一个BI系统为了满足企业管理者的要求,从浩如烟海的资料中找出其关心的数据,必须要做到以下几步:
1)为了整合各种格式的数据,清除原有数据中的错误记录——数据预处理的要求。
2)对预处理过数据,应该统一集中起来——元数据(Meta Data)、数据仓库(Data Warehouse)的要求;
3)最后,对于集中起来的庞大的数据集,还应进行相应的专业统计,从中发掘出对企业决策有价值的新的机会——OLAP(联机事务分析)和数据挖掘(Data Mining)的要求。
所以,一个典型的BI体系架构应该包含这3步所涉及的相关要求。
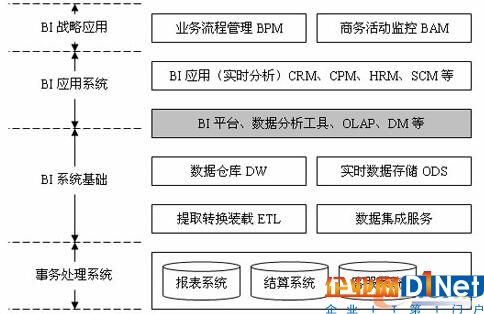
图1 BI的体系架构
整个体系架构中包括:终端用户查询和报告工具、OLAP工具、数据挖掘(Data Mining)软件、数据仓库(Data Warehouse)和数据集市(Data Mart)产品、联机分析处理(OLAP)等工具。
1)终端用户查询和报告工具。
专门用来支持初级用户的原始数据访问,不包括适应于专业人士的成品报告生成工具。
2)数据预处理(STL-数据抽取、转换、装载)
从许多来自不同的企业运作系统的数据中提取出有用的数据并进行清理,以保证数据的正确性,然后经过抽取(Extraction)、转换(Transformation)和装载(Load),即ETL过程,合并到一个企业级的数据仓库里,从而得到企业数据的一个全局视图。
3)OLAP工具。
提供多维数据管理环境,其典型的应用是对商业问题的建模与商业数据分析。OLAP也被称为多维分析。
4)数据挖掘(Data Mining)软件。
使用诸如神经网络、规则归纳等技术,用来发现数据之间的关系,做出基于数据的推断。
5)数据仓库(Data Warehouse)和数据集市(Data Mart)产品。
包括数据转换、管理和存取等方面的预配置软件,通常还包括一些业务模型,如财务分析模型。
6)联机分析处理(OLAP)。
OLAP是使分析人员、管理人员或执行人员能够从多角度对信息进行快速、一致、交互地存取,从而获得对数据的更深入了解的一类软件技术。
其中核心技术在于数据预处理、数据仓库的建立(DW)、数据挖掘(DM)和联机分析处理(OLAP)三个部分。接下来,我们对这几个核心部分进行详细说明:
当早期大型的在线事务处理系统(OLTP)问世后不久,就出现了一种用于“抽取”处理的简单程序,其作用是搜索整个文件和数据库,使用某些标准选择合乎要求的数据,将其复制拷贝出来,用于总体分析。因为这样做不会影响正在使用的在线事务处理系统,降低其性能,同时,用户可以自行控制抽取出来的数据。但是,现在情况发生了巨大的变化,企业同时采用了多个在线事务处理系统,而这些系统之间的数据定义格式不尽相同,即使采用同一软件厂商提供的不同软件产品,或者仅仅是产品版本不同,之间的数据定义格式也有少许差距。由此,我们必须先定义一个统一的数据格式,然后把各个来源的数据按新的统一的格式进行转换,然后集中装载入数据仓库中。
其中,尤其要注意的一点时,并不是各个来源的不同格式的所有数据都能被新的统一格式包容,我们也不应强求非要把所有数据源的数据全部集中起来。Why?原因很多。有可能原来录入的数据中,少量的记录使用了错误的数据,这类数据如果无法校正,应该被舍去。某些数据记录是非结构化的,很难将其转化成新定义的统一格式,而且从中抽取信息必须读取整个文件,效率极低,如大容量的二进制数据文件,多媒体文件等,这类数据如果对企业决策不大,可以舍去。
目前已有一部分软件厂商开发出专门的ETL工具,其中包括:
Ardent DataStage
Evolutionary Technologies,Inc.(ETI)Extract
Information Powermart
Sagent Solution
SAS Institute
Oracle Warehouse Builder
MSSQL Server2000 DTS
数据仓库
