前言
在前面几节我们介绍了undo log、redo log以及InnoDB如何崩溃恢复来实现数据ACID的相关知识。本期我们介绍另外一种重要的数据变更日志,也就是InnoDB change buffer。 Change buffer的主要目的是将对二级索引的数据操作缓存下来,以此减少二级索引的随机IO,并达到操作合并的效果。
在MySQL5.5之前的版本中,由于只支持缓存insert操作,所以最初叫做insert buffer,只是后来的版本中支持了更多的操作类型缓存,才改叫change buffer。这也是为什么代码中有大量的ibuf前缀开头的函数或变量。为了表达方面,本文也将change buffer缩写为ibuf。
由于历史上ibuf的数据格式曾发生过多次变化,本文讨论的相关内容基于如下设定:
版本为5.5及之后的版本,不涉及旧版本的逻辑
innodb_change_buffering设置为ALL,表示缓存所有操作
ibuf btree
change buffer的物理上是一颗普通的btree,存储在ibdata系统表空间中,根页为ibdata的第4个page(FSP_IBUF_TREE_ROOT_PAGE_NO)。
一条ibuf 记录大概包含如下列:

ibuf btree通过三列(space id, page no , counter)作为主键来唯一决定一条记录, 其中counter是一个递增值,目的是为了维持不同操作的有序性,例如可以通过counter来保证在merge时执行如下序列时的循序和用户操作顺序是一致的:INSERT x, DELETE-MARK x, INSERT x。
在插入ibuf记录前我们是不知道counter的值的,因此总是先将对应tuple的counter设置为0xFFFF,然后将cursor以模式PAGE_CUR_LE定位到小于等于(space id, page no, 0xFFFF)的位置,新记录的counter为当前位置记录counter值加1。
ibuf btree最大默认为buffer pool size的25%,当超过25%时,可能触发用户线程同步缩减ibuf btree。为何要将ibuf btree的大小和buffer pool大小相关联呢 ? 一个比较重要的原因是防止ibuf本身占用过多的buffer pool资源。
ibuf bitmap
由于ibuf缓存的操作都是针对某个具体page的,因此在缓存操作时必须保证该操作不会导致空Page 或索引分裂。
针对第一种情况,即避免空page,主要是对Purge线程而言。因为只有Purge线程才会去真正的删除二级索引上的物理记录。在准备插入类型为IBUF_OP_DELETE的操作缓存时,会预估在apply完该page上所有的ibuf entry后还剩下多少记录(ibuf_get_volume_buffered), 如果只剩下一条记录,则拒绝本次purge操作缓存,改走正常的读入物理页逻辑。
针对第二种情况,InnoDB通过一种特殊的Page来维护每个数据页的空闲空间大小,也就是ibuf bitmap page,该page存在于每个ibd文件中,具有固定的page no,其文件结构如下图所示:

ibuf bitmap使用4个bit来描述一个page:
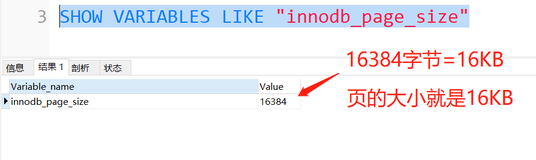
(a) IBUF_BITMAP_FREE:使用2个bit来描述空间空间大小,以16KB的Page size为例,能表示的空闲空间范围为0(0 bytes),1(512 bytes),2(1024 bytes),3(2048 bytes)。很显然,最大能够缓存的二级索引记录最大不可能超过2048字节。
由于只有INSERT操作才可能导致Page记录满,因此只需要对IBUF_OP_INSERT类型的操作进行判断:
ibuf_insert_low:
if (op == IBUF_OP_INSERT) {
ulint bits = ibuf_bitmap_page_get_bits(
bitmap_page, page_no, zip_size, IBUF_BITMAP_FREE,
&bitmap_mtr);
if (buffered + entry_size + page_dir_calc_reserved_space(1)
> ibuf_index_page_calc_free_from_bits(zip_size, bits)) {
/* Release the bitmap page latch early. */
ibuf_mtr_commit(&bitmap_mtr);
/* It may not fit */
do_merge = TRUE;
ibuf_get_merge_page_nos(FALSE,
btr_pcur_get_rec(&pcur), &mtr,
space_ids, space_versions,
page_nos, &n_stored);
goto fail_exit;
}
