昨天同事参加了一个研讨会,有提到一个案例。一个通过dblink查询远端数据库,原来查询很快,但是远端数据库增加了一个索引之后,查询一下子变慢了。
经过分析,发现那个通过dblink的查询语句,查询远端数据库的时候,是走索引的,但是远端数据库添加索引之后,如果索引的个数超过20个,就会忽略第一个建立的索引,如果查询语句恰好用到了第一个建立的索引,被忽略之后,只能走Full Table Scan了。
听了这个案例,我查了一下,在oracle官方文档中,关于Managing a Distributed Database有一段话:
Several performance restrictions relate to access of remote objects:
Remote views do not have statistical data.Queries on partitioned tables may not be optimized.No more than 20 indexes are considered for a remote table.No more than 20 columns are used for a composite index.
说到,如果远程数据库使用超过20个索引,这些索引将不被考虑。这段话,在oracle 9i起的文档中就已经存在,一直到12.2还有。
那么,超过20个索引,是新的索引被忽略了?还是老索引被忽略了?如何让被忽略的索引让oracle意识到?我们来测试一下。
初始化测试表
可以看到,远程表有27个字段,目前还只是在前20个字段建立了索引,且第一个字段是主键。本地表,有6个字段,6个字段都建索引。
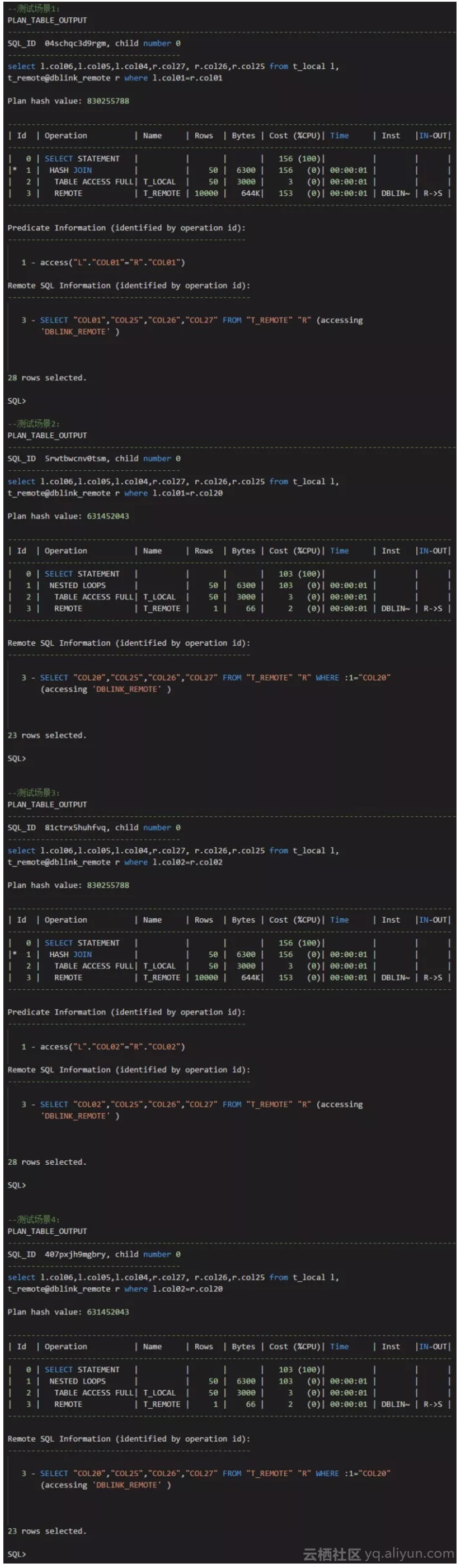
第一轮测试,远程表上有20个索引测试场景1:
在远程表20索引的情况下,本地表和远程表关联,用本地表的第一个字段关联远程表的第一个字段:
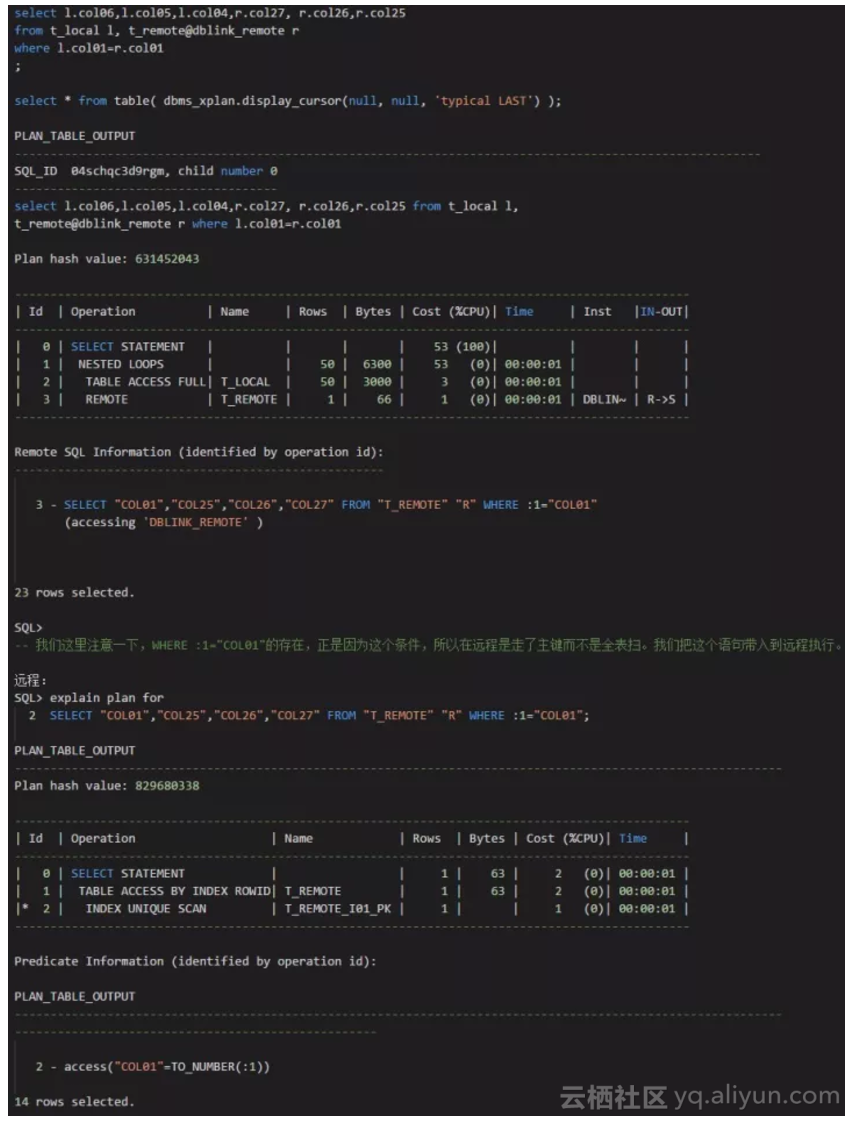
我们可以看到,对于远程表的执行计划,这是走主键的。
测试场景2:
在远程表20索引的情况下,本地表和远程表关联,用本地表的第一个字段关联远程表的第20个字段:
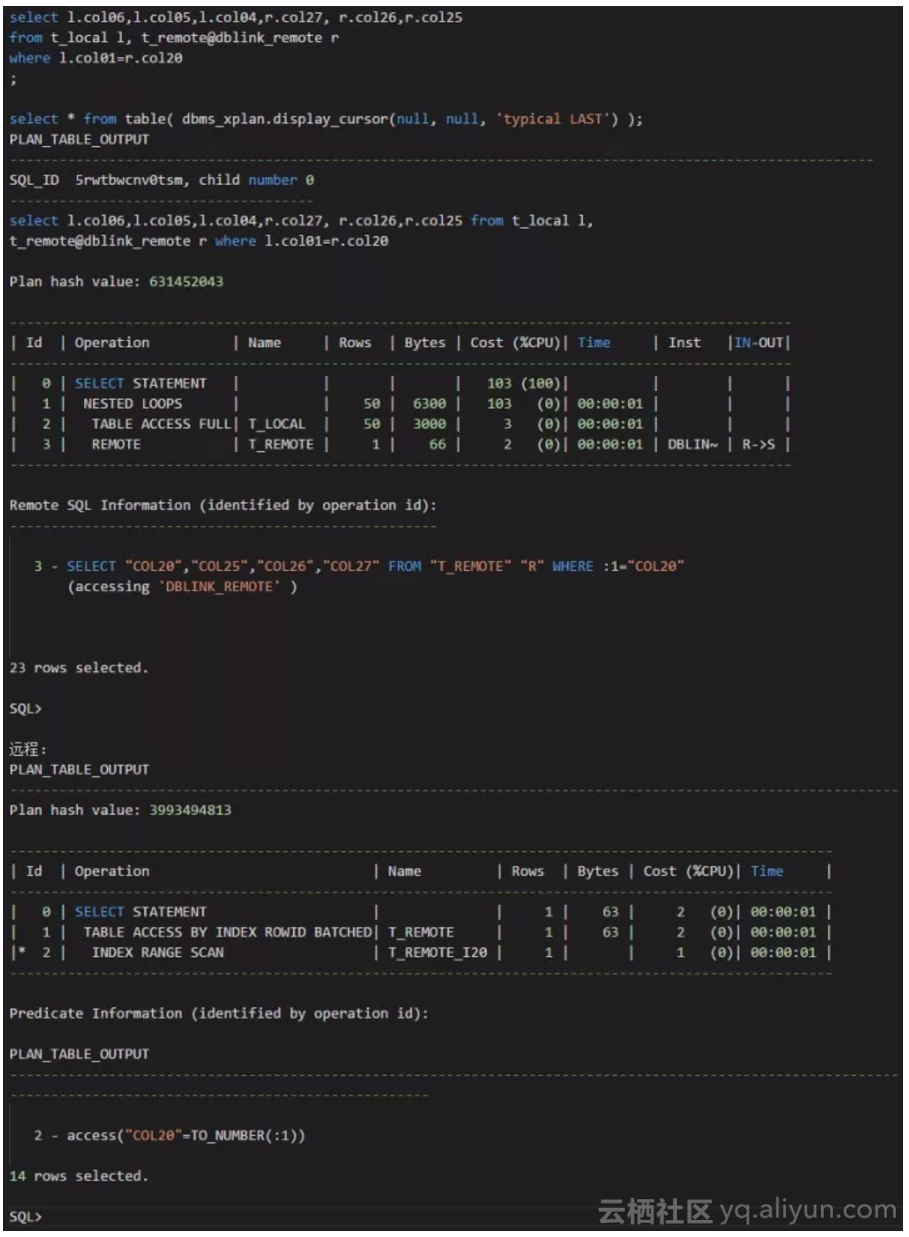
我们可以看到,对于远程表的执行计划,这是走索引范围扫描的。
测试场景3:
在远程表20索引的情况下,本地表和远程表关联,用本地表的第2个字段关联远程表的第2个字段:
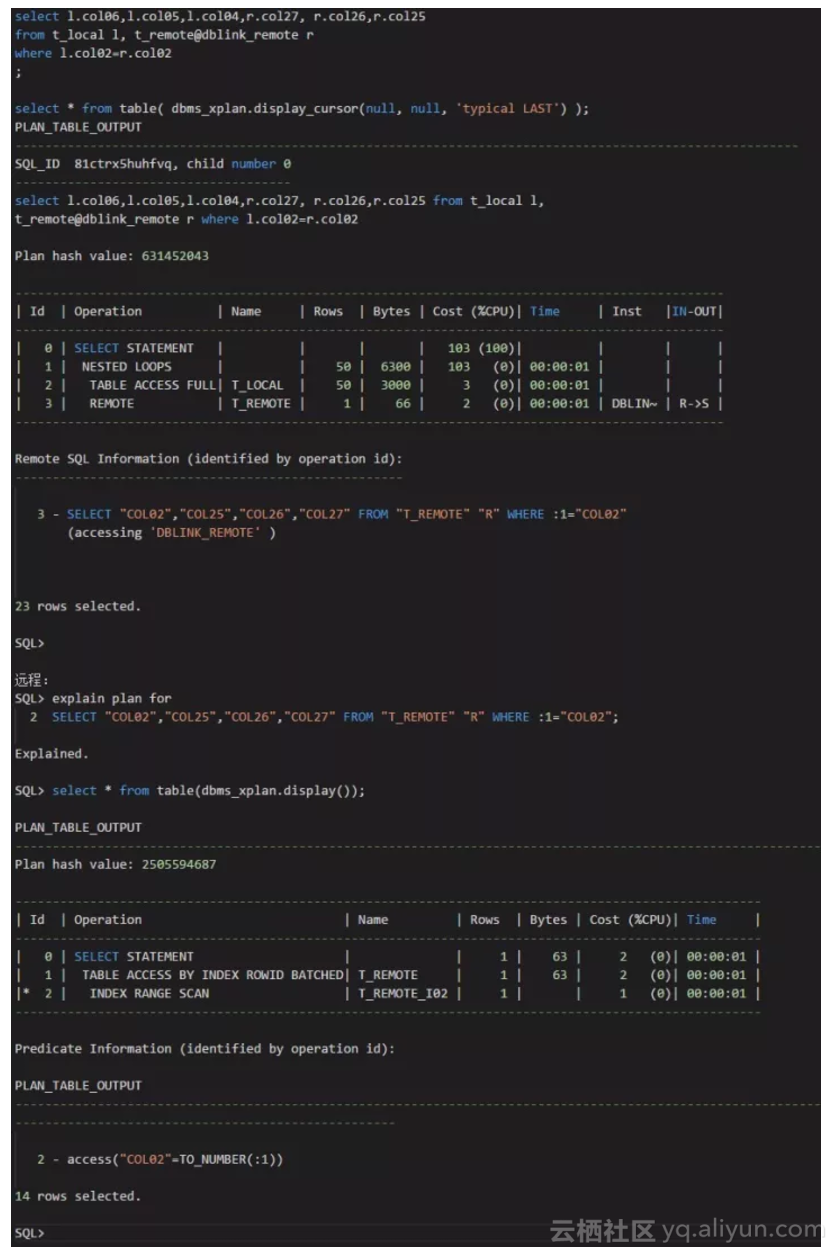
我们可以看到,对于远程表的执行计划,这是走索引范围扫描的。
测试场景4:
在远程表20索引的情况下,本地表和远程表关联,用本地表的第2个字段关联远程表的第20个字段:
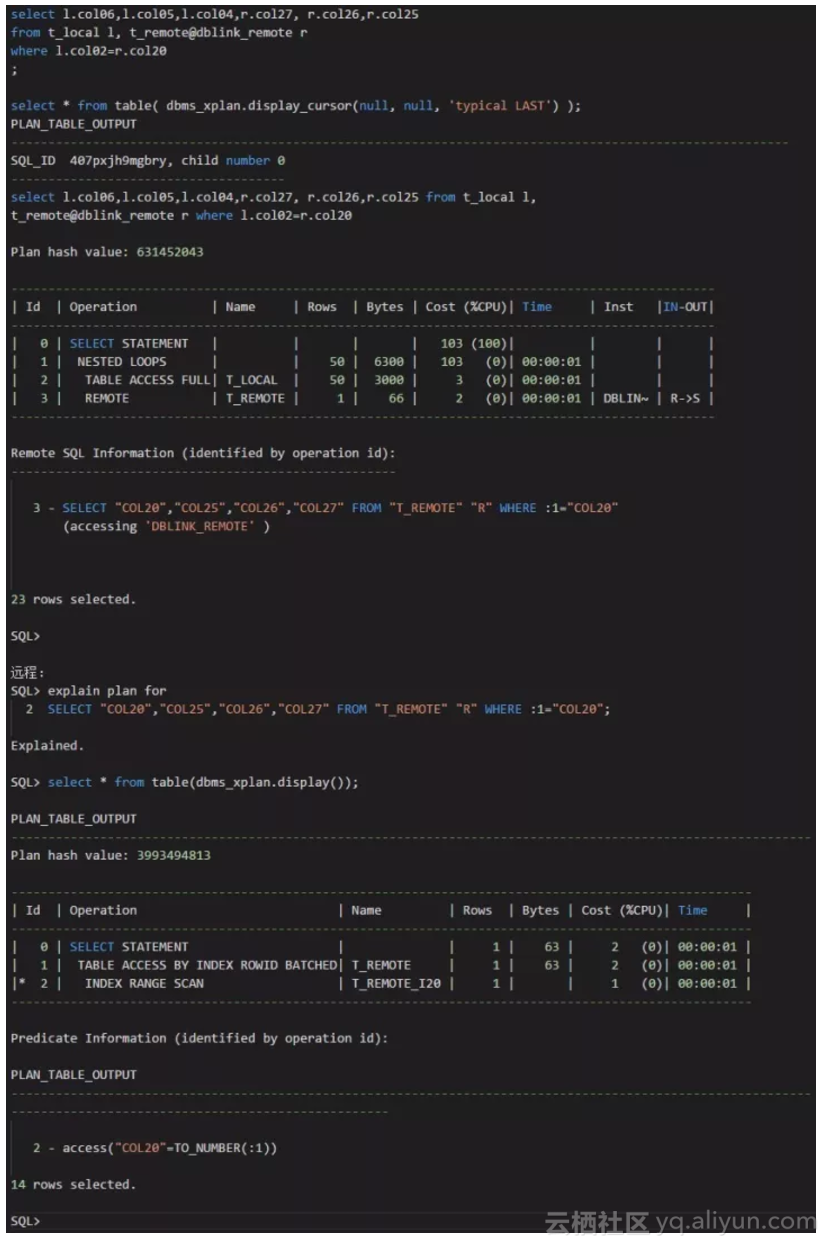
我们可以看到,对于远程表的执行计划,这是走索引范围扫描的。
建立第21个索引
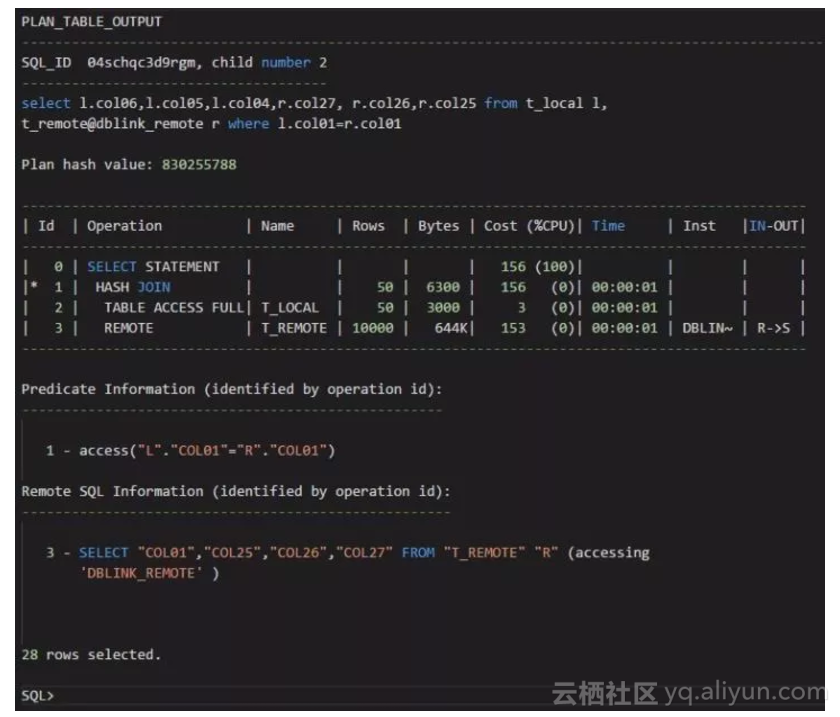
测试场景1:
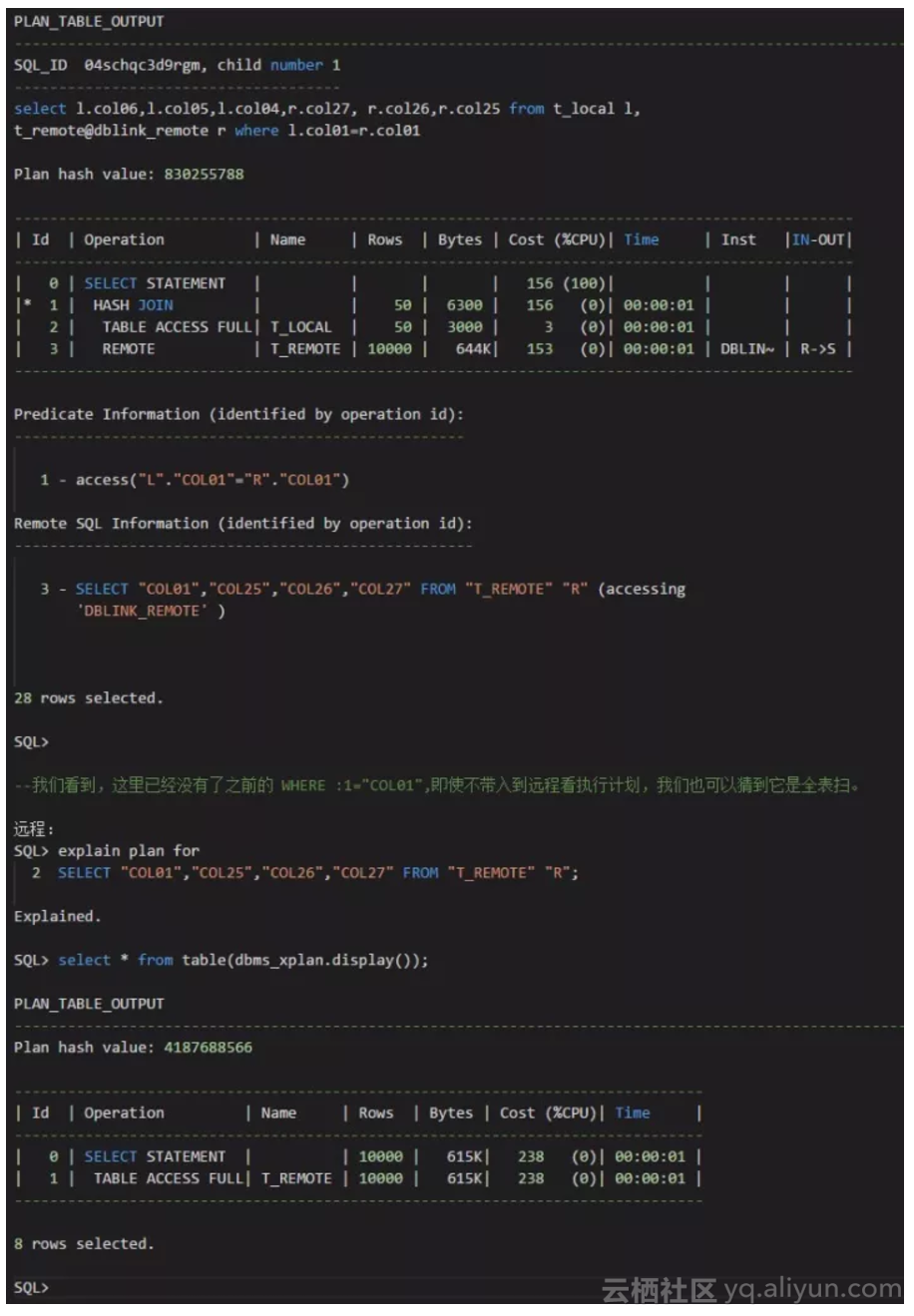
我们可以看到,对于远程表的执行计划,如果关联条件是远程表的第一个字段,第一个字段上的索引是被忽略的,执行计划是选择全表扫描的。