数据仓库概念是由号称“数据仓库之父”William H.Inmon在上世纪80年代中期撰写的《建立数据仓库》一书中首次提出,“数据仓库是一个面向主题的、集成的、非易失性的,随时间变化的用来支持管理人员决策的数据集合”。
面向主题是数据仓库第一个显著特点,就是指在数据仓库中,数据按照不同的主题进行组织,每一个主题中的数据都是从各操作数据库中抽取出来汇集而成,这些与该主题相关的所有历史数据就形成了相应的主题域。
数据仓库的第二个显著特点是集成。数据来源于不同的数据源,通过相应的规则进行一致性转换,最终集成为一体。
数据仓库的第三个特点是非易失性。一旦数据被加载到数据仓库中,数据的值不会再发生变化,尽管运行系统中对数据进行增、删、改等操作,但对这些数据的操作将会作为新的快照记录到数据仓库中,从而不会影响到已经进入到数据仓库的数据。
数据仓库最后一个特点是它随时间变化。数据仓库中每一个数据都是在特定时间的记录,每个记录都有着相应的时间戳。
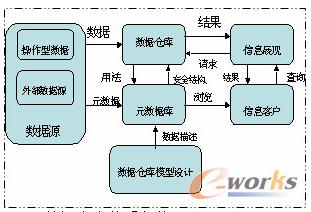
图2 数据仓库体系架构
数据仓库对外部数据源和操作型数据源的元数据,按照数据仓库模式设计要求进行归类,并建成元数据库,相对应的数据经过ETL后加载到数据仓库中;当信息客户需要查询数据时先通过信息展现系统了解元数据或者直接浏览元数据库,再发起数据查询请求得到所需数据。
一个典型的企业数据仓库系统,通常包含数据源、数据存储与管理、数据的访问三个部分。
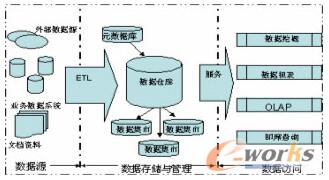
图3 数据仓库系统
数据源:是指企业操作型数据库中的各种生产运营数据、办公管理数据等内部数据和一些调查数据、市场信息等来自外环境的数据总称。这些数据是构建数据仓库系统的基础是整个系统的数据源泉。
数据的存储与管理:数据仓库的存储主要由元数据的存储及数据的存储两部分组成。元数据是关于数据的数据,其内容主要包括数据仓库的数据字典、数据的定义、数据的抽取规则、数据的转换规则、数据加载频率等信息。各操作数据库中的数据按照元数据库中定义的规则,经过抽取、清理、转换、集成,按照主题重新组织,依照相应的存储结构进行存储。也可以面向应用建立一些数据集市,数据集市可以看作是数据仓库的一个子集,它含有较少的主题域且历史时间更短数据量更少,一般只能为某个局部范围内的管理人员服务,因此也称之为部门级数据仓库。
数据的访问:由OLAP(联机分析处理)、数据挖掘、统计报表、即席查询等几部分组成。例如OLAP:针对特定的分析主题,设计多种可能的观察形式,设计相应的分析主题结构(即进行事实表和维表的设计),使管理决策人员在多维数据模型的基础上进行快速、稳定和交互性的访问,并进行各种复杂的分析和预测工作。按照存储方式来分,OLAP可以分成MOLAP以及ROLAP等方式,MOLAP(Multi-Dimension OLAP)将OLAP分析所需的数据存放在多维数据库中。分析主题的数据可以形成一个或多个多维立方体。ROLAP(Relational OLAP)将OLAP分析所需的数据存放在关系型数据库中。分析主题的数据以“事实表-维表”的星型模式组织。
数据挖掘的定义非常模糊,对它的定义取决于定义者的观点和背景。如下是一些DM文献中的定义:
数据挖掘是一个确定数据中有效的,新的,可能有用的并且最终能被理解的模式的重要过程。
数据挖掘是一个从大型数据库中提取以前未知的,可理解的,可执行的信息并用它来进行关键的商业决策的过程。
数据挖掘是用在知识发现过程,来辩识存在于数据中的未知关系和模式的一些方法。数据挖掘是发现数据中有益模式的过程。
数据挖掘是我们为那些未知的信息模式而研究大型数据集的一个决策支持过程。
虽然数据挖掘的这些定义有点不可触摸,但在目前它已经成为一种商业事业。如同在过去的历次淘金热中一样,目标是`开发矿工`。利润最大的是卖工具给矿工,而不是干实际的开发。
目前业内已有很多成熟的数据挖掘方法论,为实际应用提供了理想的指导模型。其中,标准化的主要有三个:CRISP-DM;PMML;OLE DB for DM。
