2.28 端到端神经机器翻译
端 到 端 神 经 机 器 翻 译(End-to-End NeuralMachine Translation)是从 2013 年兴起的一种全新机器翻译方法,其基本思想是使用神经网络直接将源语言文本映射成目标语言文本。与统计机器翻译不同,不再有人工设计的词语对齐、短语切分、句法树等隐结构(latent structure),不再需要人工设计特征,端到端神经机器翻译仅使用一个非线性的神经网络便能直接实现自然语言文本的转换。
英 国 牛 津 大 学 的 Nal Kalchbrenner 和 PhilBlunsom 于 2013 年首先提出了端到端神经机器翻译[10] 。他们为机器翻译提出一个“编码 - 解码”的新框架:给定一个源语言句子,首先使用一个编码器将其映射为一个连续、稠密的向量,然后再使用一个解码器将该向量转化为一个目标语言句子。Kalchbrenner 和 Blunsom 在论文中所使用的编码器是卷积神经网络(Convolutional NeuralNetwork),解码器是递归神经网络(RecurrentNeural Network)。使用递归神经网络具有能够捕获全部历史信息和处理变长字符串的优点。这是一个非常大胆的新架构,用非线性模型取代统计机器翻译的线性模型;用单个复杂的神经网络取代隐结构流水线;用连接编码器和解码器的向量来描述语义等价性;用递归神经网络捕获无限长的历史信息。然而,端到端神经机器翻译最初并没有获得理想的翻译性能,一个重要原因是训练递归神经网络时面临着“梯度消失”和“梯度爆炸”问题。因此,虽然递归神经网络理论上能捕获无限长的历史信息,但实际上难以真正处理长距离的依赖关系。
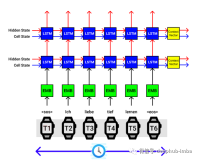
为此,美国 Google 公司的 Ilya Sutskever 等人 于 2014 年 将 长 短 期 记 忆(Long Short-TermMemory) [11] 引入端到端神经机器翻译[12] 。长短期记忆通过采用设置门开关(gate)的方法解决了训练递归神经网络时的“梯度消失”和“梯度爆炸”问题,能够较好地捕获长距离依赖。图 2 给出了Sutskever 等人提出的架构。与 Kalchbrenner 和Blunsom 的工作不同,无论是编码器还是解码器,Sutskever 等人都采用了递归神经网络。给定一个源语言句子“A B C”,该模型在尾部增加了一个表示句子结束的符号“〈EOS〉”。当编码器为整个句子生成向量表示后,解码器便开始生成目标语言句子,整个解码过程直到生成“〈EOS〉”时结束。需要注意的是,当生成目标语言词“X”时,解码器不但考虑整个源语言句子的信息,还考虑已经生成的部分译文(即“W”)。由于引入了长短期记忆,端到端神经机器翻译的性能获得了大幅度提升,取得了与传统统计机器翻译相当甚至更好的准确率。然而,这种新的框架仍面临一个重要的挑战,即不管是较长的源语言句子,还是较短的源语言句子,编码器都需将其映射成一个维度固定的向量,这对实现准确的编码提出了极大的挑战。
针对编码器生成定长向量的问题,YoshuaBengio 研究组提出了基于注意力(attention)的端到端神经网络翻译[13] 。所谓注意力,是指当解码器在生成单个目标语言词时,仅有小部分的源语言词是相关的,绝大多数源语言词都是无关的。例如,在图 2 中,当生成目标语言词“money”时,实际上只有“钱”是与之密切相关的,其余的源语言词都不相关。因此,Bengio 研究组主张为每个目标语言词动态生成源语言端的上下文向量,而不是采用表示整个源语言句子的定长向量。为此,他们提出了一套基于内容(content-based)的注意力计算方法。实验表明,注意力的引入能够更好地处理长距离依赖,显著提升端到端神经机器翻译的性能[14] 。
虽然端到端神经机器翻译近年来获得了迅速的发展,但仍存在许多重要问题有待解决。
● 可解释性差:传统的统计机器翻译在设计模型时,往往会依据语言学理论设计隐结构和特征。端到端神经网络翻译重在设计神经网络架构。但是由于神经网络内部全部是向量,从语言学的角度来看可解释性很差,如何根据语言学知识设计新架构成为挑战,系统调试也困难重重。
● 训练复杂度高:端到端神经机器翻译的训练复杂度与传统统计机器翻译相比具有数量级上的提升,必须使用较大规模的 GPU 集群才能获得较理想的实验周期。因此,计算资源成为开展端到端神经机器翻译研究的最大门槛。