}其中ibuf_bitmap_page_get_bits函数根据space id 和page no 获取对应的bitmap page,找到空闲空间描述信息;如果本次插入操作可能超出限制,则从当前cursor位置附近开始,触发一次异步的ibuf merge,目的是尽量将当前page的缓存操作做一次合并。
在正常的对物理页的DML过程中,如果Page内空间发生了变化,总是需要去更新对应的IBUF_BITMAP_FREE值。参考函数:btr_compress、btr_cur_optimistic_insert。
(b)IBUF_BITMAP_BUFFERED:用于表示该page是否有操作缓存,在ibuf_insert_low函数中,准备插入ibuf btree前设置成true。二级索引物理页读入内存时会根据该标记位判断是否需要进行ibuf merge操作。
(c) IBUF_BITMAP_IBUF:该数据页是否是ibuf btree的一部分
该标记位主要用于异步AIO读操作。InnoDB专门为change buffer模块分配了一个后台AIO线程,如果page属于change buffer的b树,则使用该线程做异步读,参考函数:ibuf_page_low
操作类型
InnoDB change buffer可以对三种类型的操作进行缓存: INSERT、DELETE-MARK 、DELETE操作,前两种对应用户线程操作,第三种则由Purge操作触发。
用户可以通过参数innodb_change_buffering来控制缓存何种操作:
/** Allowed values of innodb_change_buffering */
static const char* innobase_change_buffering_values[IBUF_USE_COUNT] = {
"none", /* IBUF_USE_NONE */
"inserts", /* IBUF_USE_INSERT */
"deletes", /* IBUF_USE_DELETE_MARK */
"changes", /* IBUF_USE_INSERT_DELETE_MARK */
"purges", /* IBUF_USE_DELETE */
"all" /* IBUF_USE_ALL */
};innodb_change_buffering默认值为all,表示缓存所有操作。注意由于在二级索引上的更新操作总是先delete-mark,再insert新记录,因此update会产生两条Ibuf entry。
缓存条件
只有满足一定条件时,操作才会被缓存,所有对ibuf操作的判断,都从btr_cur_search_to_nth_level入口,该函数用于定位到btree上满足条件的记录,大概的判断条件如下:
- 用户设置了选项innodb_change_buffering;
- 只有叶子节点才会去考虑是否使用ibuf;
- 对于聚集索引,不可以缓存操作;
- 对于唯一二级索引(unique key),由于索引记录具有唯一性,因此无法缓存插入操作,但可以缓存删除操作;
- 表上没有flush 操作,例如执行flush table for export时,不允许对表进行ibuf 缓存 (通过
dict_table_t::quiesce进行标识)
参考函数:ibuf_should_try
当满足ibuf缓存条件时,会使用两种模式去尝试获取数据页:
BUF_GET_IF_IN_POOL: 如果数据页在内存中,则获取page并返回,否则返回NULL;
BUF_GET_IF_IN_POOL_OR_WATCH:如果数据页在内存中,则获取page并返回,否则为请求的page设置一个`sentinel`(buf_pool_watch_set),相当于标记这个page,表示这个page上的记录正在被purge。(下一小节介绍)
前者是前台用户线程触发,后者为Purge线程在物理清除无效数据时触发。如果数据已经在内存中了,则不进行缓存。
随后进入函数ibuf_insert, 经过一系列的检查后(不可产生空page 和 索引分裂、未超出最大ibuf size限制)执行操作缓存。
Purge操作缓存
对于Purge操作,当page不存在于内存时设置的sentinel是什么鬼? 它是如何设置的,什么时候会被清理掉,这几个问题涉及到Purge操作的缓存流程:
- 如何设置sentinel
当Purge线程尝试读入page时,若数据页不在buffer pool中,则调用函数buf_pool_watch_set,分为两步:
Step 1. 首先检查page hash,如果存在于page hash中:1. 若未被设置成`sentinel` (别的线程将数据页读入内存时会清理掉对应标记),返回数据页;2. 否则返回NULL;
