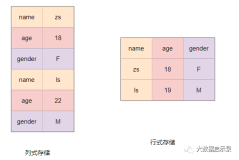
Avro合并本地文件
package com.zhiyou100.mr;
import java.io.File;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.util.ArrayList;
import java.util.List;
import org.apache.avro.Schema;
import org.apache.avro.file.DataFileReader;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.io.DatumReader;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.specific.SpecificDatumReader;
import org.apache.avro.specific.SpecificDatumWriter;
import org.apache.commons.codec.digest.DigestUtils;
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.fs.FileUtil;
import com.zhiyou100.schema.SmallFile;
public class AvroMergeSmallFile {
private Schema.Parser parse = new Schema.Parser();
private Schema schema;
private List<String> inputFilePaths = new ArrayList<String>();
private AvroMergeSmallFile() {
schema = SmallFile.getClassSchema();
}
public void addInputFileDir(String inputDir) throws IOException {
// 获取出文件夹下的所有文件
File[] files = FileUtil.listFiles(new File(inputDir));
// 把文件路径添加到inputFilePaths中
for (File file : files) {
inputFilePaths.add(file.getPath());
}
}
// 把inputFilePaths中所有文件合并到一个avro文件中
public void mergeFile(String outputPath) throws IOException {
DatumWriter<SmallFile> writer = new SpecificDatumWriter<SmallFile>();
DataFileWriter<SmallFile> fileWriter = new DataFileWriter<SmallFile>(writer);
fileWriter.create(SmallFile.getClassSchema(), new File(outputPath));
// 把inputFilePath的文件一个个读取出来根据模式放入到avro文件中
for (String filePath : inputFilePaths) {
File inputFile = new File(filePath);
byte[] content = FileUtils.readFileToByteArray(inputFile);
SmallFile oneSmallFile = SmallFile.newBuilder().setFileName(inputFile.getAbsolutePath())
.setContent(ByteBuffer.wrap(content)).build();
fileWriter.append(oneSmallFile);
System.out.println("写入" + inputFile.getAbsolutePath() + "成功"+DigestUtils.md5Hex(content));
}
fileWriter.flush();
fileWriter.close();
}
//读取大avro中的文件
public void readMergedFile (String avrofile) throws IOException{
DatumReader<SmallFile> reader =new SpecificDatumReader<SmallFile>();
DataFileReader<SmallFile>fileReader =new DataFileReader<SmallFile>(new File(avrofile), reader);
SmallFile smallFile =null;
while(fileReader.hasNext()){
smallFile=fileReader.next();
System.out.println("文件名:"+smallFile.getFileName());
System.out.println("文件内容:"+new String(smallFile.getContent().array().toString()));
System.out.println("文件MD5"+DigestUtils.md5Hex(smallFile.getContent().array()));
}
}
public static void main(String[] args) throws IOException {
AvroMergeSmallFile avroMergeSmallFile =new AvroMergeSmallFile();
avroMergeSmallFile.addInputFileDir("C:\\Users\\Administrator\\Desktop\\reversetext");
avroMergeSmallFile.mergeFile("C:\\Users\\Administrator\\Desktop\\AvroMErgeSmallFile");
avroMergeSmallFile.readMergedFile("C:\\Users\\Administrator\\Desktop\\AvroMErgeSmallFile");
}