CRISP-DM(Cross-Industry Standard Process for Data Mining)是目前公认的、较有影响的方法论之一。CRISP-DM强调,DM不单是数据的组织或者呈现,也不仅是数据分析和统计建模,而是一个从理解业务需求、寻求解决方案到接受实践检验的完整过程。CRISP-DM将整个挖掘过程分为以下六个阶段:商业理解(Business Understanding),数据理解(Data Understanding),数据准备(Data Preparation),建模(Modeling),评估(Evaluation)和发布(Deployment)。其框架图如下:
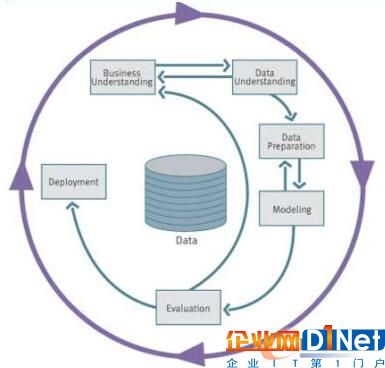
图4 CRISP-DM模型框架图
从技术层来看,数据挖掘技术可分为描述型数据挖掘和预测型数据挖掘两种。描述型数据挖掘包括数据总结、聚类及关联分析等。预测型数据挖掘包括分类、回归及时间序列分析等。
1.数据总结:继承于数据分析中的统计分析。数据总结目的是对数据进行浓缩,给出它的紧凑描述。传统统计方法如求和值、平均值、方差值等都是有效方法。另外还可以用直方图、饼状图等图形方式表示这些值。广义上讲,多维分析也可以归入这一类。
2.聚类:是把整个数据库分成不同的群组。它的目的是使群与群之间差别很明显,而同一个群之间的数据尽量相似。这种方法通常用于客户细分。在开始细分之前不知道要把用户分成几类,因此通过聚类分析可以找出客户特性相似的群体,如客户消费特性相似或年龄特性相似等。在此基础上可以制定一些针对不同客户群体的营销方案。
3.关联分析:是寻找数据库中值的相关性。两种常用的技术是关联规则和序列模式。关联规则是寻找在同一个事件中出现的不同项的相关性;序列模式与此类似,寻找的是事件之间时间上的相关性,如对股票涨跌的分析等。
4.分类:目的是构造一个分类函数或分类模型(也常常称作分类器),该模型能把数据库中的数据项映射到给定类别中的某一个。要构造分类器,需要有一个训练样本数据集作为输入。训练集由一组数据库记录或元组构成,每个元组是一个由有关字段(又称属性或特征)值组成的特征向量,此外,训练样本还有一个类别标记。一个具体样本的形式可表示为:(v1,v2,...,vn;c),其中vi表示字段值,c表示类别。
5.回归:是通过具有已知值的变量来预测其它变量的值。一般情况下,回归采用的是线性回归、非线性回归这样的标准统计技术。一般同一个模型既可用于回归也可用于分类。常见的算法有逻辑回归、决策树、神经网络等。
6.时间序列:时间序列是用变量过去的值来预测未来的值。
数据挖掘(Data Mining)软件。使用诸如神经网络、规则归纳等技术,用来发现数据之间的关系,做出基于数据的推断。
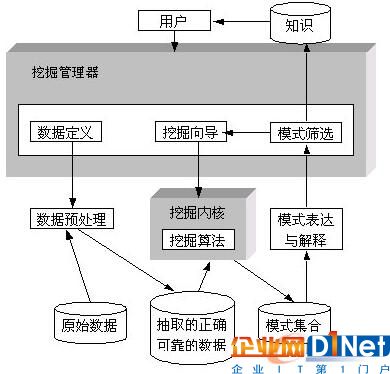
图5 数据挖掘系统
以下是一些当前的数据挖掘产品:
IBM: Intelligent Miner 智能矿工
Tandem: Relational Data Miner 关系数据矿工
AngossSoftware: KnowledgeSEEDER 知识搜索者
Thinking Machines Corporation: DarwinTM
NeoVista Software: ASIC
ISL Decision Systems,Inc.: Clementine
DataMind Corporation: DataMind Data Cruncher
Silicon Graphics: MineSet
California Scientific Software: BrainMaker
WizSoft Corporation: WizWhy
Lockheed Corporation: Recon
SAS Corporation: SAS Enterprise Miner
OLAP的概念最早是由关系数据库之父E.F.Codd于1993年提出的,他同时提出了关于OLAP的12条准则。OLAP的提出引起了很大的反响,OLAP作为一类产品同联机事务处理(OLTP)明显区分开来。