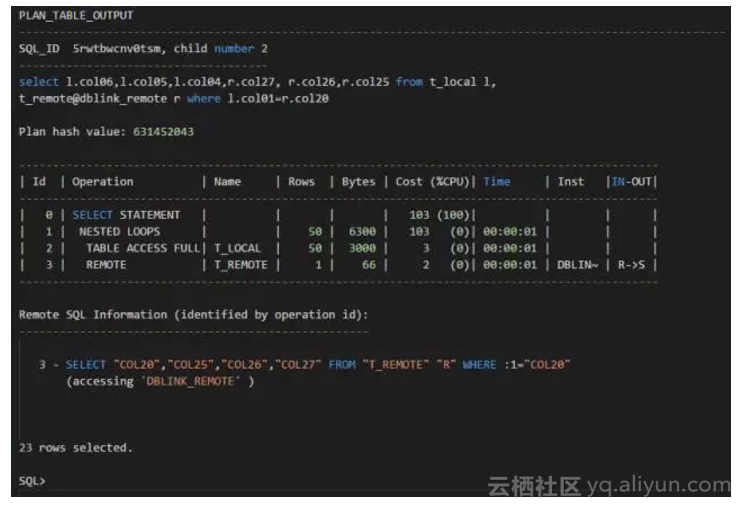
测试场景2:
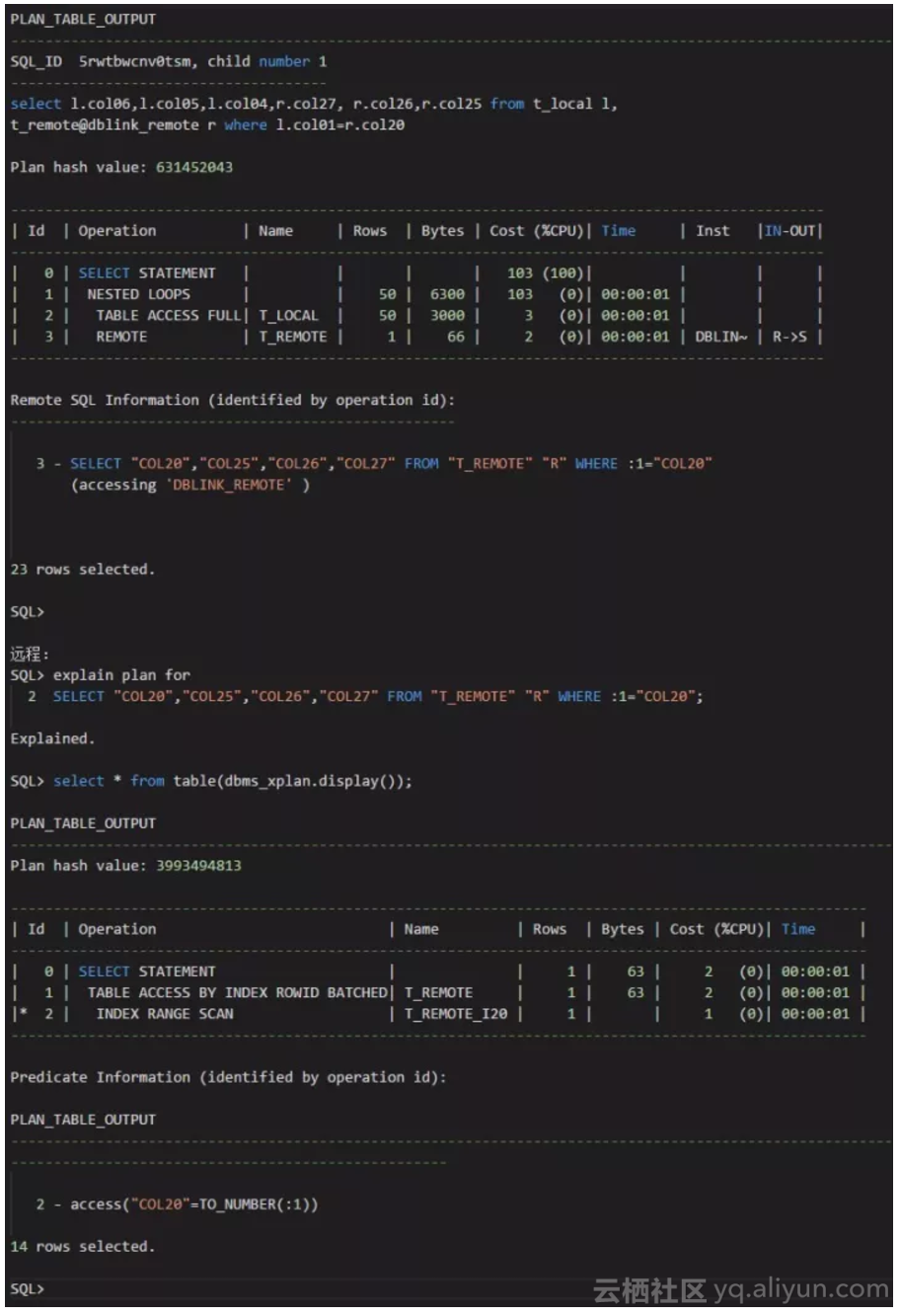
我们可以看到,对于远程表的执行计划,如果关联条件是远程表的第20个字段,这第20个字段上的索引是没有被忽略的,执行计划是走索引。
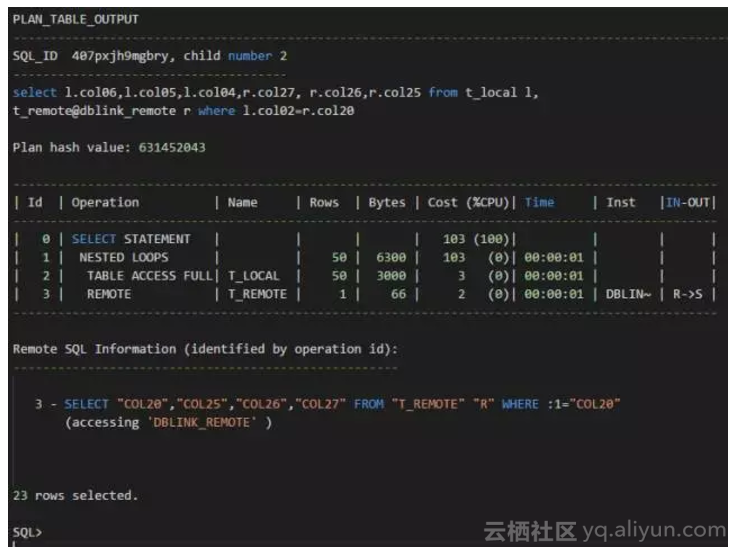
测试场景3:
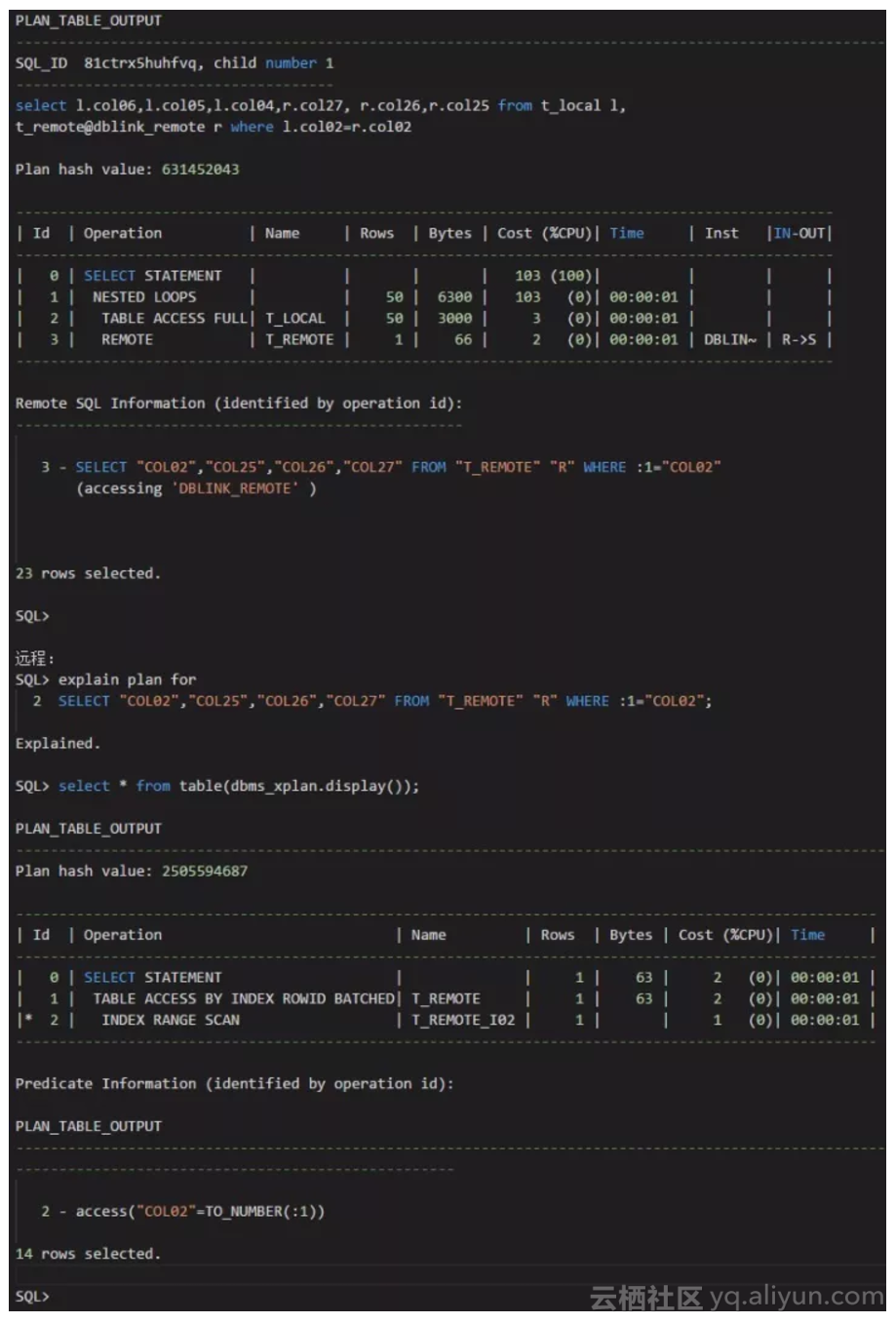
我们可以看到,对于远程表的执行计划,如果关联条件是远程表的第2个字段,这第2个字段上的索引是没有被忽略的,执行计划是走索引。
测试场景4:
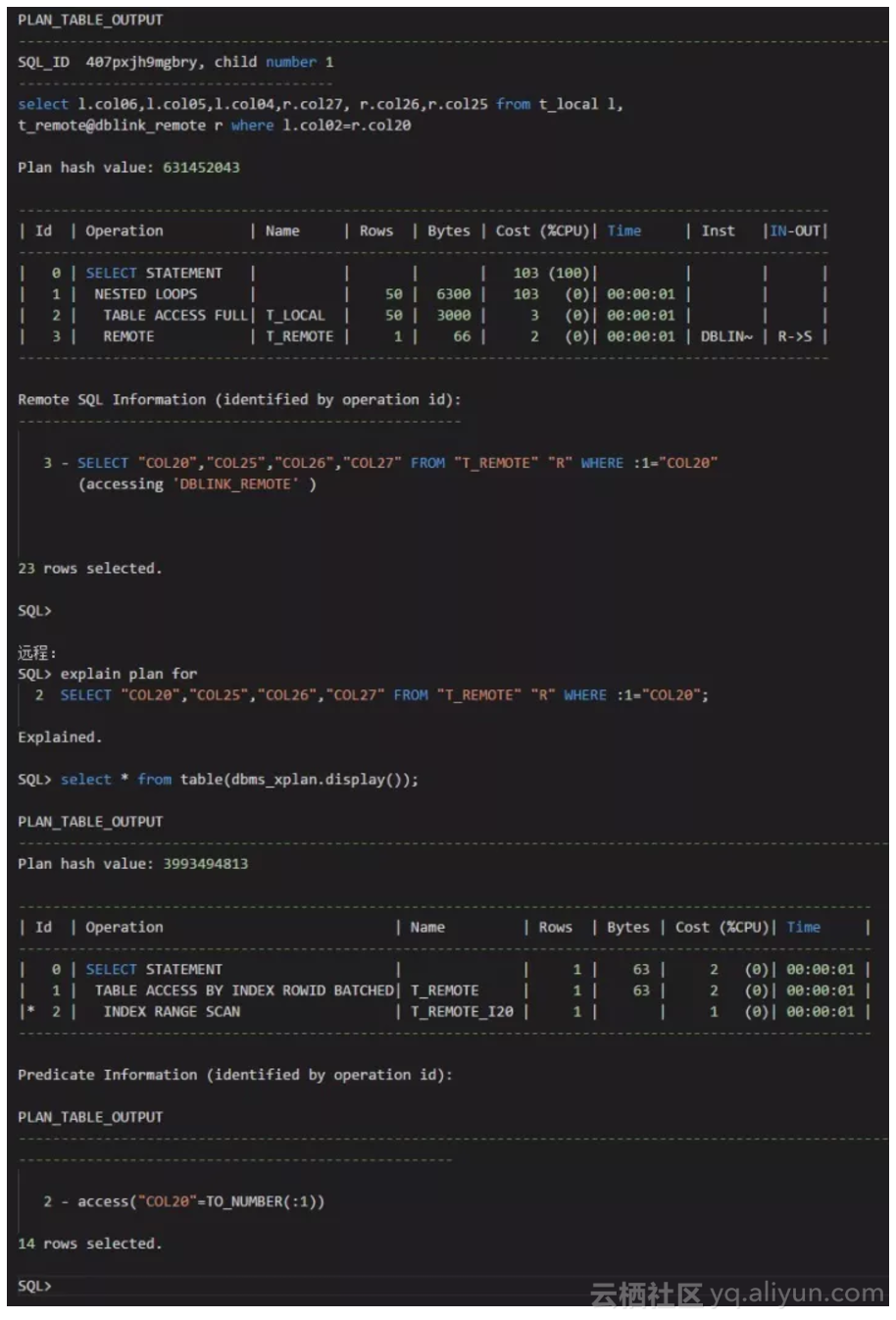
我们可以看到,对于远程表的执行计划,如果关联条件是远程表的第20个字段,这第20个字段上的索引是没有被忽略的,执行计划是走索引。
我们目前可以总结到,当远程表第21个索引建立的时候,通过dblink关联本地表和远程表,如果关联条件是远程表的第1个建立的索引的字段,那么这个索引将被忽略,从而走全表扫描。如果关联条件是远程表的第2个建立索引的字段,则不受影响。
似乎是有效索引的窗口是20个,当新建第21个,那么第1个就被无视了。
![]()
再次重复上面4个测试
测试场景1:
测试场景2:
测试场景3:
上述的测试,其实是可以验证我们的猜测的。oracle对于通过dblink关联访问远程表,只是会意识到最近创建的20个索引的字段。这个意识到索引的窗口是20个,一旦建立了一个新索引,那么最旧的一个索引会被无视。
尝试rebuild索引
rebuild第2个索引

所以我们看到,索引rebuild,是不能起到重新“唤醒”索引的作用。
尝试 drop and recreate 第2个索引
我们可以看到,通过drop之后再重建,是可以“唤醒”第二个索引的。这也证明了我们20个索引识别的移动窗口,是按照索引的创建时间来移动的。
综上:
- 对于通过dblink关联本地表和远程表,如果远程表的索引个数少于20个,那么不受影响。
- 对于通过dblink关联本地表和远程表,如果远程表的索引个数增加到21个或以上,那么oracle在执行远程操作的时候,将忽略最早创建的那个索引,但是会以20个为窗口移动,最新建立的索引会被意识到。此时如果查询的关联条件中,使用到最早创建的那个索引的字段,由于忽略了索引,会走全表扫描。
