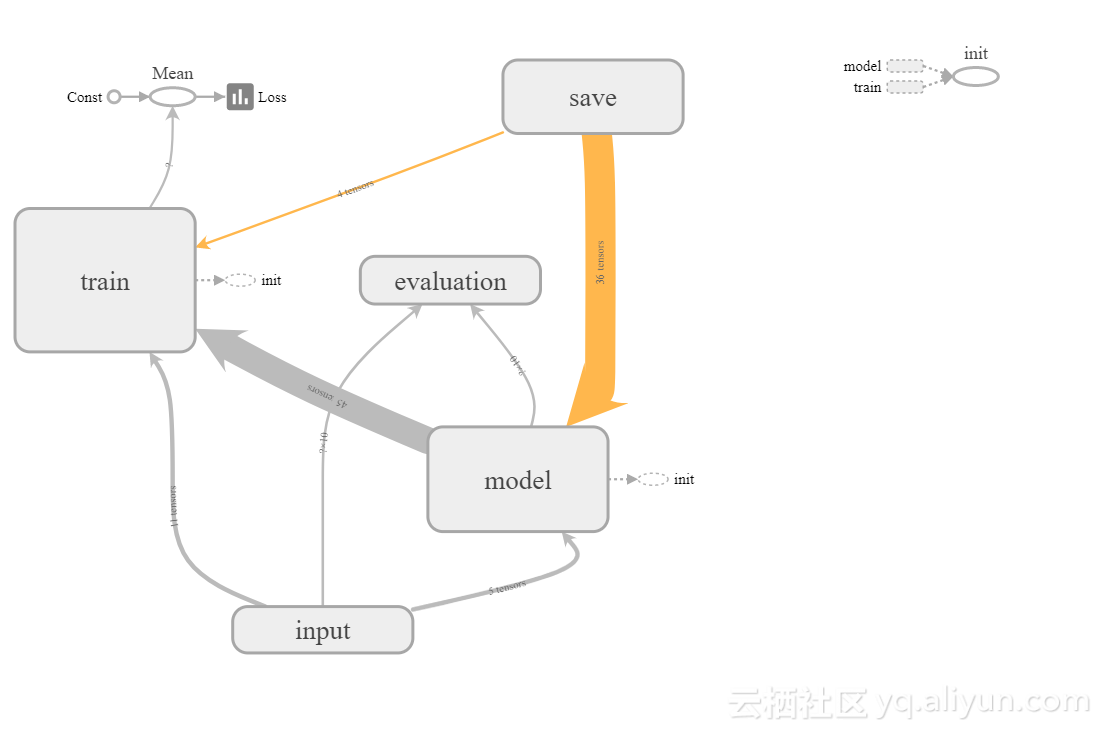
如果我们运行的模型,并在tensorboard打开它,我们得到:
此外,我们可以看到Tensorflow对精度和损失做出的总结,并且按预期,它们的行为大致相似。 我们还看到,开始时的准确性增加了很多,但是随着时间的推移,它的平均化程度有所增加,这部分是因为我们使用ADAM优化器,部分原因在于梯度的性质。
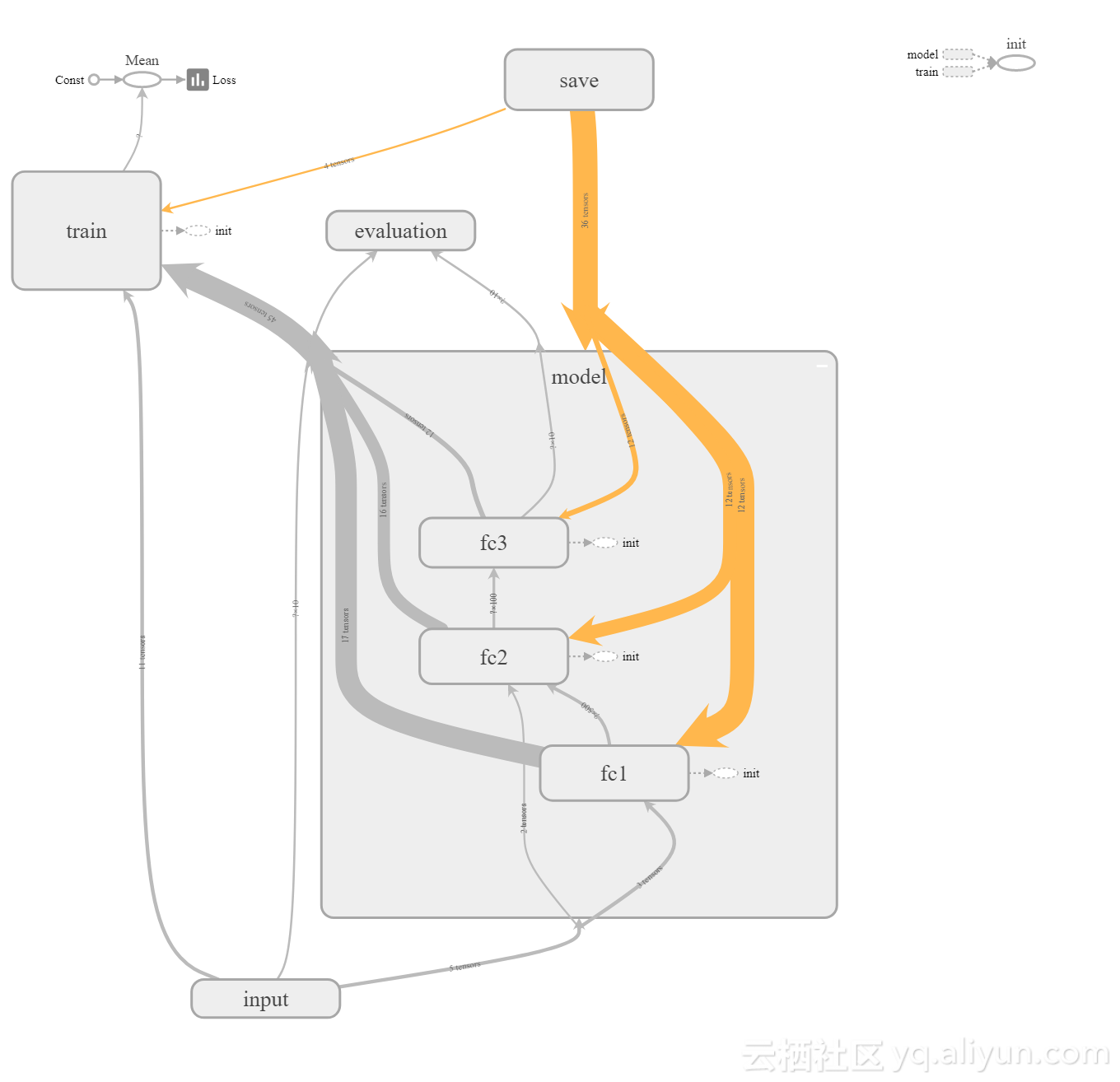
使用嵌套的范围让我们逐渐改变抽象级别。 注意,如果我们扩展模型,我们可以在单个图层组件之前看到各个图层。
如果你想自己运行这个网络,你可以访问Github上的代码。
总结
如果你已经看到了这里,现在你应该对Tensorflow的基础有了一个基本的了解:它的功能如何,如何进行基本的计算,如何可视化图形,最后,你已经看到了一个真正的例子来使用它创建一个基本的神经网络。
另外,如果你能做到这一点,可以给我发私信@kasperfredn。
由于这只是Tensorflow的一个介绍,我们没有介绍很多,但现在应该足够了解API文档,你可以在其中找到可以纳入代码的模块。
如果你想要一个挑战来测试您的理解,请尝试使用Tensorflow来实现另一种机器学习模型,方法是从我们在此创建的模型中工作,或从头开始。
要获得反馈,请将结果发送到“homework [at] kasperfred.com”。 请记住在主题行中包含论文的标题。
本文由北邮@爱可可-爱生活老师推荐,阿里云云栖社区组织翻译。
文章原标题《Introduction to Tensorflow as a Computational Framework》,作者:Kasper Fredenslund ,译者:董昭男,审校:
文章为简译,更为详细的内容,请查看原文