当今的数据处理大致可以分成两大类:联机事务处理OLTP(On-Line Transaction Processing)、联机分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLAP是使分析人员、管理人员或执行人员能够从多角度对信息进行快速、一致、交互地存取,从而获得对数据的更深入了解的一类软件技术。OLAP的目标是满足决策支持或者满足在多维环境下特定的查询和报表需求,它的技术核心是"维"这个概念。
“维”是人们观察客观世界的角度,是一种高层次的类型划分。“维”一般包含着层次关系,这种层次关系有时会相当复杂。通过把一个实体的多项重要的属性定义为多个维(DImension),使用户能对不同维上的数据进行比较。因此OLAP也可以说是多维数据分析工具的集合。
OLAP的基本多维分析操作有钻取(Roll Up和Drill Down)、切片(Slice)和切块(Dice)、以及旋转(Pivot)、Drill Across、Drill Through等。
钻取是改变维的层次,变换分析的粒度。它包括向上钻取(Roll Up)和向下钻取(Drill Down)。Roll Up是在某一维上将低层次的细节数据概括到高层次的汇总数据,或者减少维数;而Drill Down则相反,它从汇总数据深入到细节数据进行观察或增加新维。
切片和切块是在一部分维上选定值后,关心度量数据在剩余维上的分布。如果剩余的维只有两个,则是切片;如果有三个,则是切块。
旋转是变换维的方向,即在表格中重新安排维的放置(例如行列互换)。
OLAP有多种实现方法,根据存储数据的方式不同可以分为ROLAP、MOLAP、HOLAP。
ROLAP表示基于关系数据库的OLAP实现(Relational OLAP)。以关系数据库为核心,以关系型结构进行多维数据的表示和存储。ROLAP将多维数据库的多维结构划分为两类表:一类是事实表,用来存储数据和维关键字;另一类是维表,即对每个维至少使用一个表来存放维的层次、成员类别等维的描述信息。维表和事实表通过主关键字和外关键字联系在一起,形成了“星型模式”。对于层次复杂的维,为避免冗余数据占用过大的存储空间,可以使用多个表来描述,这种星型模式的扩展称为“雪花模式”。
MOLAP表示基于多维数据组织的OLAP实现(Multidimensional OLAP)。以多维数据组织方式为核心,也就是说,MOLAP使用多维数组存储数据。多维数据在存储中将形成“立方块(Cube)”的结构,在MOLAP中对“立方块”的“旋转”、“切块”、“切片”是产生多维数据报表的主要技术。
HOLAP表示基于混合数据组织的OLAP实现(Hybrid OLAP)。如低层是关系型的,高层是多维矩阵型的。这种方式具有更好的灵活性。
还有其他的一些实现OLAP的方法,如提供一个专用的SQL Server,对某些存储模式(如星型、雪片型)提供对SQL查询的特殊支持。
OLAP工具是针对特定问题的联机数据访问与分析。它通过多维的方式对数据进行分析、查询和报表。维是人们观察数据的特定角度。例如,一个企业在考虑产品的销售情况时,通常从时间、地区和产品的不同角度来深入观察产品的销售情况。这里的时间、地区和产品就是维。而这些维的不同组合和所考察的度量指标构成的多维数组则是OLAP分析的基础,可形式化表示为(维1,维2,……,维n,度量指标),如(地区、时间、产品、销售额)。多维分析是指对以多维形式组织起来的数据采取切片(Slice)、切块(Dice)、钻取(Drill Down和Roll Up)、旋转(Pivot)等各种分析动作,以求剖析数据,使用户能从多个角度、多侧面地观察数据库中的数据,从而深入理解包含在数据中的信息。
根据综合性数据的组织方式的不同,目前常见的OLAP主要有基于多维数据库的MOLAP及基于关系数据库的ROLAP两种。MOLAP是以多维的方式组织和存储数据,ROLAP则利用现有的关系数据库技术来模拟多维数据。在数据仓库应用中,OLAP应用一般是数据仓库应用的前端工具,同时OLAP工具还可以同数据挖掘工具、统计分析工具配合使用,增强决策分析功能。
本文转自d1net(转载)