- 要“唤醒”对原来索引的意识,rebuild索引无效,需要drop & create索引。
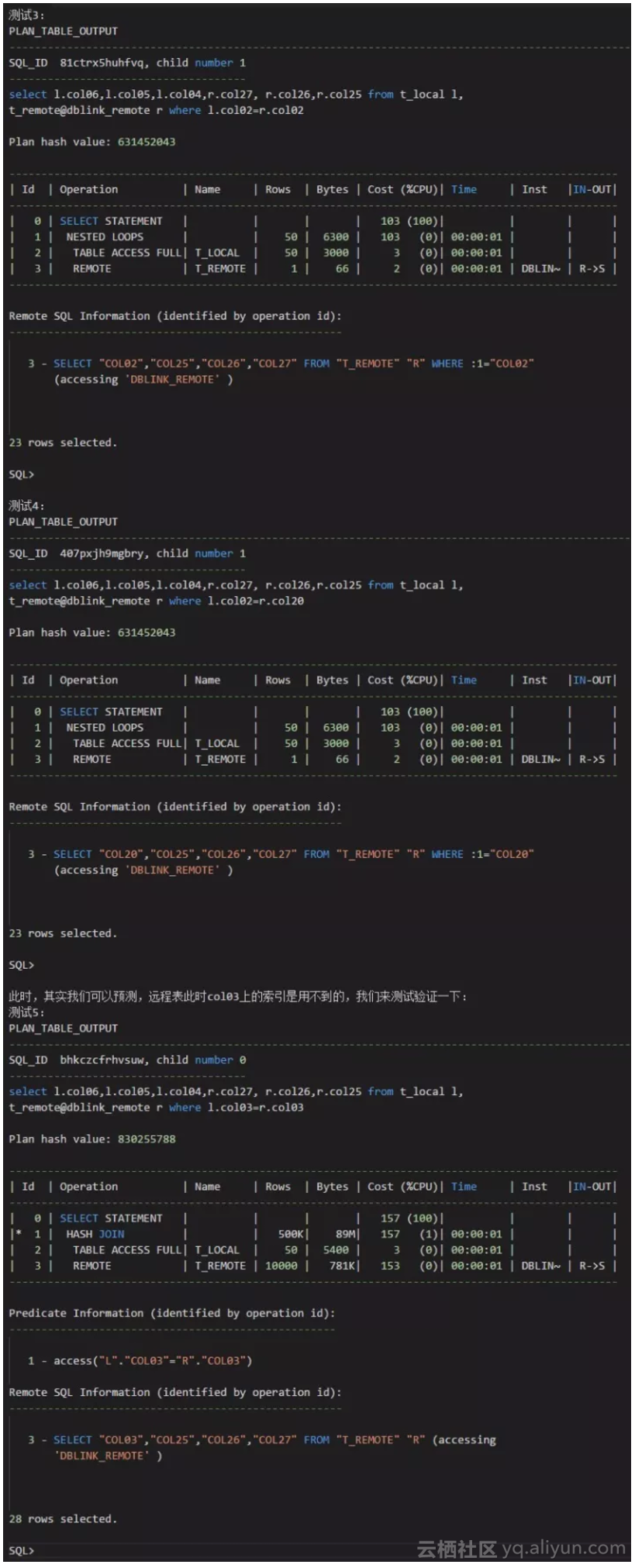
- 在本地表数据量比较少,远程表的数据量很大,而索引数量超过20个,且关联条件的字段时最早索引的情况下,可以考虑使用DRIVING_SITE的hint,将本地表的数据全量到远程中,此时远程的关联查询可以意识到那个索引。可见文末的例子。是否使用hint,需要评估本地表数据全量推送到远程的成本,和远程表使用全表扫的成本。
附:在22个索引的情况下,尝试采用DRIVING_SITE的hint:
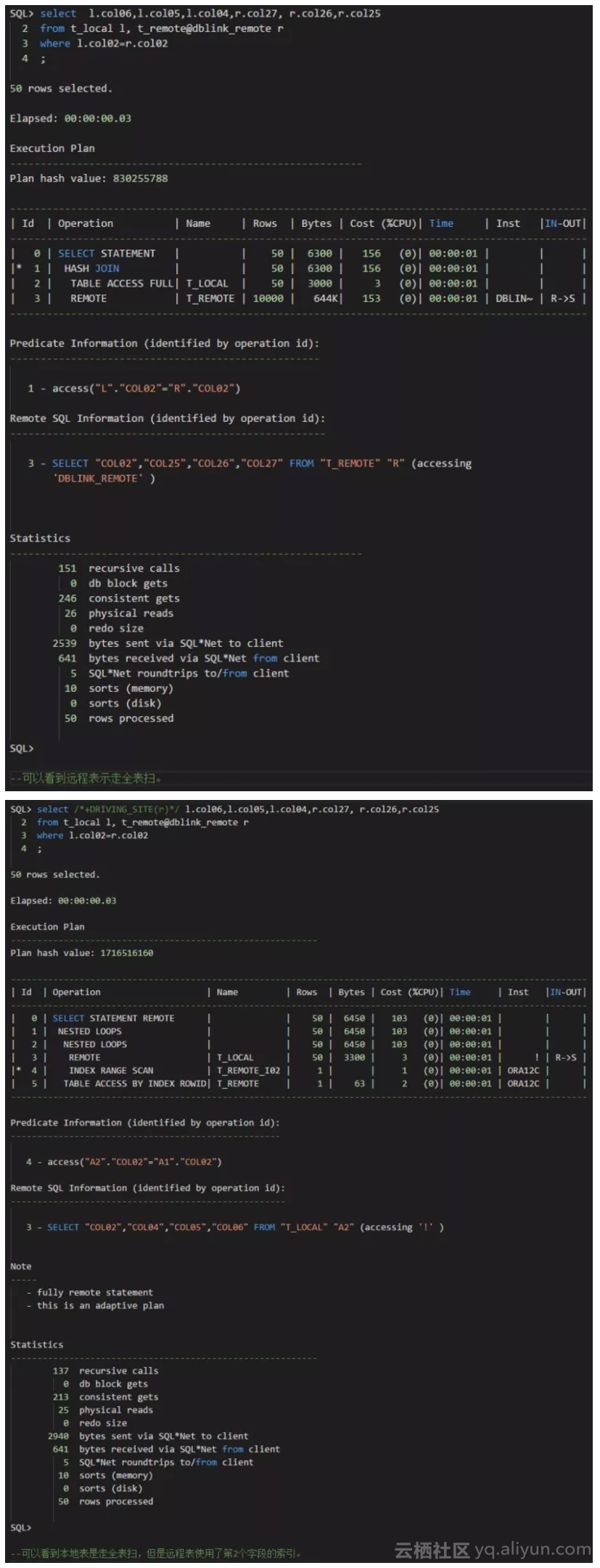
原文发布时间为:2017-10-26
本文作者:何剑敏