Step 2. 若page hash中不存在,则从buf_pool_t::watch数组中找到一个空闲的(状态为BUF_BLOCK_POOL_WATCH)page控制结构体对象buf_page_t,将其状态设置为BUF_BLOCK_ZIP_PAGE,初始化相关变量,并插入到page hash中。buf_pool_t::watch数组的大小为purge线程的个数,这意味着即使所有purge线程同时访问同一个buffer pool instance,总会拥有一个空闲的watch数组对象。
- 判断是否可以缓存Purge操作
当设置sentinel并返回后,在决定缓存purge之前,需要去判断是否有别的线程对同一条记录缓存了新的操作,举个简单的例子:
Step 1: delete-mark X (sec index), session 1
Step 2: insert X (clust index), session 1
Step 3: delete X(sec index), Purge thread
Step 4: insert X (sec index), session 1
如果二级索引页在内存中,那么step 3 和Step4必然是有序的,因为需要获取block锁才能进行数据变更操作。但数据页不在内存时,就需要确保Step 4在Step 3之后执行。因此在缓存purge操作之前,需要根据当前要清理的记录,找到对应的聚集索引记录,并检查相比当前Purge线程的readview是否有新版本的聚集索引记录(即有新的插入操作发生)。
如果检查到有新的插入,则本次purge操作直接放弃。因为当符合一定条件时,Step 4的操作可以直接把Step1产生的记录删除标记清除掉,重用物理空间。
参考函数:row_purge_poss_sec
但是注意上述检查流程结束时,会在函数row_purge_poss_sec中将mtr提交掉,对应的聚集索引页的Latch会被释放掉,这意味着可能出现如下序列:
Step 1: delete-mark X;
Step 2: delete X,Purge线程为其设置watch,并完成在函数row_purge_poss_sec中的检查,准备插入ibuf
Step 3: insert X,索引页不在内存,准备插入Ibuf
在函数ibuf_insert中,针对IBUF_OP_INSERT和IBUF_OP_DELETE_MARK操作,会去检查是否对应的二级索引页被设置成‘sentinel’ (buf_page_get_also_watch),如果是的话,表明当前有一个pending的purge操作,目前的处理逻辑是放弃insert和delete-mark的缓存操作,转而读取物理页。
综上,如果purge操作先进入ibuf_insert,则对应二级索引页的watch必然被设置,insert操作将放弃缓存,转而尝试读入索引页;如果insert先进入ibuf_insert,则Purge操作的缓存放弃。
即使Purge线程完成一系列检查,进入缓存阶段,这时候用户线程依旧可能会去读入物理页;有没有可能导致purge操作丢失呢 ?答案是否定的! 因为Purge线程在缓存操作时先将cursor定位到ibuf btree上,对应的ibuf page已将加上latch;而用户线程如果读入物理页,为了Merge ibuf entry,也需要请求page latch; 当Purge线程在拿到latch后,会再检查一次看看物理页是否已读入内存(buf_pool_watch_occurred),如果是的话,则放弃本次缓存。
- 何时清理sentinel
有两种情况会清理sentinel:
第一种情况是Purge操作完成缓存后(或者判断无法进行Purge缓存)进行清理。
第二种情况是从磁盘读入文件块的时候,会调用buf_page_init_for_read->buf_page_init初始化一个page对象。这时候会做一个判断,如果将被读入的page被设置为sentinel(在watch数组中被设置),则调用buf_pool_watch_remove将其从page hash中移除,对应bp->watch的数据元素被重置成空闲状态。
ibuf merge
有以下几种场景会触发ibuf merge操作:
- 用户线程选择二级索引进行数据查询,这时候必须要读入二级索引页,相应的ibuf entry需要merge到Page中。
- 当尝试缓存插入操作时,如果预估Page的空间不足,可能导致索引分裂,则定位到尝试缓存的page no在ibuf btree中的位置,最多Merge 8个(IBUF_MERGE_AREA) page, merge方式为异步,即发起异步读索引页请求。
参考函数:ibuf_insert_low —> ibuf_get_merge_page_nos_func
- 若当前ibuf tree size 超过ibuf->max_size + 10(
IBUF_CONTRACT_DO_NOT_INSERT)时,执行一次同步的ibuf merge(ibuf_contract),merge的page no为随机定位的cursor,最多一次merge 8个page, 同时放弃本次缓存。
其中ibuf->max_size默认为25% * buffer pool size,百分比由参数innodb_change_buffer_max_size控制,可动态调整。
参考函数:ibuf_insert_low —> ibuf_contract
-
若本次插入ibuf操作可能产生ibuf btree索引分裂(BTR_MODIFY_TREE)时
当前ibuf->size < ibuf->max_size, 不做处理; 当前ibuf->size >= ibuf->max_size + 5 (IBUF_CONTRACT_ON_INSERT_SYNC)时,执行一次同步ibuf merge,位置随机; 当前Ibuf->size介于ibuf->max_size 和ibuf->max_size +5 之间时。执行一次异步ibuf merge,位置随机。
参考函数:ibuf_insert_low —> ibuf_contract_after_insert
- 后台master线程发起merge
master线程有三种工作状态:
IDLE:实例处于空闲状态,以100%的io capacity来作merge操作:
n_pages = PCT_IO(100);相当于一次merge的page数等于innodb_io_capacity
参考函数:srv_master_do_idle_tasks
ACTIVE:实例处于活跃状态,这时候会以如下算法计算需要merge的page数:
/* By default we do a batch of 5% of the io_capacity */
n_pages = PCT_IO(5);
mutex_enter(&ibuf_mutex);
/* If the ibuf->size is more than half the max_size
then we make more agreesive contraction.
+1 is to avoid division by zero. */
if (ibuf->size > ibuf->max_size / 2) {
ulint diff = ibuf->size - ibuf->max_size / 2;
n_pages += PCT_IO((diff * 100)
/ (ibuf->max_size + 1));
}
mutex_exit(&ibuf_mutex);可见在系统active时,会以比较温和的方式去做merge,如果当前ibuf btree size超过最大值的一半,则尝试多做一些merge操作。
参考函数: srv_master_do_active_tasks
SHUTDOWN:当执行slow shutdown时,会强制做一次全部的ibuf merge
参考函数:srv_master_do_shutdown_tasks
- 对某个表执行flush table 操作时,会触发对该表的强制ibuf merge,例如执行:
flush table tbname for export;
flush table tbname with read lock;
实际上强制ibuf merge主要是为flush for export准备的,当执行该命令后,为了保证能安全的将ibd拷贝到其他实例上, 需要对该表应用全部的ibuf 缓存。
参考函数:row_quiesce_table_start
“著名” bug
在change buffer的应用史上,最著名的bug要属 bug#61104,其现象为当实例意外crash后,无法从崩溃中恢复,错误日志中报如下断言:
InnoDB: Failing assertion: page_get_n_recs(page) > 1
最初官方花了很长的时间都没有找到这个问题的root cause,只能加了一些代码逻辑避免不断crash重启,让用户有机会登录实例,重建二级索引。
后来Percona的开发人员Alexey Kopytov在bug#66819 提出了该问题的根本原因,指出ibuf entry的删除和merge 并不是一个原子的操作(即处于两个mtr事务中),当merge ibuf的mtr提交后crash,就可能在重启时重复做ibuf merge。如果上次执行DELETE操作导致对应索引页上记录数只剩下一条;第二次apply时认为本次操作会产生空页,从而导致断言错误。
官方很快根据Alexey的意见做了修复,修复方式也比较简单:
在第一个mtr里,merge ibuf entry 到二级索引页,并标记删除ibuf entry,提交mtr;
在第二个mtr里,执行真正的悲观删除ibuf entry;
在执行merge操作前,对于被delete mark的ibuf entry,不做merge操作。
具体的参考函数:ibuf_merge_or_delete_for_page 和 ibuf_delete_rec
比较乌龙的是,我们发现第一次修复并没有处理Purge线程产生的delete缓存;我们将该发现公布到社区,很快得到了响应,并由上游快速fix掉了,因此完整的补丁分布在两个版本中: